Evaluating Parameter Transfer in FALQON Across Graph Families
Abstract
We evaluate FALQON parameter transfer for Max-Cut, transferring sequences from small donors (n ∈ {8,10,12}) to 14-node recipients. Using 3-regular and Erdős–Rényi families, we show that transfer success is dictated by the recipient graph, not the donor. Transfer excels for dense recipients — achieving high approximation ratios regardless of the donor — but remains challenging in sparse cross-family cases. Crucially, performance is highly resilient to donor size, with 8-node donors matching larger instances. Thus, cheap small graphs can provide robust parameters for larger targets, significantly reducing the measurement overhead of the feedback loop.
Executive summary
The authors systematically probe whether the layer-wise control schedule learned by FALQON — a Lyapunov-feedback variant of QAOA — on small donor Max-Cut instances can be reused on larger recipient instances. They find that transferability is governed almost entirely by the structural regime of the recipient: dense Erdős–Rényi targets accept parameters from any small donor with sub-percent variance, while sparse cross-family targets remain hard. Crucially, 8-node donors match 12-node donors statistically, so the donor side can be made arbitrarily cheap. This is the cleanest existing empirical statement that FALQON's feedback gains are scale-transferable in the same way QAOA angles are, and it directly parallels the recipient-side / donor-side analysis Yuan used in the iterative warm-starting work (Y1).
Main contribution
Two systematic experiments establish: (i) problem-size transferability — a feedback sequence β(D)=(β1,…,βL) optimised on n∈{8,10,12} can be applied position-wise to n′=14 with negligible degradation when the recipient is dense; (ii) graph-family dependence — within 3-regular and within Erdős–Rényi the transfer is benign; across families (3-regular donor → sparse ER recipient) it is the dominant failure mode. The key practical takeaway is the measurement-cost reduction: FALQON's commutator-evaluation feedback loop scales with both qubit count and circuit depth, so being able to learn β on an n=8 cousin instead of n=14 cuts the dominant cost.
Key algorithms / experimental protocol
- FALQON formalism (§3.1): discretised Lyapunov control id|ψ⟩/dt = (HC+β(t)HM)|ψ⟩ with the feedback law βk+1 = −Ak, Ak=⟨ψk|i[HM,HC]|ψk⟩, guaranteeing monotonic ⟨HC⟩ decrease.
- Transfer protocol (§4): strict one-to-one position-wise mapping β(R)t=β(D)t, no rescaling, no interpolation, no post-transfer refinement.
- Graph families: 3-regular (𝒢n,3) and Erdős–Rényi G(n,p) with donor p∈{0.2,0.3,0.4,0.5} and recipient p∈{0.2,…,1.0}; 10 recipient instances per cell.
- Evaluation: exact state-vector simulation (n≤14 so brute-force optimum is computable), reporting approximation ratio averaged over recipient instances and compared to the donor's training trajectory.
Detailed walkthrough
FALQON sits in a tight neighbourhood of QAOA: the cost unitary e−iHCΔt and mixer e−iβkHMΔt alternate exactly as in QAOA, but the βk are not optimised classically — they are read off from a quantum measurement of the commutator Ak. This makes FALQON's "training" a sequence of single-layer expectation estimates rather than a global non-convex landscape walk, which sidesteps barren plateaus but pays for it in measurement budget: at each new layer one must estimate ⟨ψk|i[HM,HC]|ψk⟩ to the precision needed for the feedback to stay monotone. As soon as one wants to use FALQON on a real device at non-trivial n, this measurement budget — not gate count — becomes the bottleneck.
The authors' "donor–recipient" protocol is a brutally simple solution to this: train β on a small instance you can afford to measure, then apply the resulting fixed schedule to the larger instance you cannot afford to train. The natural question is whether the schedule is even meaningful when the recipient has a different size, density, or family. Their answer has three parts.
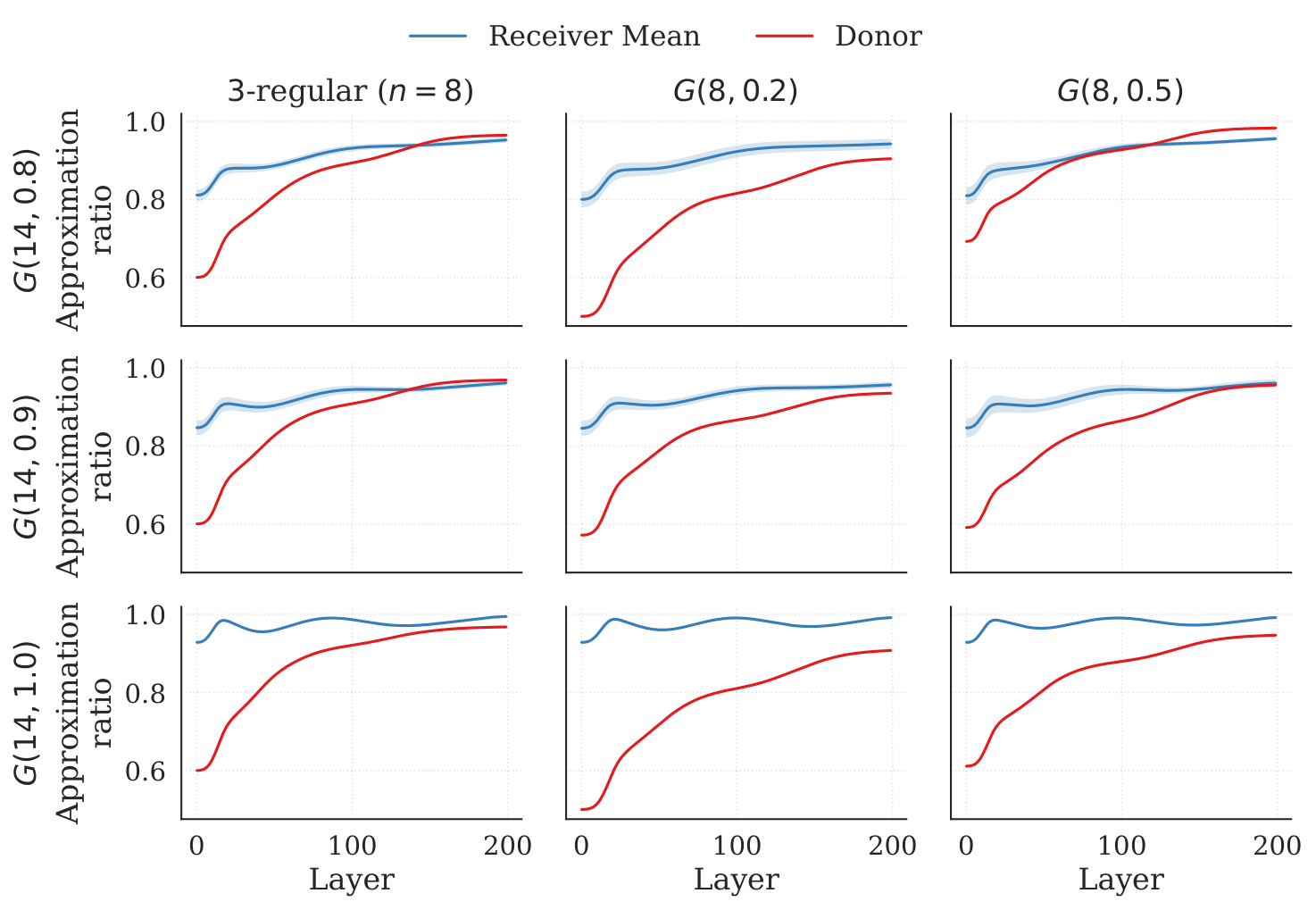
Dense recipients. For Erdős–Rényi recipients at p∈{0.8,0.9,1.0}, the transferred trajectory reaches approximation ratios 0.95, 0.96, 0.98 respectively, with low variance across recipient instances and largely independent of which 8-node donor was used (Fig. 1, §5). The authors give a clean physical reading: in the dense limit the adjacency matrix is nearly uniform, so the commutator feedback signal A(t) is dominated by the mean degree rather than by local structure. A small dense donor therefore produces approximately the same dynamics-driven β-trajectory as a larger dense recipient.
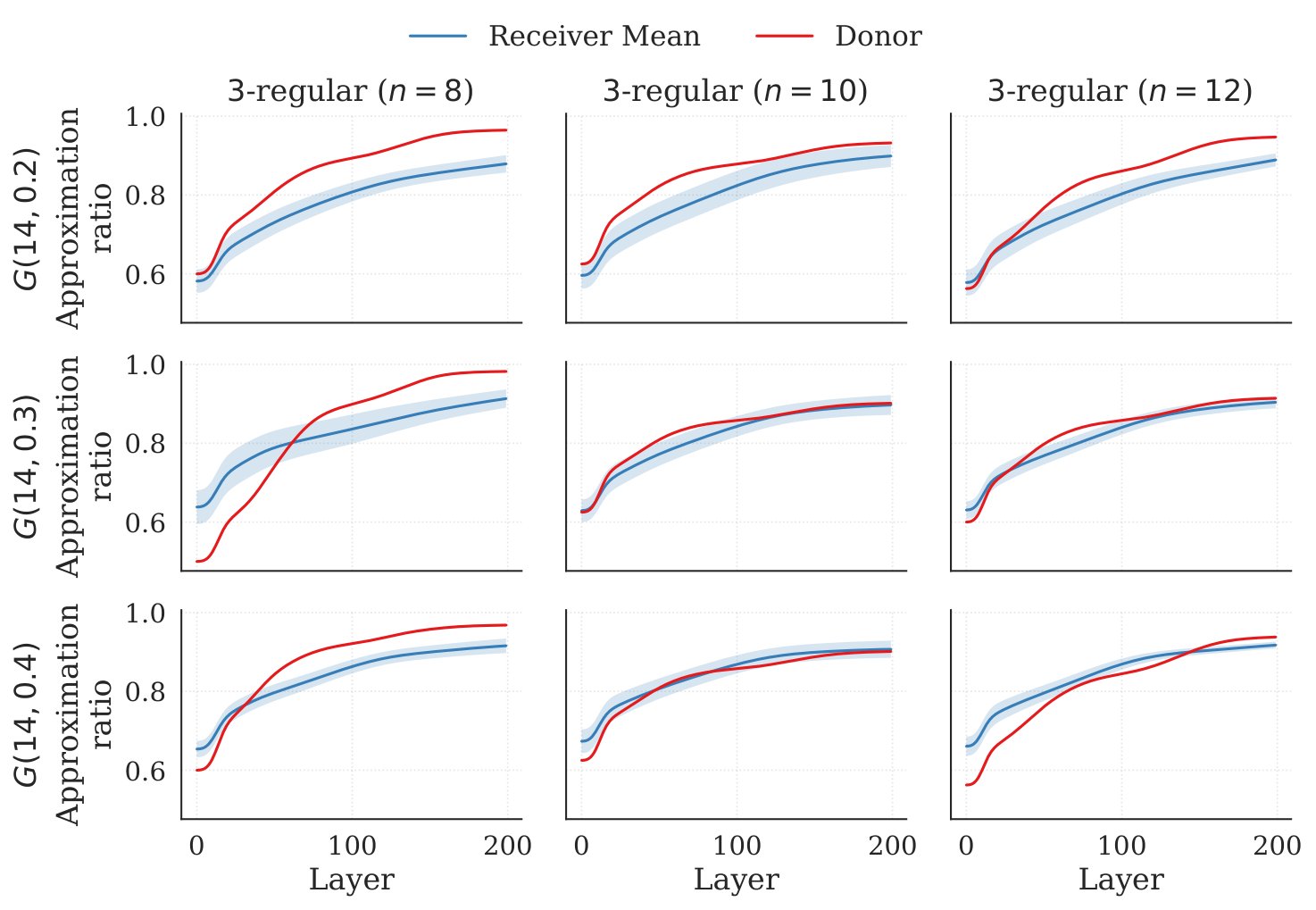
Sparse cross-family recipients. Transferring from 3-regular donors to sparse Erdős–Rényi recipients (p=0.2) consistently underperforms the donor reference (Fig. 3, §5). The gap narrows monotonically with recipient density. This is consistent with the inverse reading: in sparse regimes specific local connectivity matters, and the spectral profile of i[HM,HC] for 3-regular and for sparse Erdős–Rényi instances diverges.
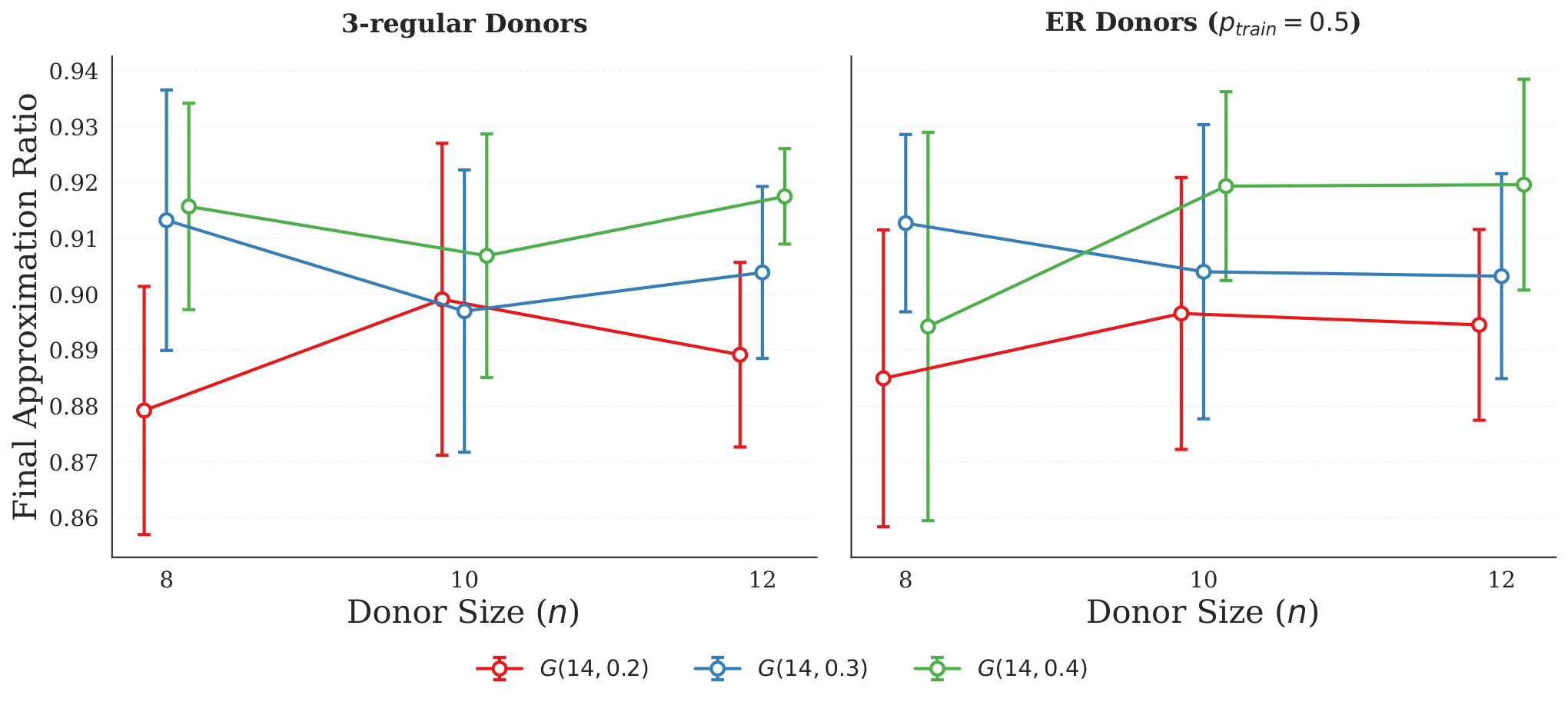
Donor-size resilience. The most operationally relevant result is Fig. 2 (§5): for both 3-regular and ER(p=0.5) donor families, the final 14-node approximation ratio is statistically indistinguishable across donor sizes n∈{8,10,12} (overlapping standard deviation bars). This is exactly the kind of "cheap donor, expensive target" asymmetry that justifies parameter transfer as a strategy, and it is somewhat stronger than typical QAOA parameter-transfer findings, which often need some rescaling between sizes (the authors cite Shaydulin et al. 2022).
What the paper does not address: (i) noisy simulation — all results are exact state-vector, so the donor-side measurement noise that motivates the protocol is itself excluded from the experiment; (ii) recipients beyond n=14; (iii) any spectral-theoretic prediction of when transfer should work. The authors flag all three in their future-work section. The natural follow-up — and the one Yuan should care about — is whether the donor-side feedback gain trajectory could be combined with iterative warm-starting on the recipient (as in Y1) to recover the loss in sparse cross-family settings without paying the full FALQON measurement cost on the recipient. This is a clean joint experiment.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (warm-started QAOA, MaxCut, 3-regular): very strong overlap. Y1's iterative warm-starting reuses information across optimisation rounds on the same instance; this paper reuses information across instances of growing size. Both share the same target (3-regular MaxCut), and both are attempts to reduce the measurement cost of the variational outer loop. The natural composition — small donor → warm-start an iterative refinement on the recipient — would let Yuan claim a direct extension of Y1.
- Y3 (QAOA layerwise/parameter optimisation, robustness): the position-wise transfer here is closely related to layer-wise scheduling: the donor's β-sequence is effectively a layer-indexed schedule reused on the recipient. The "recipient-governed" pattern is consistent with Y3's observation that dual-annealing + layerwise is the most robust strategy.
- Y2 / Y4 (hard mixers / Grover): no direct overlap — FALQON uses the standard transverse-field mixer, no hard-constraint preservation.
- Y5 / Y6: no overlap.
Recommended action for Yuan
- Cite in the next QAOA-warm-starting paper. This is the closest contemporary on parameter transfer for a FALQON-class algorithm and frames the recipient-vs-donor question cleanly. Y1's iterative warm-starting and this paper's small-donor transfer are complementary mechanisms — pointing both out in the same paragraph is a natural framing.
- Discuss a follow-up experiment with Barnes / Yang: compose Yuan's iterative warm-starting (Y1) with the small-donor schedule transfer here. The hypothesis is that the sparse-cross-family failure mode the authors flag can be patched with one or two warm-started iterative rounds on the recipient, recovering the measurement-budget advantage. If this works, it's a direct extension of Y1 with strong empirical legs.
- Skip emailing the authors for now — the paper is self-contained, exact-simulation only, and the next move is on Yuan's side rather than theirs.