Evaluating Parameter Transfer in FALQON Across Graph Families
Abstract
We evaluate FALQON parameter transfer for Max-Cut, transferring sequences from small donors (n ∈ {8,10,12}) to 14-node recipients. Using 3-regular and Erdős–Rényi families, we show that transfer success is dictated by the recipient graph, not the donor. Transfer excels for dense recipients — achieving high approximation ratios regardless of the donor — but remains challenging in sparse cross-family cases. Crucially, performance is highly resilient to donor size, with 8-node donors matching larger instances. Thus, cheap small graphs can provide robust parameters for larger targets, significantly reducing the measurement overhead of the feedback loop.
Executive summary
FALQON (Feedback-based Algorithm for Quantum Optimisation) is a measurement-driven cousin of QAOA: instead of classical outer-loop optimisation, the per-layer control gain β_k is set from the measured commutator ⟨i[H_M, H_C]⟩, guaranteeing monotone descent of the cost. The bottleneck is the measurement cost of every feedback step. This paper empirically tests whether the learned schedule β = (β_1, …, β_L) from a small donor graph can be reused on a larger recipient. Across 3-regular and Erdős–Rényi families with donors n∈{8,10,12} and recipients n′=14, the answer is: transfer quality is governed almost entirely by the recipient graph (dense ER works very well; sparse cross-family is hard) and is essentially insensitive to donor size — 8-node donors are as good as 12-node donors. For Yuan, this is a direct cousin of Y1's iterative warm-start: both are strategies for cheap parameter acquisition in shallow QAOA-family circuits on the same canonical 3-regular MaxCut benchmark.
Main contribution
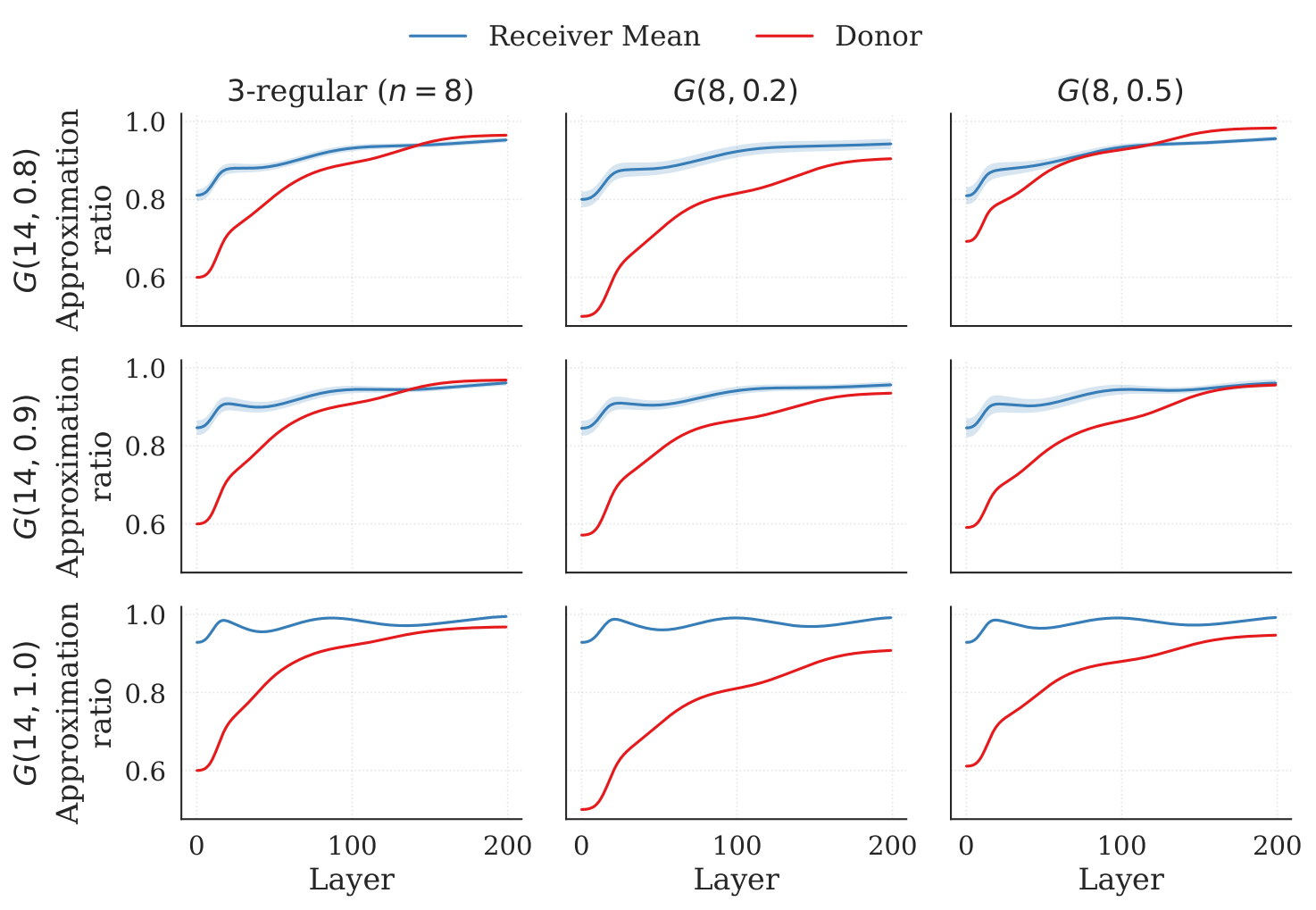
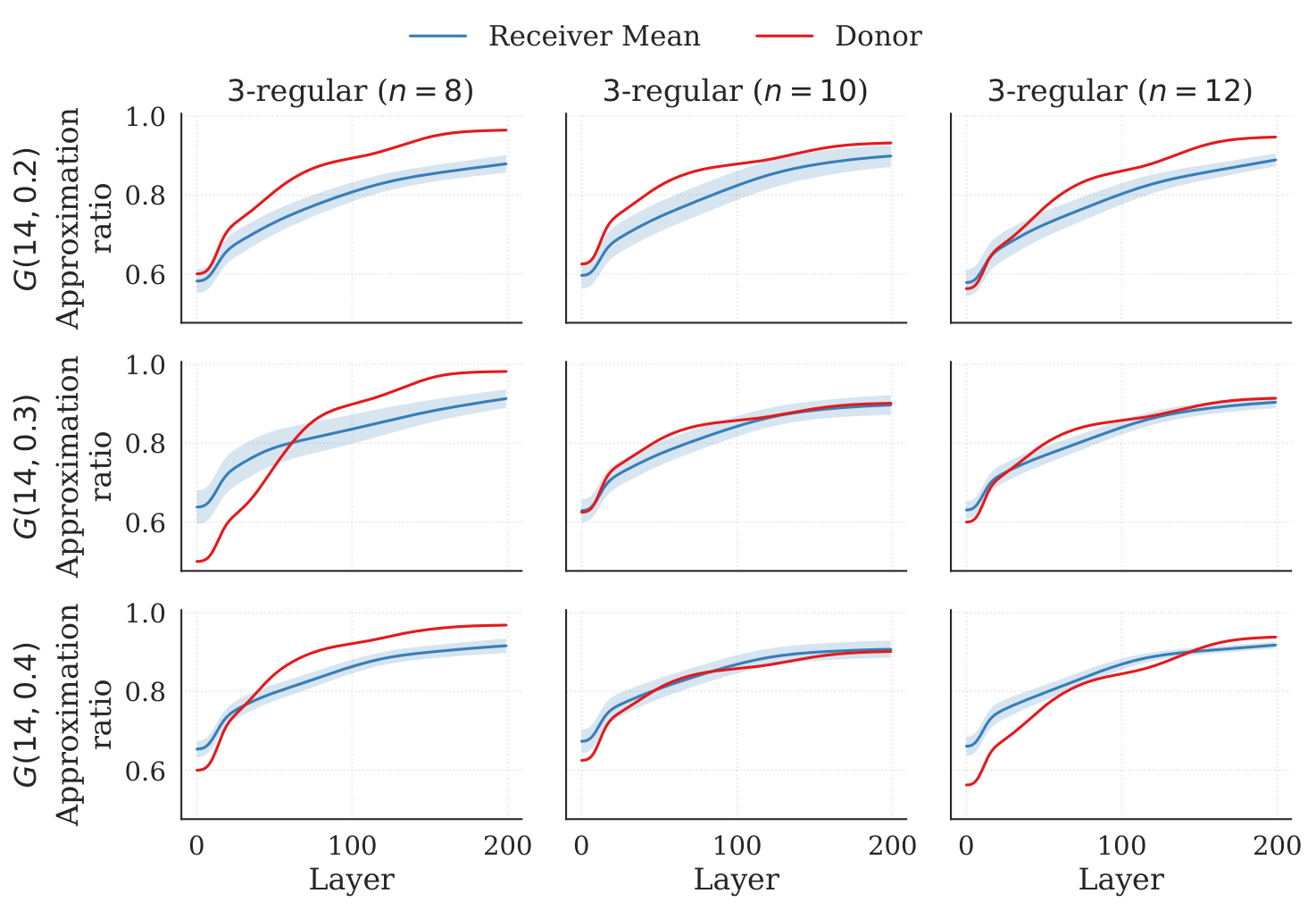
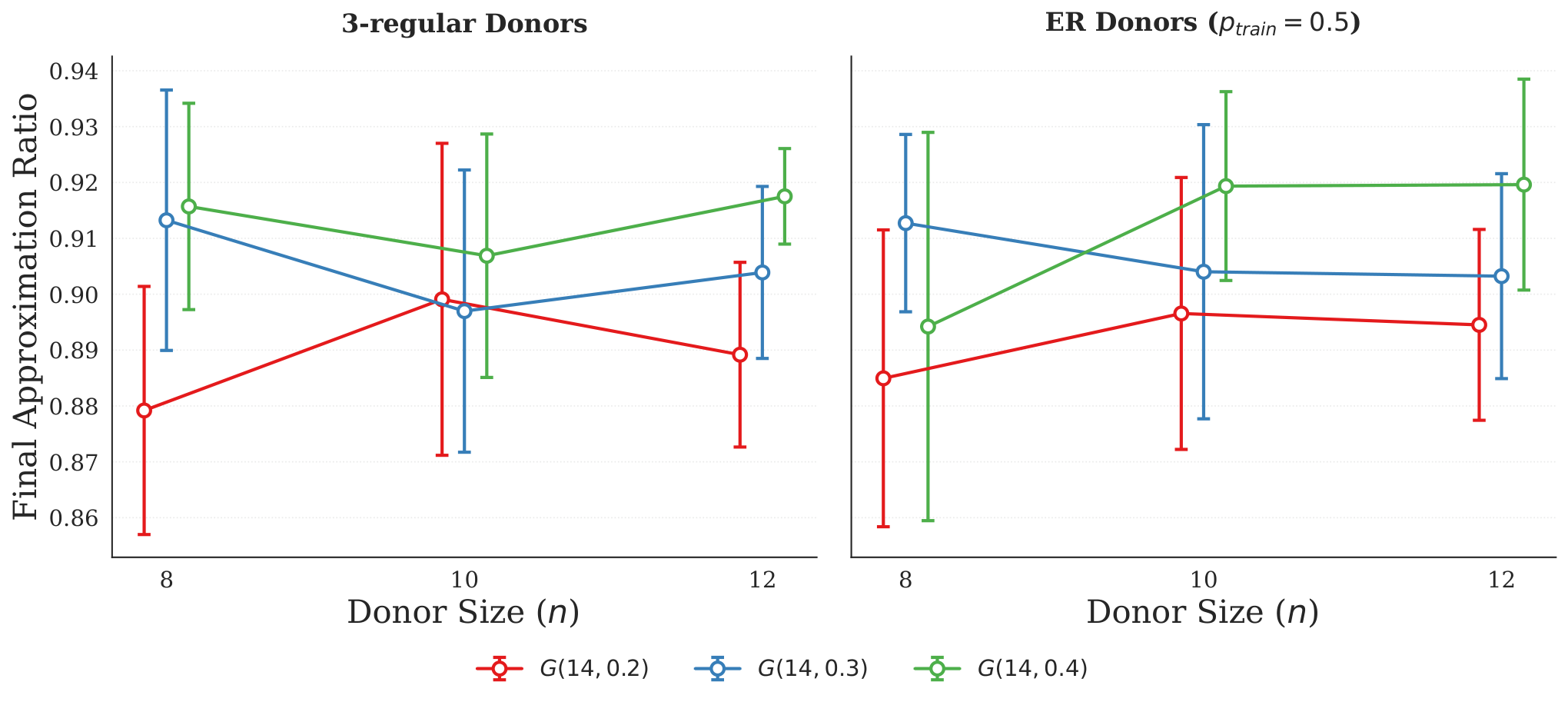
A systematic empirical study of one-to-one positional parameter transfer in FALQON for unweighted Max-Cut, with three findings: (i) recipient density dominates — for ER recipients with p∈{0.8,0.9,1.0} the transferred schedule reaches approximation ratios of ≈0.95–0.98 with low variance, often matching or exceeding the donor-side training trajectory; (ii) sparse cross-family transfer (3-regular donor → sparse ER recipient at p=0.2) underperforms the donor reference, with the gap closing as recipient density grows; (iii) 8-node donors match 10/12-node donors in transfer quality, so the cheapest donor is also the most cost-effective.
Key algorithms / protocol steps
- FALQON update rule (§3.1): at step k, measure
A_k = ⟨ψ_k | i[H_M, H_C] | ψ_k⟩; setβ_{k+1} = −A_k; applyU_M(β_{k+1}) U_C. Guarantees discrete-time monotonic descent (up to sampling noise). - Max-Cut cost:
H_C = ½ Σ_{(i,j)∈E} (1 − Z_i Z_j)on G=(V,E). - Transfer protocol (§4): position-wise mapping
β^(R)_t = β^(D)_tfor t=1,…,L with no re-indexing, interpolation, or post-hoc adjustment. - Donor / recipient ensembles: donors n∈{8,10,12}; recipients n′=14; families = 3-regular graphs and ER G(n,p) with donor p∈{0.2,0.3,0.4,0.5}, recipient p∈{0.2,0.3,…,1.0}; 10 instances per configuration; exact state-vector simulation.
- Metric: approximation ratio against the brute-force-computed Max-Cut on the 14-node recipient.
Detailed walkthrough
Sections §1–§2 motivate parameter transfer as a way to dodge the per-layer measurement bottleneck of FALQON. FALQON's distinguishing feature, relative to vanilla QAOA, is that the schedule β is not freely optimised over a smooth landscape but is generated step-by-step by feedback from a commutator measurement. Two consequences follow: there is no classical outer optimiser to seed with warm-start parameters, and the schedule encodes dynamical information about the cost landscape rather than being a fully tunable variational object. This makes parameter transfer a particularly elegant tool: if the dynamical response of two instances is similar, the learned schedule should carry over.
Section §3 sets up the formal machinery. The continuous Lyapunov control is dV/dt = A(t)β(t) with A(t) = ⟨ψ| i[H_M, H_C] |ψ⟩; choosing β(t) = −A(t) ensures monotonic descent of V = ⟨H_C⟩. After Trotter discretisation with step Δt, the circuit becomes U(β) = Π_{k=1}^L U_M(β_k) U_C with U_C = exp(−iH_C Δt), U_M(β_k) = exp(−iβ_k H_M Δt).
Section §4 (Methodology) defines the donor-recipient protocol. Crucially, transfer is strictly positional: the k-th layer parameter from the donor becomes the k-th layer parameter of the recipient, with no rescaling or interpolation. This is deliberately conservative — it isolates the bare scale-invariance of the learned schedule.
Section §5 presents three empirical patterns. (a) Dense ER recipients are easy: for recipients with p∈{0.8,0.9,1.0}, transferred schedules reach approximation ratios of 0.95 / 0.96 / 0.98 and frequently exceed the donor-side training trajectory. The authors argue this is because dense ER graphs are nearly regular at the macroscopic scale — local edge-pattern variability gets washed out, so the commutator feedback signal depends mainly on average degree, which is shared across donor and recipient. (b) Sparse cross-family is hard: 3-regular donor → sparse ER recipient at p=0.2 underperforms the donor reference, the gap shrinking as p increases to 0.3 and 0.4. (c) Donor size is largely irrelevant: in both 3-regular and ER (p=0.5) families, the final approximation ratio for n′=14 is statistically indistinguishable across donor sizes n∈{8,10,12}. The std bars overlap substantially, so the cheapest donor wins. The authors take this as evidence that FALQON learns control sequences whose structure depends on local Hamiltonian features rather than the absolute scale of the donor instance.
The conclusion (§6) frames the three findings as a coherent story: target hardness dominates donor properties; transferability is recipient-bound; small donors suffice. They flag future work on rescaling for extreme size gaps, evaluation on real noisy hardware, and explicit spectral / landscape diagnostics for when transfer should and should not work.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (iterative warm-started QAOA on 3-regular MaxCut): Tightest overlap. Both papers target the same canonical benchmark (3-regular MaxCut) with the same goal — reducing the expensive parameter-search burden. Y1 achieves this via measurement-based iterative refinement; this paper achieves it via positional transfer from cheaper donor instances. The mechanisms are complementary: Y1's iteration could plausibly be applied after transfer to refine the recipient schedule.
- Y3 (DGMVP portfolio QAOA, layerwise + dual annealing): Shared concern with parameter-search efficiency in shallow-circuit QAOA-family algorithms. Y3 finds dual annealing + layerwise robust; this paper finds positional transfer robust for FALQON. Both reduce the optimisation overhead but address different parts of the pipeline.
Recommended action for Yuan
- Read & cite in any future paper on QAOA parameter scheduling or warm-starting — this is a natural comparison point alongside Galda 2023, Shaydulin 2022.
- Consider a follow-up combining Y1's measurement-based iterative warm-start with FALQON transfer: the transferred schedule provides the seed, the iterative refinement closes the residual gap. Worth a 1-week scoping study.
- Reach out (low priority) to Duzzioni's group if their next FALQON paper looks at extreme size gaps — a co-authored note on combining transfer with warm-starting could be a natural fit.