Non-Abelian Mixer for QAOA on Hybrid Oscillator-Qubit Quantum Processors
Abstract
The realization of universal control in hybrid oscillator-qubit quantum processors enables the systematic design and implementation of quantum algorithms. However, the algorithmic development for such platforms remains at an early stage. While the Quantum Approximate Optimization Algorithm (QAOA) has been extensively studied in both continuous-variable (CV) and discrete-variable (DV) quantum systems, its development in the hybrid CV-DV setting remains limited. In this paper, we propose a hardware-native non-Abelian mixer for QAOA on hybrid CV-DV quantum processors and develop a corresponding hybrid ansatz for the Max-Cut problem. We evaluate the proposed ansatz on unweighted Erdős–Rényi graphs and benchmark it against the standard transverse-field mixer using the approximation ratio and optimal-solution probability. Across all graph sizes and Fock cutoffs in our simulations, the proposed non-Abelian mixer consistently improves both expected solution quality and the probability of sampling an optimal solution relative to the transverse-field mixer.
Executive summary
The authors construct a QAOA mixer that lives natively on a hybrid CV-DV processor — GKP-encoded logical qubits in superconducting microwave resonators with ancillary transmon controllers — using non-Abelian quantum signal processing (NA-QSP). The key construction is a per-pair "local mixer" that alternates qubit-controlled displacements along the oscillator's x̂ and p̂ quadratures with interleaved X-rotations, replacing the standard transverse-field mixer Σ Xi. On unweighted Erdős–Rényi MaxCut instances at N∈{4,5} the non-Abelian mixer beats the transverse-field baseline by ≈0.13 in approximation ratio and ≈0.16 in optimal-solution probability, with the biggest jump coming from depth d=0→1. Mixer family overlap with Y1/Y2 is direct; the platform overlap with Y3/Y6 is partial.
Main contribution
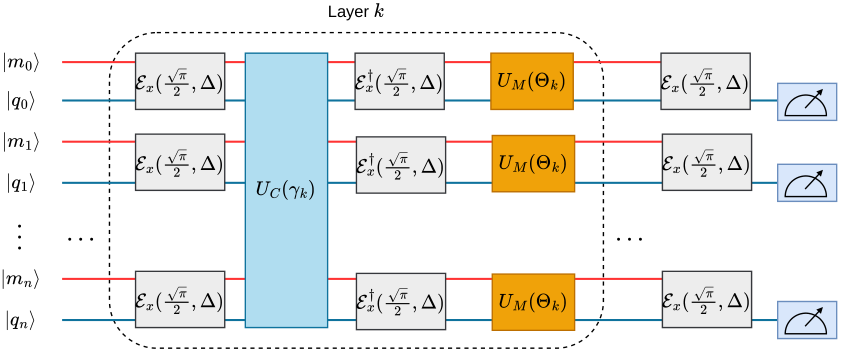
(i) A new QAOA mixer family parameterised by Θk={β0, βx(l), φx(l), θx(l), βp(l), φp(l), θp(l)}l=1..d, built from native conditional-displacement primitives of the phase-space ISA; (ii) a full hybrid QAOA ansatz for MaxCut that encodes the logical bitstring in GKP states, transfers it to the qubit register via 𝓔x(√π/2,Δ) for the cost unitary, and applies the non-Abelian mixer back in the oscillator phase space; (iii) numerical evidence that the new mixer strictly dominates the transverse-field baseline across all tested (N, Nmax) cells.
Key constructions
- Local non-Abelian mixer (Eq. 9): UM(i)(Θk) = RX(2β0) ∏l=1..d [CD(iβx(l),σφx) RX(2θx(l)) CD(βp(l),σφp) RX(2θp(l))]. At d=0 this reduces to e−iβ₀ Σ Xi, recovering the transverse-field baseline.
- GKP logical readout map (Eq. 7): 𝓔x(√π/2,Δ) = ei√π p̂ Δ² Y ei (√π/2) x̂ X, with the prefactor providing the non-Abelian precorrection for finite-energy GKP position uncertainty.
- Layer unitary: Uk = UM(Θk) · ∏i𝓔x(i)† · UC(γk) · ∏i𝓔x(i), with cost unitary UC(γk) = ∏(i,j)∈E RZZ(i,j)(−γk).
- Optimisation: multistart COBYLA over Θk, γk at fixed QAOA depth P=2 and mixer depth d=2 for the main comparison.
Detailed walkthrough
The setup is hybrid CV-DV: each "logical qubit" lives as a finite-energy GKP codeword in a microwave-cavity oscillator, with a transmon ancilla that mediates control via the conditional-displacement gate CD(β, σφ) = exp[(βâ†−β*â)⊗σφ]. The phase-space ISA exposes (i) single-qubit rotations on the ancilla and (ii) CD pulses with adjustable amplitude and σ-axis. Because [x̂, p̂] = i/2, alternating CD along the x̂ and p̂ quadratures generates a genuinely non-Abelian control group on each oscillator-qubit pair, which is where the "extra expressivity" claim comes from.
What the ansatz actually does, layer by layer. Each QAOA layer transfers the logical bitstring out of the GKP encoding into the ancilla register (𝓔x), applies the standard MaxCut phase ∏ RZZ(−γk) on the ancillas, transfers the accumulated phases back into the GKP-encoded logical state (𝓔x†), and then applies the per-pair non-Abelian mixer UM(i) directly in oscillator phase space. The mixer's "x-quadrature CD then X-rotation then p-quadrature CD then X-rotation" structure is the smallest non-trivial NA-QSP block — at d=1 this is two CDs and three single-qubit rotations per pair.
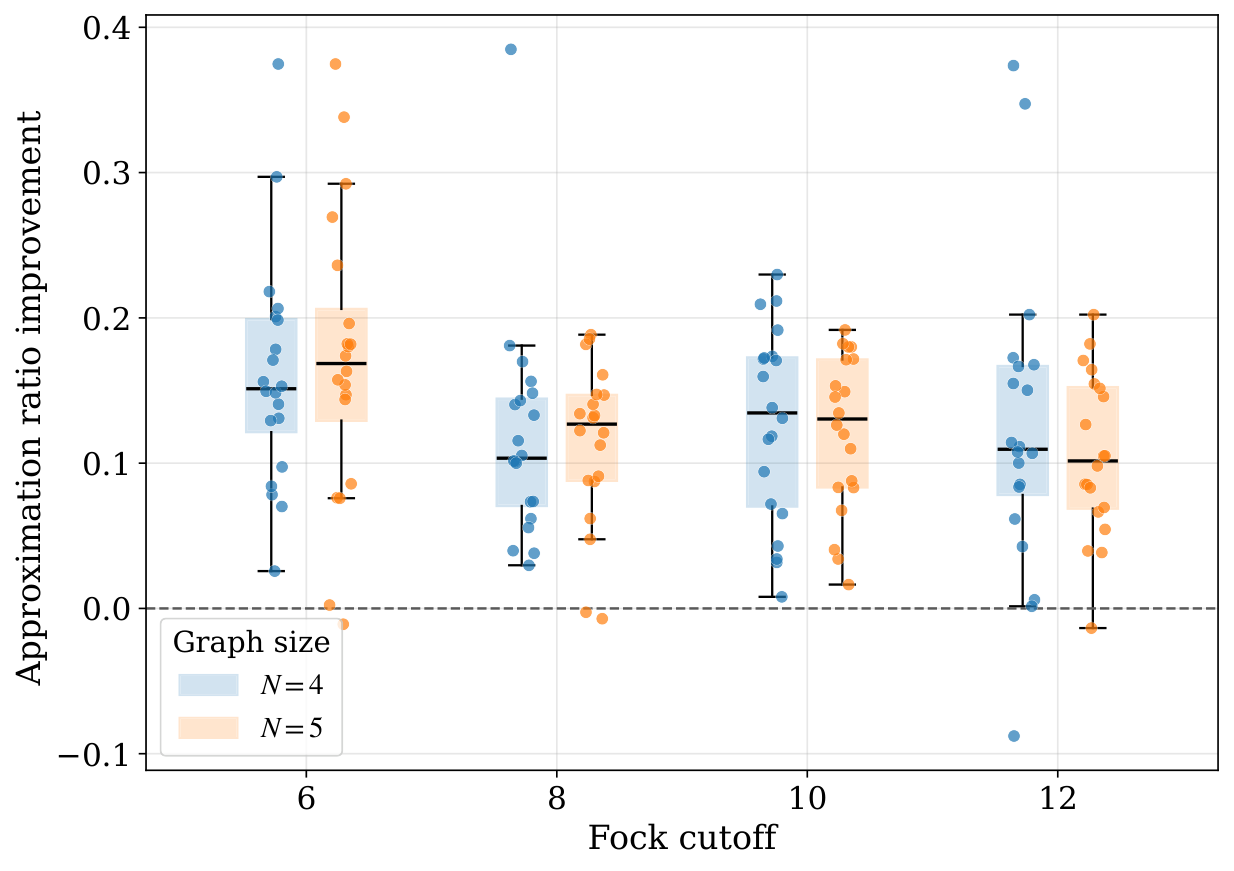
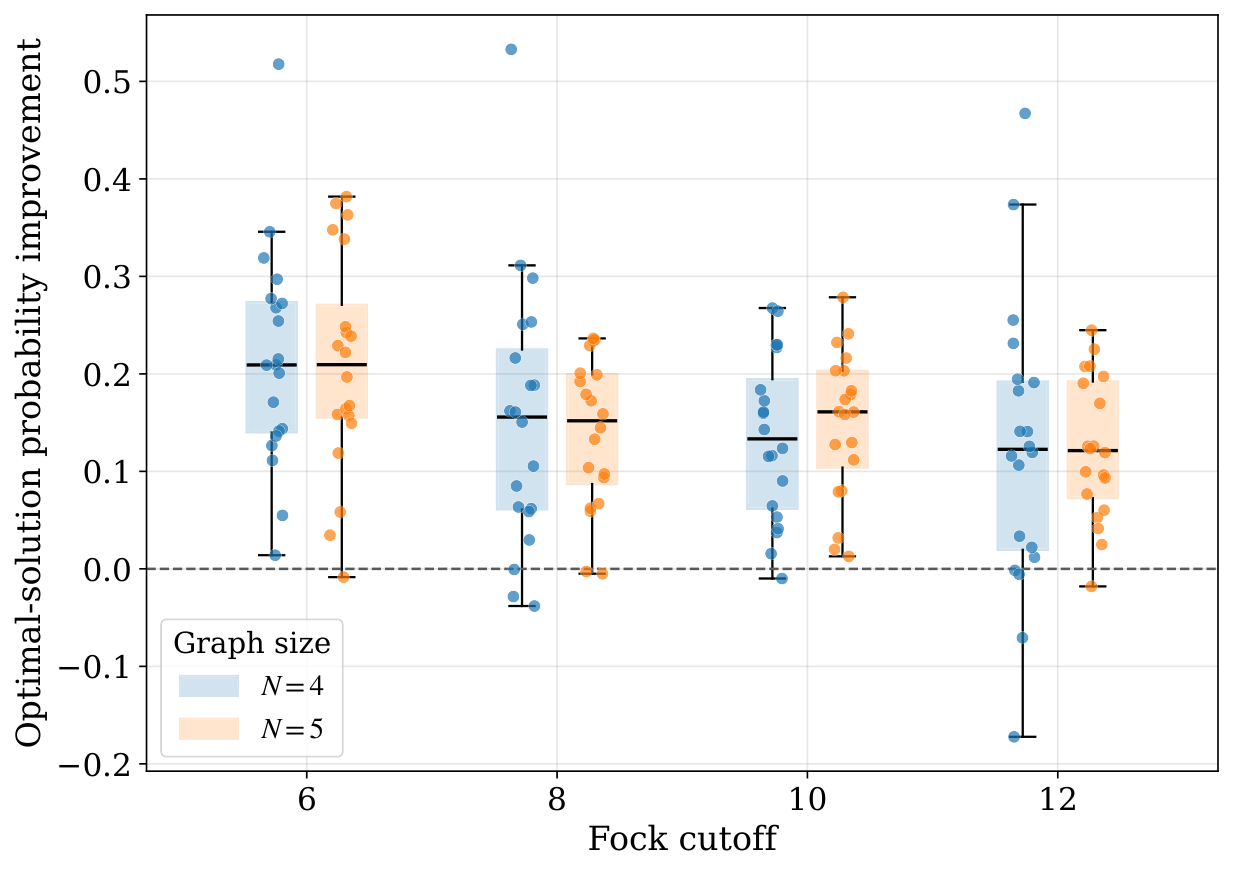
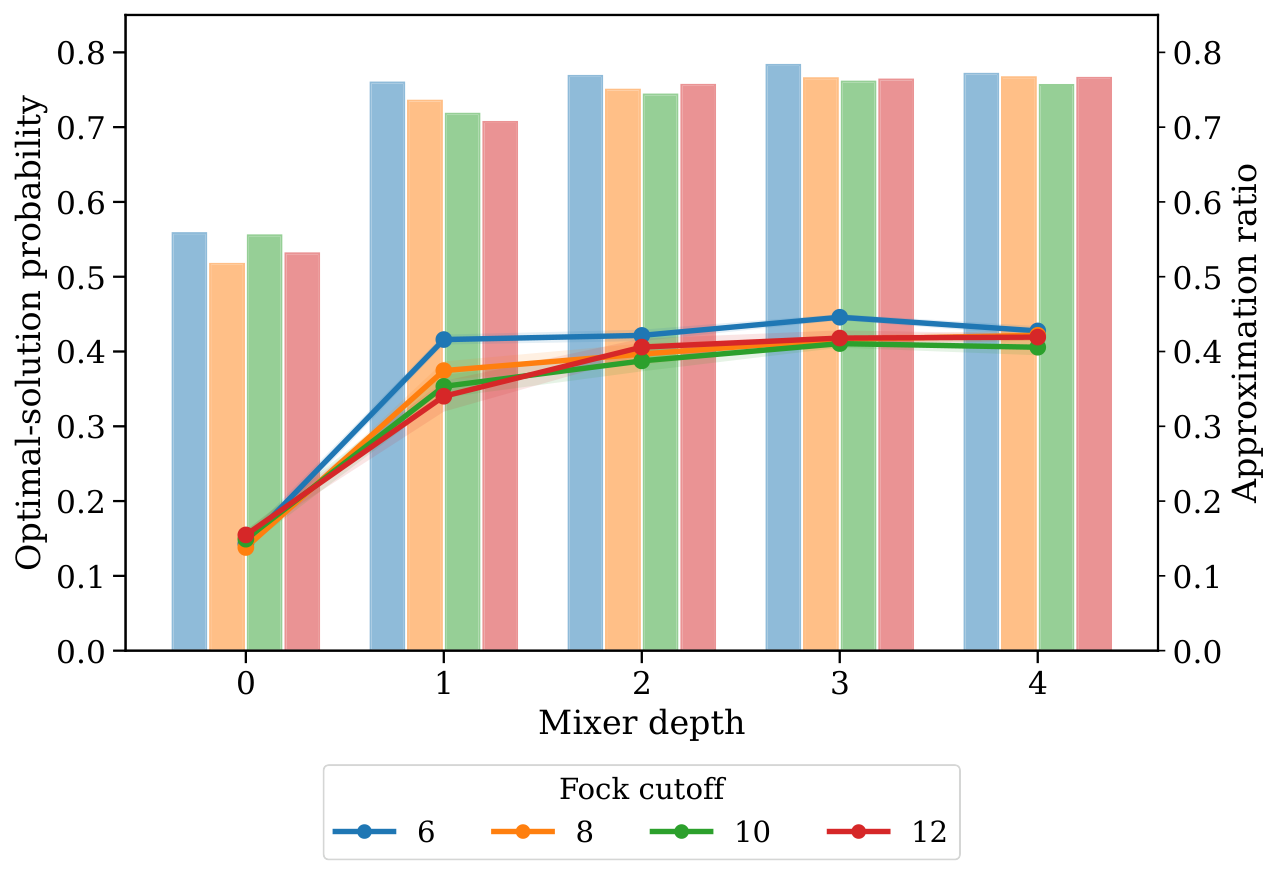
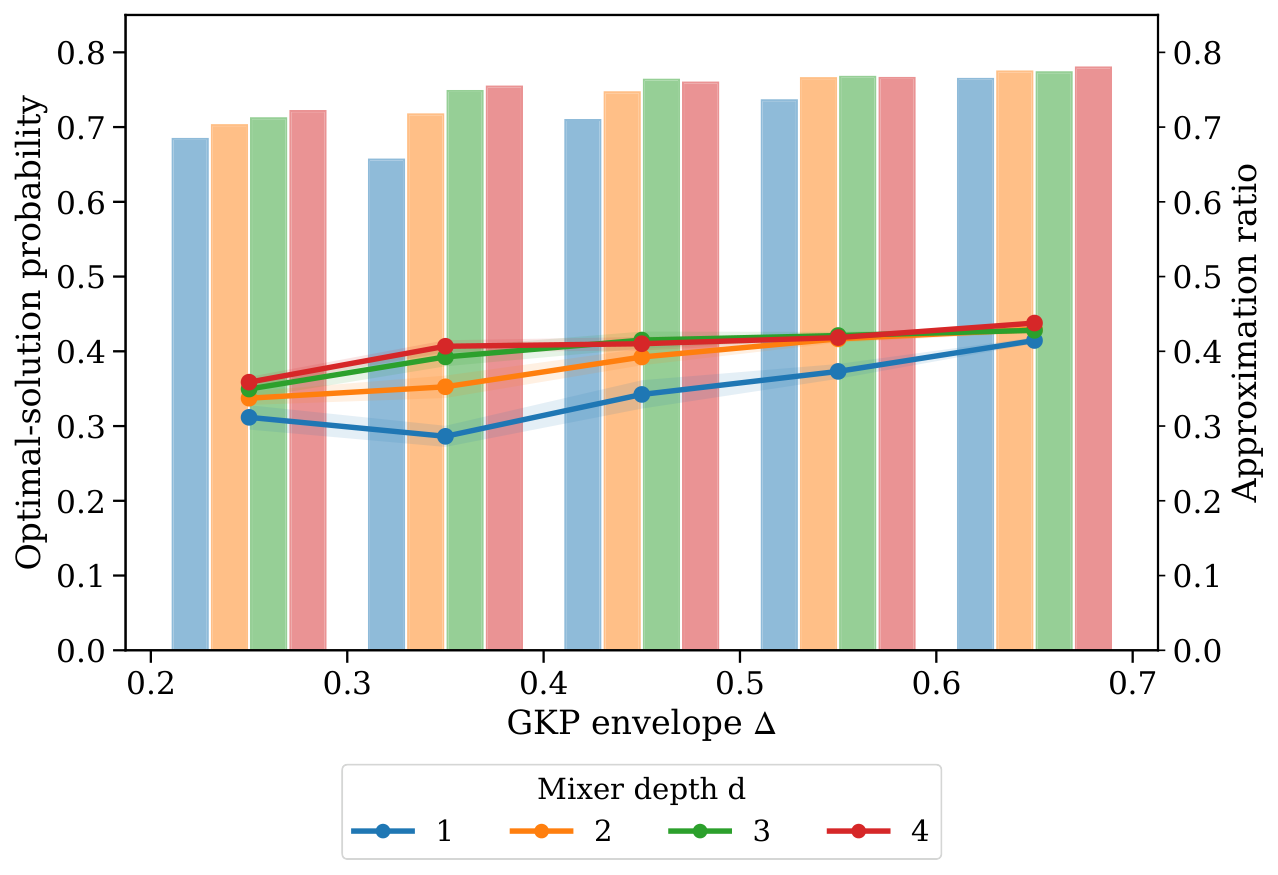
The simulation evidence. The benchmark in §IV.B uses 20 Erdős–Rényi MaxCut instances per cell, N∈{4,5}, Nmax∈{6,8,10,12}, P=2, d=2. Averaged over Fock cutoffs the approximation-ratio improvement vs the transverse-field mixer is +0.132 (N=4) / +0.128 (N=5); the optimal-solution-probability improvement is +0.156 / +0.155. The median improvement is positive for every (N, Nmax) cell, so this is not a tail-driven mean. The mixer-depth sweep (§IV.C) shows the gain comes overwhelmingly from d=0→1: at N=4, Nmax=10 the mean Popt jumps from 0.149 (transverse field) to 0.353 (one NA-QSP layer); subsequent layers add only marginal improvement. The Δ-sweep shows that larger envelope parameter (less-sharp GKP states) helps at fixed Fock cutoff because the truncation error of sharper, higher-energy states dominates.
What's missing and what's strong. The paper does not implement on hardware — everything is simulation with truncated Fock spaces. It also does not study the cost in coherence time of the additional CDs vs the cleaner RX baseline. But the construction is clean, the comparison is apples-to-apples (the d=0 case is exactly the transverse-field mixer), and the d=0→1 jump is large enough that it is unlikely to be a numerical artefact. The natural angle for Yuan is the design-principle observation: this paper effectively replaces a "Σ Xi" mixer with a problem-aware mixer constructed from hardware-native non-commuting generators, which is the same mixer-engineering axis Y2's quasi-binary hard-constraint mixer occupies — except here the engineering target is hardware expressivity rather than constraint preservation. Both papers argue that the mixer is the right design surface for QAOA improvement.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary hard-mixer QAOA): closest method-level overlap. Both papers reject the default transverse-field mixer and engineer a problem- or platform-specific mixer instead: Y2 to preserve a hard cardinality constraint, this paper to exploit hardware-native non-commutativity. The argument structure — "the mixer is where most of the QAOA-improvement leverage is" — is the same.
- Y1 (warm-started QAOA, MaxCut): shared scope (Erdős–Rényi MaxCut benchmark) but no method overlap on warm-starting; this paper trains from scratch with COBYLA.
- Y3 (QAOA portfolio, layerwise optimisation): tangential — both are QAOA-side. The hybrid-CV-DV platform is a different hardware story than the noisy IBM/quantum-simulator regime Y3 operates in.
- Y6 (superconducting hardware): partial platform overlap — both operate on superconducting architectures, though this paper targets cavity-coupled GKP-mode hardware rather than the bare-qubit IBM Heron line.
- Y4, Y5: no direct overlap.
Recommended action for Yuan
- Cite as a related mixer-engineering paper in the next Y2 follow-up. The "mixer is the design surface" framing is highly compatible and would let Yuan position the quasi-binary constraint-preserving mixer alongside other problem-aware mixer constructions.
- Read deeper if Yuan revisits CV-DV / bosonic platforms. The phase-space ISA construction here is reusable: a constraint-preserving mixer for portfolio cardinality could in principle be built from the same NA-QSP primitives by encoding portfolio bitstrings into GKP states. Worth a discussion with collaborators on the bosonic / CV side.
- Do not implement for direct comparison — the platform is too far from Yuan's IBM-hardware focus to warrant a side-by-side benchmark right now.