Quantum Search without Global Diffusion
Abstract
Quantum search is among the most important algorithms in quantum computing, offering fundamentally new approaches to optimisation and information processing. At its core is quantum amplitude amplification, a technique that achieves a quadratic speedup over classical search by combining two global reflections: the oracle, which marks the target, and the diffusion operator, which reflects about the initial state. We show that this speedup can be preserved when the oracle is the only global operator, with all other operations acting locally on non-overlapping partitions of the search register. We present a recursive construction that, when the initial and target states both decompose as tensor products over these chosen partitions, admits an exact closed-form solution for the algorithm's dynamics. This is enabled by an intriguing degeneracy in the principal angles between successive reflections, which collapse to just two distinct values governed by a single recursively defined angle. Applied to unstructured search, a problem that naturally satisfies the tensor decomposition, the approach retains the O(√N) oracle complexity of Grover search when each partition contains at least log2(log2 N) qubits. On an 18-qubit search problem, partitioning into two stages reduces the non-oracle circuit depth by as much as 51%–96% relative to Grover, requiring up to 9% additional oracle calls. For larger problem sizes this oracle overhead rapidly diminishes, and valuable depth reductions persist when the oracle circuit is substantially deeper than the diffusion operator. More broadly, these results show that a global diffusion operator is not necessary to achieve the quadratic speedup in quantum search, offering a new perspective on this foundational algorithm.
Executive summary
Burke and Mc Goldrick eliminate the global diffusion operator from Grover-style amplitude amplification, replacing it with reflections that act entirely within tensor-product partitions of the register. The oracle remains the only operator that touches every qubit. They prove that despite the exponentially growing eigenspaces of the recursive partial-reflection product, the principal angles collapse to two values determined by a single recursively defined angle γi, yielding a closed-form success probability and an oracle overhead of 1/∏ cos(θi) over standard QAA. For Yuan, this is a direct upgrade to the Grover routine that underpins Y4 (cardinality-constrained binary optimisation via Grover): the partitioned local-diffusion construction promises significant non-oracle depth savings (51%–96% on 18 qubits, 25%–35% at n=50 when oracle and diffusion are comparable in depth) precisely the regime where Y4's amplitude-amplification rotations dominate hardware cost.
Main contribution
The paper proves that whenever the state preparation unitary A and the target |x⟩ factorise as A = ⊗Ai and |x⟩ = ⊗|xi⟩ across an m-fold partition, recursive reflection Wi = (Sψi Wi−1)ti Sψi (Wi−1 Sψi)ti built from local partial diffusers Sψi and the oracle W0 = Sx drives amplitude into one register at a time. Despite the dimension-2i−1 reflected subspaces, the principal angles between successive reflections collapse to {γi, π/2 − γi} with γi obeying sin(2γi) = sin(2θi)·sin(2ti−1γi−1). The total oracle cost is bounded by CGrover(n) / [∏cos(θi) · (1 − 21−s/2)] for equal stage size s; for s ≥ log2 log2 N the algorithm achieves the asymptotically optimal O(√N) query complexity while every non-oracle operator acts on only s qubits.
Key theorems / lemmas / algorithms
- Recursive reflection Wi (Eq. in §3.1): defines the building block from Sψi and Wi−1; itself a reflection.
- Principal-angle degeneracy: the spectrum of SψiWi−1 collapses to two angles {γi, π/2 − γi} with sin(2γi) = sin(2θi)·sin(2ti−1γi−1), γ1 = θ1 — the technical heart of the paper, reducing the dynamics to a scalar recursion.
- Closed-form per-stage success: ‖Pxm (SψmWm−1)tm|ψ⟩‖2 = ½[1 − cos(2θm)/cos(2γm) · cos(2(2tm+1)γm)], with optimal tm* = ⌊π/(4γm) − ½⌉.
- Oracle overhead bound: per-stage factor 1/∏cos(θi) ≤ exp[log2(N)/(s·2s+1)], converging to unity when partitions are at least log2log2 N qubits.
- Total-cost bound (boxed result, §3.4): Ctotal ≤ CGrover(n) / [∏cos(θi) · (1 − 21−s/2)], capturing the geometric series from re-running the search on shrinking sub-registers.
Detailed walkthrough
The classical Grover loop is a pair of global reflections: the oracle Sx marks |x⟩ and the diffusion operator Sψ = I − 2|ψ⟩⟨ψ| reflects about the prepared initial state |ψ⟩ = A|0⟩. Their product is a rotation in the 2-D plane span{|ψ⟩, |x⟩}. The authors' question: can the second global reflection be replaced entirely by operators acting within sub-registers of the search space?
The answer is yes whenever A and |x⟩ both factor as tensor products across an m-partition of the n qubits. The construction defines partial diffusers Sψi = I − 2|ψi⟩⟨ψi| ⊗ I (acting only on register i) and recursively builds Wi = (Sψi Wi−1)ti Sψi (Wi−1 Sψi)ti with base W0 = Sx. Each Wi is itself a reflection — it conjugates Sψi by the iterate (SψiWi−1)ti.
The non-trivial mathematical claim (§3.2) is that the principal angles between the eigenspaces of Sψi and Wi−1, which a priori could populate a complex spectrum of dimension 2i−1, collapse to two values {γi, π/2 − γi} controlled by a single scalar γi satisfying sin(2γi) = sin(2θi)·sin(2ti−1γi−1). This is the "scalar reduction" the authors highlight: the global recursion reduces to a 1-D angle recursion governed entirely by the local overlap angles θi = arcsin|⟨xi|ψi⟩| and the per-stage iteration counts ti. Applying (SψmWm−1)tm to |ψ⟩ concentrates amplitude in register m onto |xm⟩ with the closed-form success probability above. Measurement of the remaining registers projects register m to a pure state, after which the algorithm re-runs on a strictly smaller search space until the full target bit-string is recovered.
Section §3.5 specialises to unstructured Grover search. With equal stage size s = n/m the local overlap angle is θi = arcsin(2−s/2) and the per-stage oracle overhead 1/cos(θi) shrinks to ≤ exp[log2(N)/(s·2s+1)] — negligible once s ≥ log2log2 N. The geometric series of subsequent rounds contributes a bounded constant: 3.41× at s=3, 2× at s=4, 1.15× at s≥6. This recovers the asymptotically optimal O(√N) query complexity while every non-oracle operator acts on at most s qubits — a log2(n)-qubit local reflection rather than an n-qubit global one.
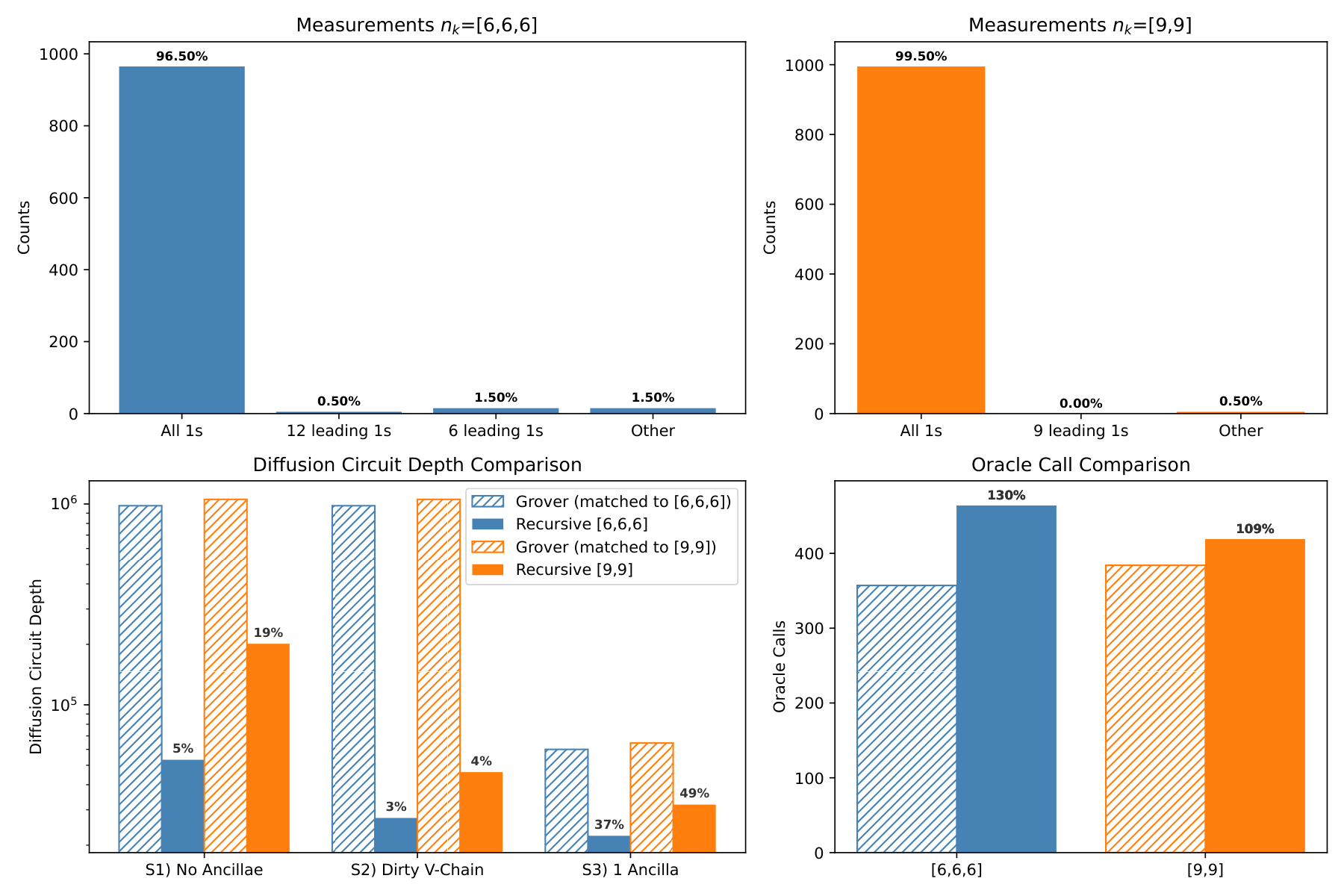
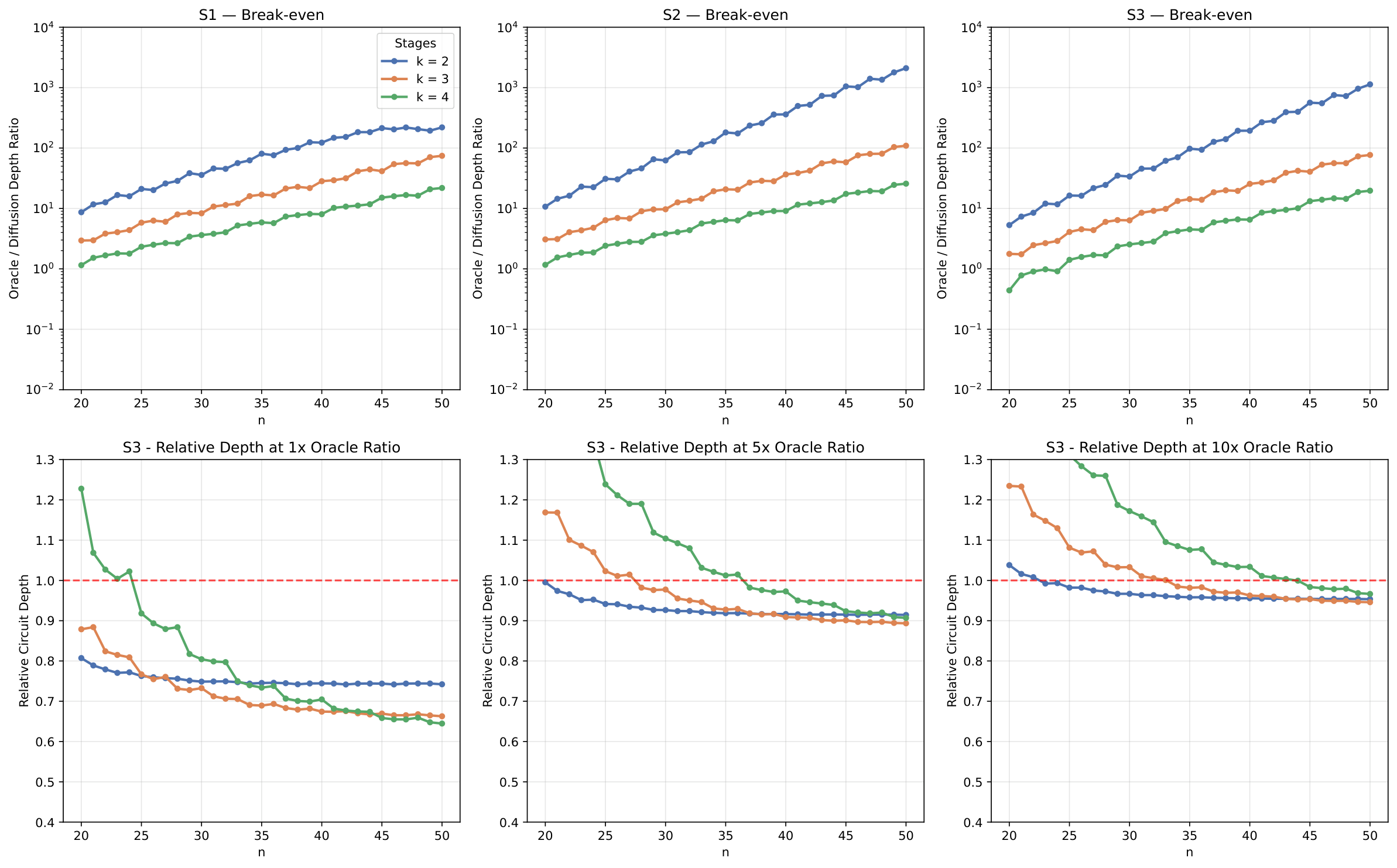
The evaluation (§4) implements the scheme in Qiskit on an 18-qubit single-target search and compares to standard Grover under three multi-controlled-X decomposition scenarios: S1 (no ancillae, strict locality), S2 (idle qubits used as dirty ancillae in a V-chain), and S3 (one clean ancilla). For the 3-stage [6,6,6] configuration with optimal iteration counts (102, 25, 6), measurement returned the target bit-string 96.5% of the time against the theoretical 96.7%; the 2-stage [9,9] configuration at (201, 17) iterations reached 99.5% (theory 99.8%). Of the 3-stage failures, 57% still produced the correct first-stage substring — useful structure when only a prefix is needed (success rises to 97.0% for the first 12 bits, 98.4% for the first 6). On non-oracle depth, S1/S2 deliver 95%/97% reductions for the 3-stage configuration at a 30% oracle overhead, and 81%/96% for the 2-stage at 9% overhead; S3 narrows these to 63%/51% reductions but still favourable. The break-even oracle-to-diffusion depth ratio is 3.1×–3.2× (S1/S2) and 1.7× (S3) for the 3-stage layout; the 2-stage variant tolerates oracles 8.8×–10.6× deeper before parity.
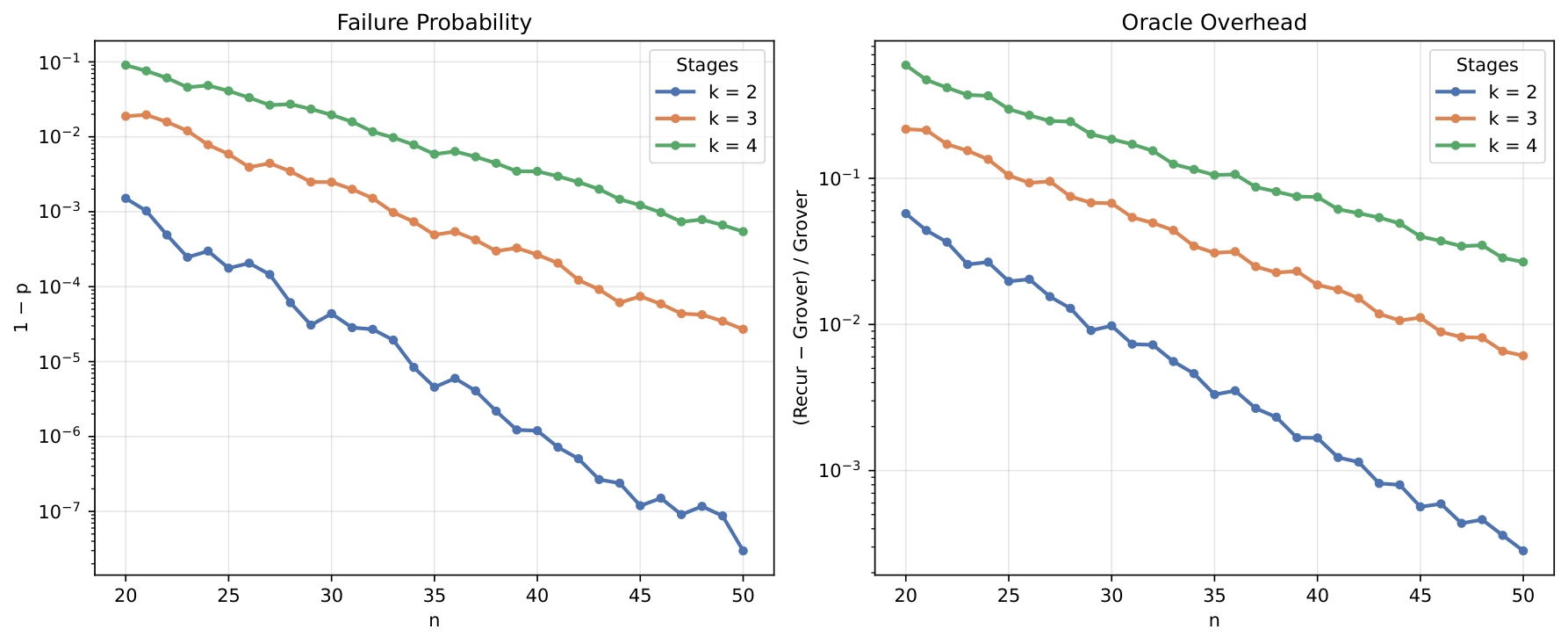
The scaling analysis (§4.2) covers n = 20–50 and confirms both the failure probability and the oracle overhead decay rapidly with n: at n = 50 the 2-stage failure rate drops below 10−7 with under 0.1% oracle overhead. With oracle depth equal to the diffusion operator at n = 50, the 2-/3-/4-stage configurations reduce total depth by 25%/34%/35%; at 5× oracle depth the configurations converge to ~10% reduction; at 10× to ~5%. As an applied example, AES-128 (oracle ≈10× diffusion) gives a ~5% depth saving.
The discussion (§5) is candid about three constraints. Mid-circuit measurements (m−1 per outer run) are noise sources but scale only with the number of stages, not √N — for a 100-qubit problem partitioned into 10 stages that is 9 measurements against 250 oracle calls. The integer-iteration rounding error can dilute success because γm ≫ θ in general; adjustable-phase variants of Sψi on the two outermost registers would suffice to deterministically eliminate it. Finally, the tensor decomposition of A is necessary for partial diffusers to exist — the technique applies cleanly to Grover, partial Grover, and any algorithm whose state-preparation factors across the register, but more entangled state preparations require approximate low-rank operator-Schmidt truncations.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y4 (Grover + ADMM for cardinality-constrained BO) — strongest overlap. Y4's quantum subroutine performs O(√(C(n,k)/M)) Grover rotations on a fixed-cardinality feasible space. Burke & Mc Goldrick give a drop-in non-oracle redesign of that loop. For Y4's hardware implementation the cardinality-constrained initial state (a Dicke state on k of n qubits) does not trivially factorise across tensor partitions, so the construction does not apply verbatim — but the approximate low-rank operator-Schmidt truncation route the authors flag (§5, "Limitations") and per-block Dicke decompositions are the natural bridge.
- Y1 (warm-started QAOA). Both share the philosophy of preserving the quadratic-speedup geometry while reshaping the operators applied between oracle/cost calls. Y1 warms the initial QAOA state from a measurement; this paper restructures the reflections around the initial state. Conceptually adjacent, methodologically distinct.
- Y2, Y3 (QAOA portfolio). Indirect — QAOA is not amplitude amplification, but the depth-reduction message ("global entanglement on every iteration is unnecessary") echoes Y3's broader theme that NISQ-era resource counts are what gate quantum advantage.
- Y5 (Gibbs-state GW relaxations). Both papers chase quantum advantage via algorithmic restructuring rather than hardware scaling. No direct method link.
- Y6 (PBR on Heron2). No overlap.
Recommended action for Yuan
- Read deeper, with Y4 in mind. The break-even and crossover plots (Figs 2–3) are directly applicable to Y4's cost model — even a 5–10% total depth reduction at n=50 is material for the resource estimates Y4 reports. Worth pulling the Qiskit reference implementation (cited as
burke2026code) and benchmarking against the cardinality-constrained Grover oracle in Y4. - Adapt the construction. Cardinality-constrained search has a Dicke-state preparation that does not factorise across partitions — but block-wise Dicke states or operator-Schmidt-truncated approximations would let Y4 inherit the local-diffuser advantage. This is a concrete follow-up paper.
- Cite, when the right Y4-extension or Y1 revision lands. If/when Y4 is updated for journal submission with NISQ-resource estimates, this paper is a natural citation for "alternatives to global diffusion in our amplitude-amplification subroutine".