Quantum Search without Global Diffusion
Abstract
Quantum search is among the most important algorithms in quantum computing, offering fundamentally new approaches to optimisation and information processing. At its core is quantum amplitude amplification, a technique that achieves a quadratic speedup over classical search by combining two global reflections: the oracle, which marks the target, and the diffusion operator, which reflects about the initial state. We show that this speedup can be preserved when the oracle is the only global operator, with all other operations acting locally on non-overlapping partitions of the search register. We present a recursive construction that, when the initial and target states both decompose as tensor products over these chosen partitions, admits an exact closed-form solution for the algorithm's dynamics. This is enabled by an intriguing degeneracy in the principal angles between successive reflections, which collapse to just two distinct values governed by a single recursively defined angle. Applied to unstructured search, a problem that naturally satisfies the tensor decomposition, the approach retains the O(√N) oracle complexity of Grover search when each partition contains at least log₂(log₂ N) qubits. On an 18-qubit search problem, partitioning into two stages reduces the non-oracle circuit depth by as much as 51%–96% relative to Grover, requiring up to 9% additional oracle calls.
Executive summary
Burke & Mc Goldrick prove that the global diffusion operator in Grover-style amplitude amplification is not actually necessary: a recursive construction built from local diffusion reflections (each acting on one of m partitions of the search register) achieves the same O(√N) quadratic speedup, with the oracle as the only global operator. The key technical surprise is a degeneracy: although intermediate operators act on subspaces of dimension 2^(i-1), the principal angles between successive reflections collapse to just two values driven by a single recursively defined angle γ_i. For Yuan, this is directly germane to Y4 (Grover-based cardinality-constrained optimisation): the partial-diffusion + recursion machinery may be a drop-in depth optimisation for the rotation step in Y4's O(√(C(n,k)/M)) algorithm, especially under heavy-hex IBM-style topologies where global reflections are expensive.
Main contribution
The paper introduces a recursive reflection operator W_i = (S_ψ_i W_{i-1})^{t_i} S_ψ_i (W_{i-1} S_ψ_i)^{t_i} with W_0 = S_x (the oracle), where each S_ψ_i is a local reflection on register i obtained by conjugating the |0⟩ reflection on that register by A_i. Whenever the state-preparation unitary A = ⊗A_i and target |x⟩ = ⊗|x_i⟩ both decompose tensor-product-wise over the partition, the dynamics admit a closed-form recursion sin(2γ_i) = sin(2θ_i) sin(2t_{i-1} γ_{i-1}) with γ_1 = θ_1 and sin(θ_i) = |⟨x_i|ψ_i⟩|. The success probability at stage m is the boxed expression P(x_m) = ½[1 − cos(2θ_m)/cos(2γ_m) · cos(2(2t_m+1)γ_m)] with optimal iteration count t_m* = ⌊π/(4γ_m) − ½⌉. The total oracle complexity is bounded by C_total ≤ C_Grover^(n) / ∏cos(θ_i) × 1/(1 − 2^{1−s/2}), and reduces to the asymptotically optimal O(√N) whenever the per-stage size s ≥ log₂(log₂ N).
Key theorems / lemmas / algorithms
- Degeneracy claim (Eq. 8–10): the principal angles between the reflected eigenspaces of S_ψ_i and W_{i-1} collapse to just two values, γ_i and π/2 − γ_i, regardless of the 2^{i-1}-dimensional ambient subspace.
- Inductive proof of state-independence (Sec 3.2): by induction, the projection norms ‖P_ψ_i (S_ψ_i W_{i-1})^{t_i} |ψ_i, φ_{i-1}⟩‖² = cos²(2t_i γ_i) are independent of φ_{i-1} ∈ S_{i-1}. The key sub-step is that the diagonal blocks of Q_{i-1} collapse to scalar multiples of the identity (Eqs. 23 and 27).
- Closed-form success probability (Eq. 47): the per-stage success probability boxed equation above, with explicit optimal iteration count.
- Geometric-series cost bound (Sec. 3.5): the recursive oracle cost for unstructured search is bounded above by C_Grover^(n) × geometric-series factor, giving asymptotic O(√N) for s ≥ log₂(log₂ N).
- Algorithm: apply (S_ψ_m W_{m-1})^{t_m} to amplify amplitude on register m, measure registers 1..m−1, reinitialise them, repeat on shrinking subspaces until the full target is recovered.
Detailed walkthrough
The construction starts from a simple observation: standard Grover combines two global reflections — the oracle S_x and the global diffusion S_ψ = A(I − 2|0⟩⟨0|)A†. The latter is the practical bottleneck on hardware because its multi-controlled X gate has depth scaling with the number of qubits. The authors ask whether the diffusion can be made local without losing the quadratic speedup, and show that yes — under tensor-product structure of A and |x⟩.
The partial diffusion operator S_ψ_i = A_i(I_n_i − 2|0_i⟩⟨0_i|)A_i† acts only on register i, extended by identity on the rest. The recursive W_i sandwiches S_ψ_i between t_i iterations of (S_ψ_i W_{i-1}) and (W_{i-1} S_ψ_i), so each W_i is itself a reflection. The remarkable algebraic fact (Sec. 3.2) is that the principal angles between the eigenspaces of S_ψ_i and W_{i-1} reduce to a scalar 2×2 problem at every level. This is enabled by two ingredients: (1) the inductive hypothesis forces the diagonal blocks P_ψ Q_{i-1} P_ψ and P_ψ⊥ Q_{i-1} P_ψ⊥ to be scalar multiples of the identity (because constant-output-norm scaled-isometries on equal-dimensional spaces are scaled unitaries); (2) the off-diagonal block CC† is also a scalar multiple of the identity, derived from the projector identity Q_{i-1}^2 = Q_{i-1}. The resulting 2×2 hermitian operator T has eigenvalues cos²(γ_i) and sin²(γ_i) with the recursion sin(2γ_i) = sin(2θ_i) sin(2t_{i-1}γ_{i-1}).
The success-probability closed form (Sec. 3.3) is obtained by carefully evaluating the cross term Re[⟨ψ_m|v⟩⟨v|ψ_m⊥⟩] using the diagonalised eigenvector of T and the relation sin(ξ − φ) = −sin(φ)cos(2θ_m)/cos(2γ_m). The result P(x_m) = ½[1 − cos(2θ_m)/cos(2γ_m) · cos(2(2t_m+1)γ_m)] with t_m* = ⌊π/(4γ_m) − ½⌉ generalises the standard Grover success formula. After measuring register m, the algorithm restarts on the remaining m−1 registers with a smaller effective search space, and the total cost is dominated by the first stage. The overall success probability ∏cos²(θ_i) is then boosted close to unity by adjusting the penultimate iterate t_{m-1} (Sec. 3.5).
For unstructured search with partition size s = n/m, the per-stage overlap is θ_i = arcsin(2^{-s/2}). The per-stage oracle overhead 1/∏cos(θ_i) is bounded by exp(log₂(N)/(s · 2^{s+1})), which converges to 1 for s ≥ log₂(log₂ N). The geometric series of subsequent rounds converges to 1/(1 − 2^{1−s/2}); ≤ 3.41 for s=3, = 2 for s=4, and < 1.15 for s ≥ 6. Thus, asymptotic optimality holds whenever each partition has at least log₂(log₂ N) qubits.
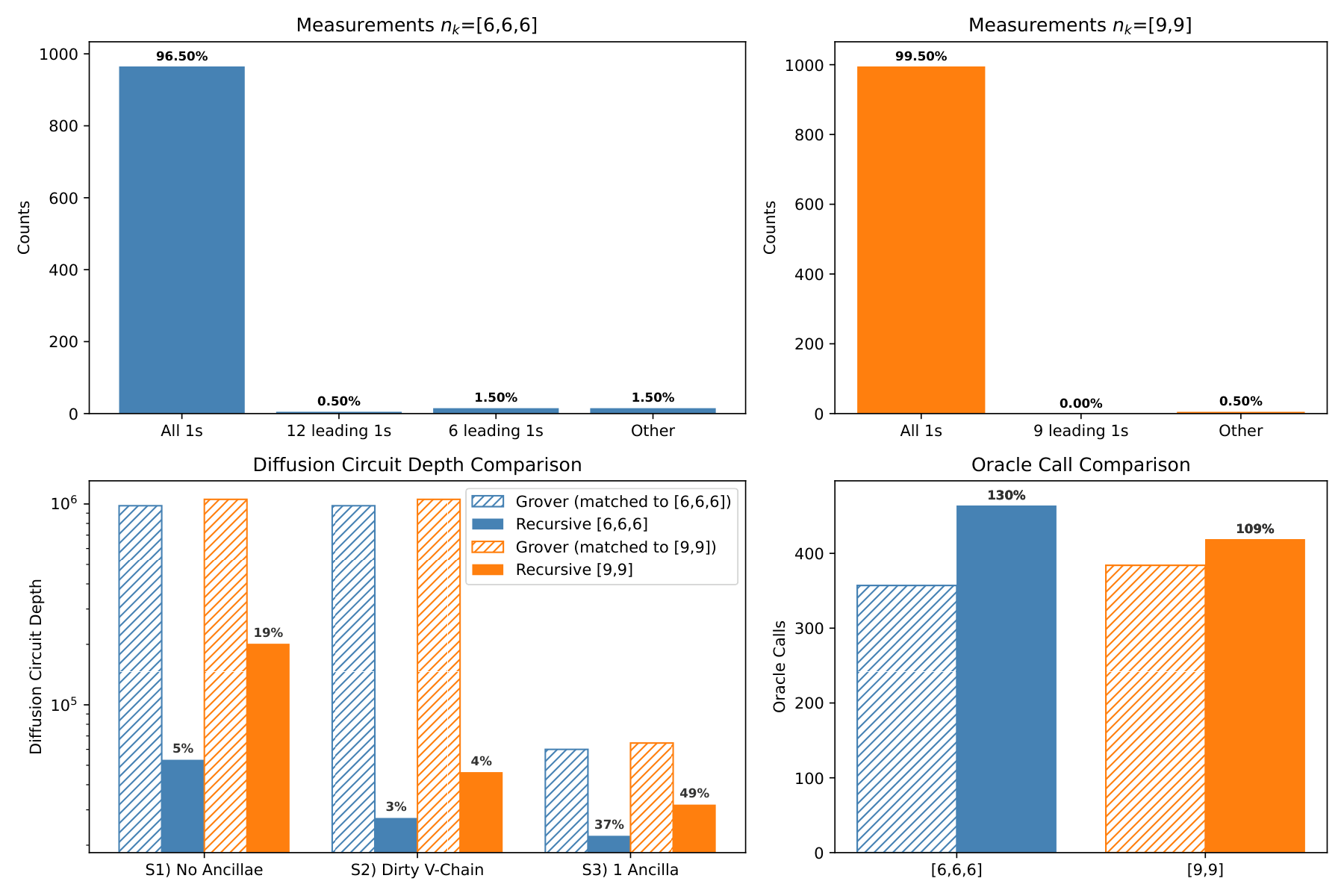
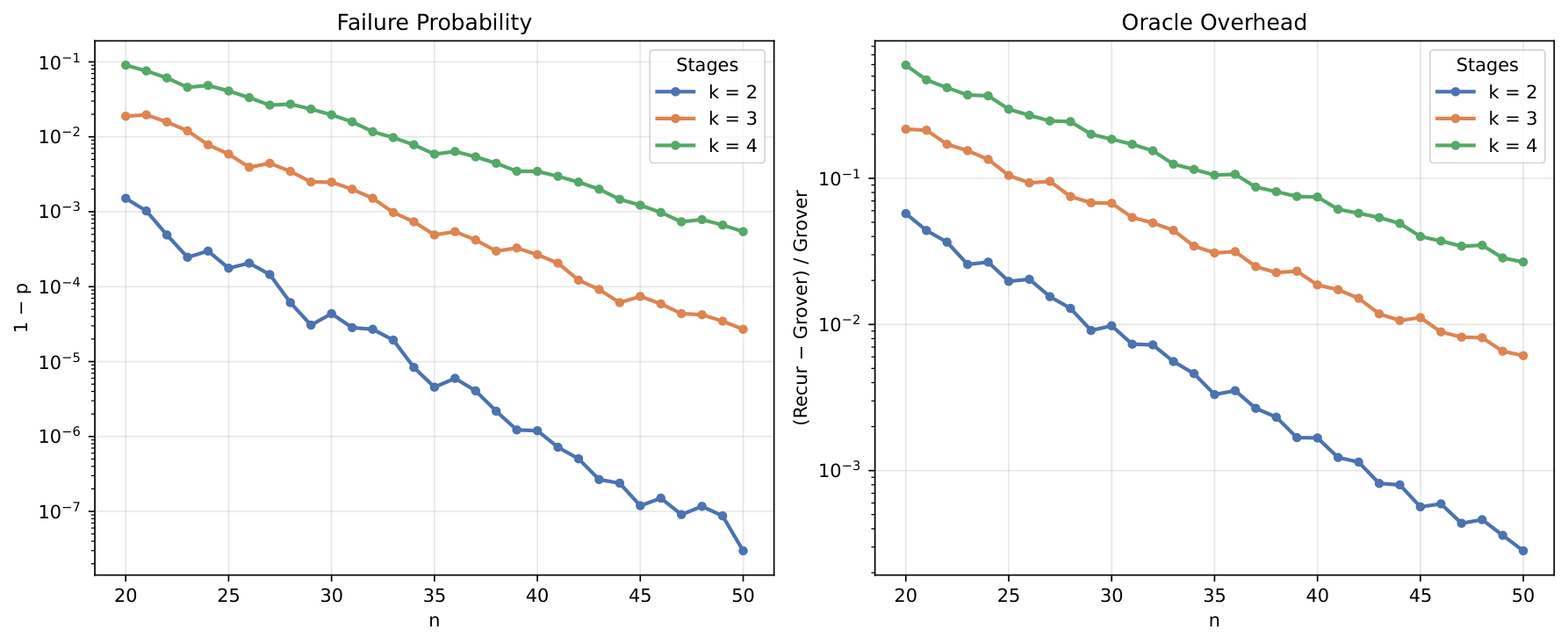
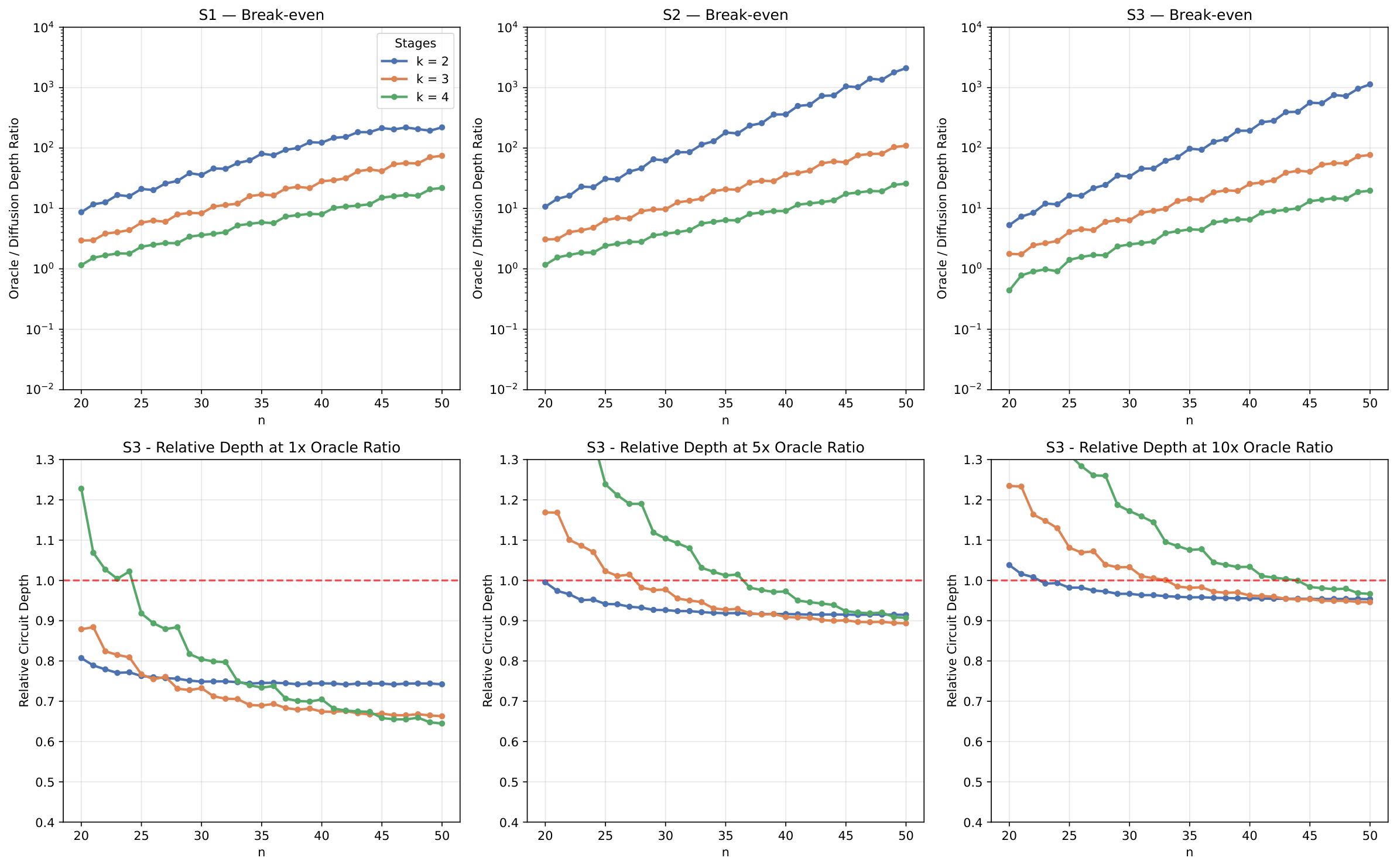
The evaluation section (Sec. 4) reports a Qiskit simulation on an 18-qubit unstructured search for the all-ones target. A 3-stage [6,6,6] configuration uses (102, 25, 6) iterations and achieves 96.5% success vs. a theoretical 96.7%; a 2-stage [9,9] configuration uses (201, 17) and achieves 99.5% vs. 99.8% theoretical. Three multi-controlled-X decomposition scenarios are compared: S1 (no ancillae), S2 (dirty V-chain using idle qubits as dirty ancillae), S3 (one clean ancilla). Under S2, the 3-stage config reduces diffusion-circuit depth by 97% and the 2-stage by 96% at 30% and 9% oracle overheads respectively. The scaling study extends to n ∈ [20, 50] and shows that for n=50 the 2-stage configuration has failure rate < 10^{−7} with < 0.1% oracle overhead, and break-even oracle-to-diffusion depth ratios up to ~10³ under S2.
An interesting practical anchor: the paper estimates that for AES-128 (oracle-to-diffusion depth ratio ~10×), the recursive scheme still yields ~5% depth reduction. The discussion (Sec. 5/Conclusion) suggests the construction may also enable distributed quantum search where non-oracle operations are confined to individual processors — a hardware story very compatible with where IBM/IonQ are going.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y4 (Grover + ADMM cardinality-constrained BO) — primary overlap. Y4's algorithm uses O(√(C(n,k)/M)) Grover rotations over a structured feasible space; in that setting the global diffuser is a custom Dicke-state preparation whose depth is also a bottleneck. Burke & Mc Goldrick's recursive partial-diffusion construction directly applies whenever the state preparation factorises across registers (which is the case for product warm-starts and for the unstructured case used as a benchmark in Y4). The depth reductions reported here (95%+ for S1, ~25–34% for n=50) would translate to fewer noisy gates per amplification step.
- Y1 (warm-started QAOA) — methodological resonance. The "recursive degeneracy" idea — that high-dimensional dynamics collapse to a scalar recursion when the algorithm respects a tensor structure — has the same flavour as Y1's measurement-based iterative warm-starting, where the dynamics also reduce to a controllable scalar parameter per iteration.
- Y3 (QAOA DGMVP portfolio) — secondary scope overlap. Not a method overlap, but the depth/oracle-overhead trade-off characterisation (especially the break-even oracle depth analysis) mirrors Y3's noise-regime crossover analysis: both papers turn on the question "when is a quantum approach worth running on real hardware?"
- Y2, Y5, Y6 — no meaningful overlap.
Recommended action for Yuan
- Read deeper — especially Sec. 3 (proof of degeneracy) and Sec. 4 (depth-saving regimes). The scalar 2×2 reduction is the kind of structural insight that could inspire similar reductions in Y4's analysis of the amplitude-amplification subroutine.
- Implement for comparison — the Qiskit code is publicly available (referenced as [burke2026code]). Replacing the global diffuser with the recursive local version inside Y4's Grover-based cardinality-constrained solver, especially on heavy-hex topologies, is a concrete experiment worth running.
- Cite in any near-term draft that benchmarks Y4's Grover subroutine against IBM Heron hardware — this paper is the natural reference for "we use a depth-optimised partial-diffusion variant of Grover".