Quantum Search without Global Diffusion
Abstract
Quantum search is among the most important algorithms in quantum computing, offering fundamentally new approaches to optimisation and information processing. At its core is quantum amplitude amplification, a technique that achieves a quadratic speedup over classical search by combining two global reflections: the oracle, which marks the target, and the diffusion operator, which reflects about the initial state. We show that this speedup can be preserved when the oracle is the only global operator, with all other operations acting locally on non-overlapping partitions of the search register. We present a recursive construction that, when the initial and target states both decompose as tensor products over these chosen partitions, admits an exact closed-form solution for the algorithm's dynamics. This is enabled by an intriguing degeneracy in the principal angles between successive reflections, which collapse to just two distinct values governed by a single recursively defined angle. Applied to unstructured search, a problem that naturally satisfies the tensor decomposition, the approach retains the O(√N) oracle complexity of Grover search when each partition contains at least log₂(log₂ N) qubits. On an 18-qubit search problem, partitioning into two stages reduces the non-oracle circuit depth by as much as 51%–96% relative to Grover, requiring up to 9% additional oracle calls.
Executive summary
Burke and Mc Goldrick prove that the diffusion operator in Grover-style amplitude amplification need not be global: when both the state-preparation unitary A = ⊗ᵢ Aᵢ and the target state |x⟩ = ⊗ᵢ |xᵢ⟩ factor across a partition of the search register, all non-oracle operations can be replaced by purely local reflections, leaving the oracle as the only register-spanning operator. The construction is recursive; the analytic miracle is that the principal angles between successive reflection eigenspaces collapse to just two values governed by a single recursive angle γᵢ, so the dynamics reduce to a scalar 2×2 problem despite the eigenspaces having dimension 2i−1. For Yuan, the immediate methodological relevance is to Y4: Y4's cardinality-constrained Grover uses a structured feasible space, and this paper's locality-of-diffusion result is exactly the kind of structural ingredient that can shrink the non-oracle depth of Grover-based portfolio/cardinality solvers on NISQ hardware. The 51%–96% diffusion-depth reductions reported at 18 qubits, with only 9% oracle overhead, are practically meaningful for Y4's hybrid quantum-classical pipeline.
Main contribution
Given an n-qubit register partitioned into m blocks of sizes (n₁,…,nm) with the tensor-product decompositions above, the authors define the partial diffuser S_ψᵢ = Aᵢ(𝕀 − 2|0ᵢ⟩⟨0ᵢ|)Aᵢ† acting only within register i, and the recursive reflection Wᵢ = (S_ψᵢ W_{i−1})^{tᵢ} S_ψᵢ (W_{i−1} S_ψᵢ)^{tᵢ} with W₀ = S_x the oracle. They prove that the principal angles between the projectors S_ψᵢ and W_{i−1} collapse to {γᵢ, π/2 − γᵢ} where sin(2γᵢ) = sin(2θᵢ) sin(2t_{i−1}γ_{i−1}) and γ₁ = θ₁, with sin θᵢ = |⟨xᵢ | Aᵢ | 0ᵢ⟩| the local overlap. The closed-form success probability after tₘ outer iterations is ½[1 − (cos 2θₘ / cos 2γₘ) cos(2(2tₘ+1)γₘ)], and the oracle overhead relative to standard amplitude amplification is bounded by ∏ᵢ cos⁻¹(θᵢ). For unstructured search of a single target with equal stage size s ≥ log₂ log₂ N, this overhead converges to 1, preserving the O(√N) query complexity.
Key theorems / lemmas / algorithms
- Recursive reflection construction (Sec. III).
Wᵢ = (S_ψᵢ W_{i−1})^{tᵢ} S_ψᵢ (W_{i−1} S_ψᵢ)^{tᵢ}withW₀ = S_x— each level is itself a reflection, built from one global oracle and 4tᵢ partial diffusion reflections. - Principal-angle degeneracy (Subsec. III.B). Despite the reflection eigenspaces having dimension 2i−1, only two principal angles survive:
γᵢandπ/2 − γᵢ, with the recursionsin(2γᵢ) = sin(2θᵢ) sin(2t_{i−1} γ_{i−1}). This reduces the problem to a scalar 2×2. - Stage success probability (Eq. 8).
‖P_{xₘ} (S_ψₘ W_{m−1})^{tₘ} |ψ⟩‖² = ½[1 − (cos 2θₘ / cos 2γₘ) cos(2(2tₘ+1) γₘ)]; optimal iteratestₘ* = ⌊π/(4γₘ) − ½⌉. - Oracle complexity bound (Sec. III.C). Total cost ≤
C_Grover(n) / ∏ cos(θᵢ) · 1/(1 − 21−s/2)for equal stage sizes s. - Asymptotic preservation of O(√N) (Sec. III.D). For stage size
s ≥ log₂ log₂ N, both the cosine product and the geometric series collapse to 1 — the diffusion can be made fully local without losing the quadratic speedup.
Detailed walkthrough
The paper's conceptual move is to take the partial diffusion operator — a known device used in partial quantum search (Grover–Radhakrishnan–Korepin) and in some depth-reduction schemes — and ask whether the global diffuser can be eliminated entirely, not merely thinned. Previous works (Grover & Rudolph; Tulsi; Søndergaard et al.) reduced the average locality of the non-oracle operators but kept at least one global diffuser per amplification round; the new construction removes all of them. The price is that A and |x⟩ must factor across a chosen partition; the payoff is that every non-oracle gate in the algorithm acts on at most nᵢ qubits.
The technical core (Sec. III, especially Subsec. III.B) is a calculation showing that the product of two reflection projectors S_ψᵢ and W_{i−1}, viewed in the high-dimensional invariant subspace 𝒮_{i−1} = span{|s_{i−1},…,s_1⟩ : sⱼ ∈ {ψⱼ, ψⱼ⊥}}, has principal angles that collapse to the pair (γᵢ, π/2 − γᵢ). The cleanest way to see this is that W_{i−1}, although a reflection on a 2i−1-dimensional positive eigenspace, acts on the |ψᵢ⟩-fixed half of the Hilbert space exactly like a single rotation in the 2D plane span{|ψᵢ⟩, |xᵢ⟩}. The recursion sin(2γᵢ) = sin(2θᵢ) sin(2t_{i−1} γ_{i−1}) follows from tracking how successive applications of the inner reflections amplify the target component within register i. Once this degeneracy is in hand, the closed-form success probability Eq. (8) is essentially the standard amplitude-amplification trigonometry applied to a 2×2 problem.
The algorithmic shape of the full method (Sec. III.B, Fig. 2): apply (S_ψₘ W_{m−1})^{tₘ} to the initial product state |ψ⟩ = ⊗ |ψᵢ⟩, then measure register m — collapsing the remaining registers — and recurse on the remaining n − nₘ qubits. The oracle cost decomposes as a geometric series dominated by the first round, with common ratio 21 − s/2 for equal stage size s. The boxed total-cost bound is C_total ≤ C_Grover(n)/(∏ cos θᵢ) · 1/(1 − 21−s/2).
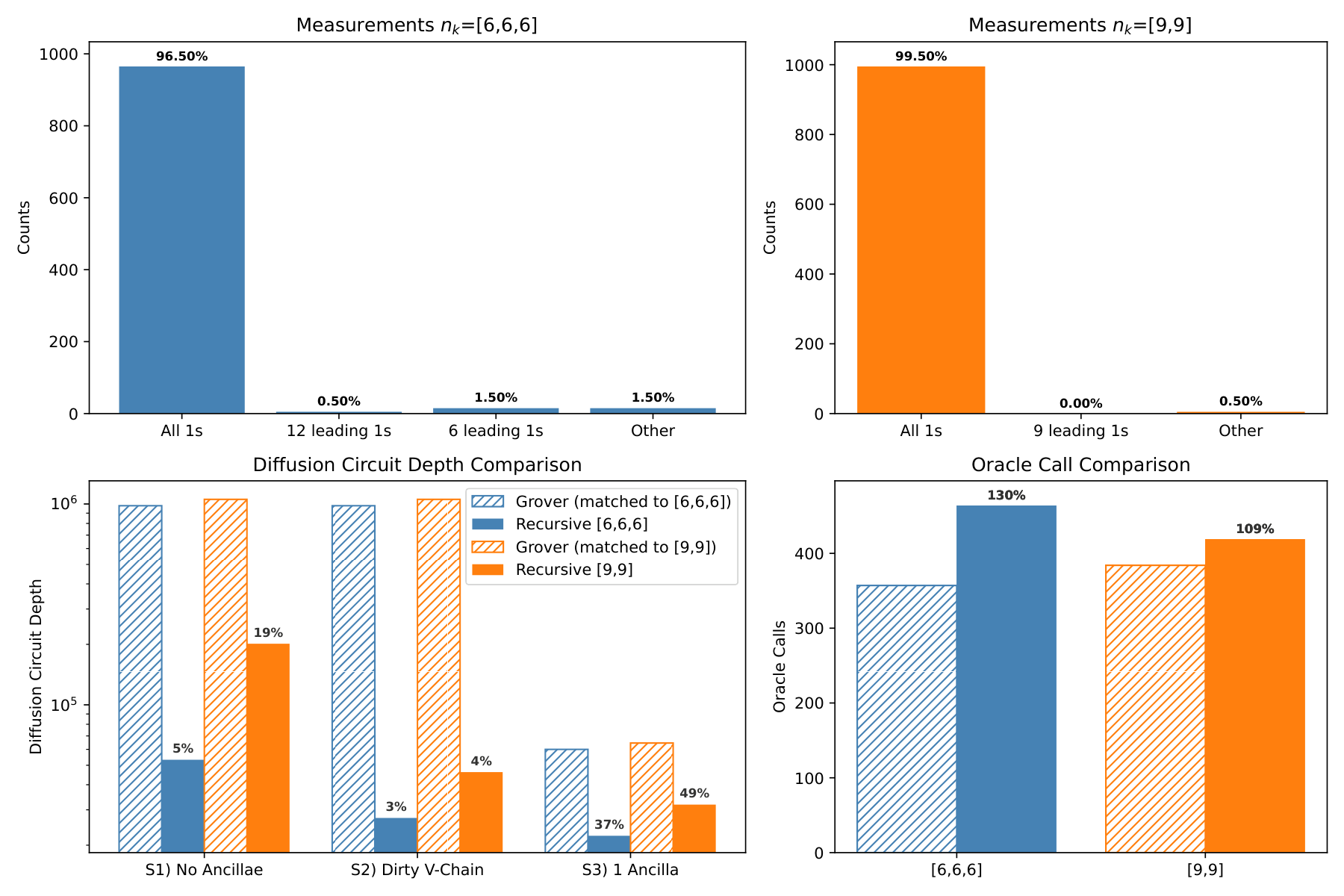
The experimental section (Sec. IV) verifies on an 18-qubit search of |1⟩⊗18. Two configurations are tested: 3 stages of 6 qubits (iterates [102, 25, 6]) and 2 stages of 9 qubits ([201, 17]). Over 1000 noiseless Qiskit shots the 3-stage scheme returns the correct target 96.5% (theory 96.7%) and the 2-stage scheme 99.5% (theory 99.8%). Mid-circuit measurements use the reset trick, and the failed shots show the expected hierarchical structure: 57% of the 3-stage failures still have the correct first-stage substring.
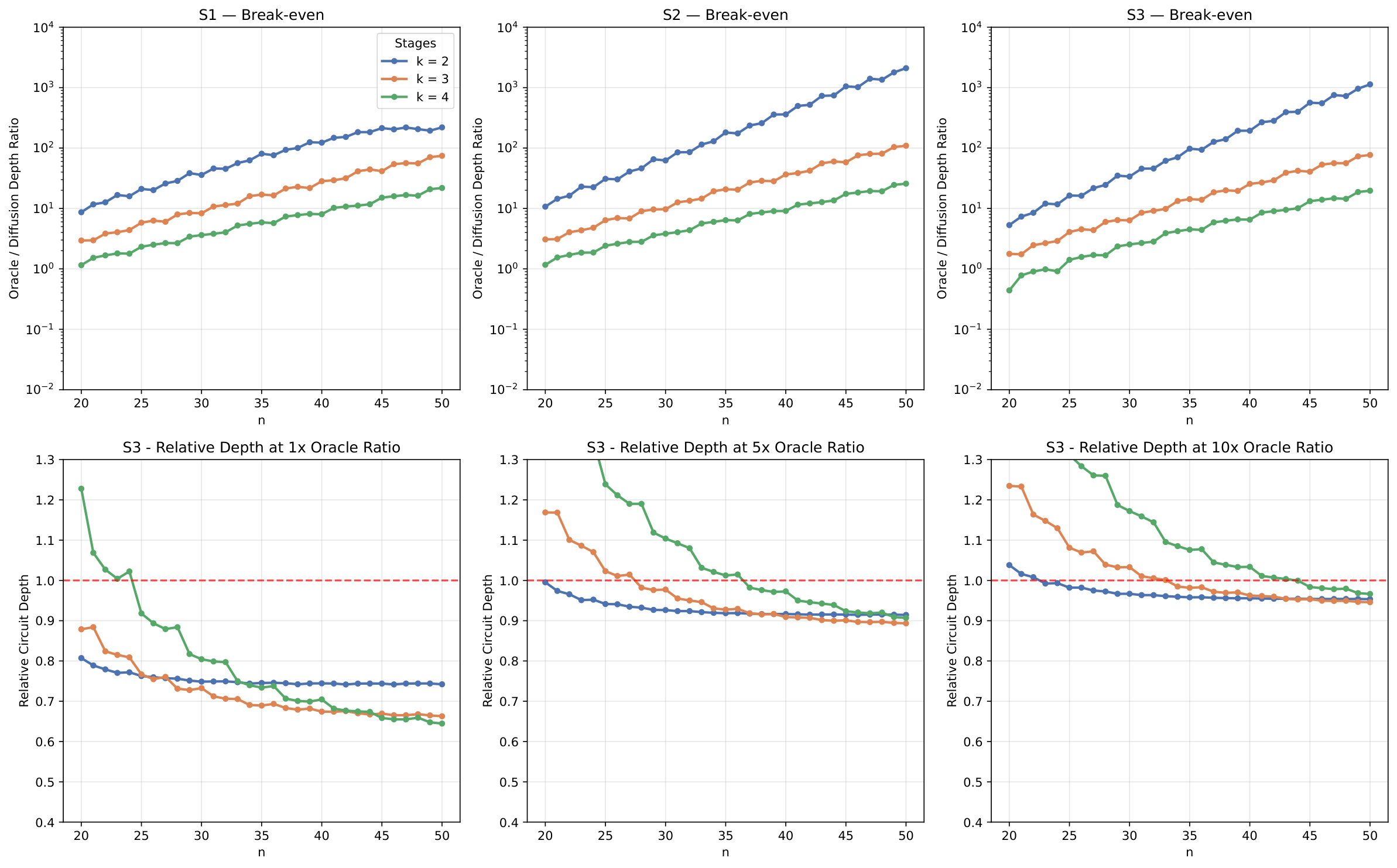
The depth comparison uses three MCX decomposition scenarios — S1 (no ancillae), S2 (idle qubits as dirty V-chain ancillae), and S3 (one clean ancilla) — and matches the Grover baseline to the same success probability. Under S1/S2 the 3-stage scheme reduces diffusion depth by 95–97% at 30% oracle overhead, the 2-stage by 81–96% at 9% overhead. Under S3 the advantage narrows but remains 51–63%. Crucially, the authors compute a break-even ratio — the oracle-to-diffusion depth ratio below which the recursive scheme wins on total depth — and find that for the 2-stage scheme this ratio is roughly 9–11×, comfortably above the AES-128 oracle/diffusion ratio (~10×) where the authors estimate a ~5% total-depth reduction.
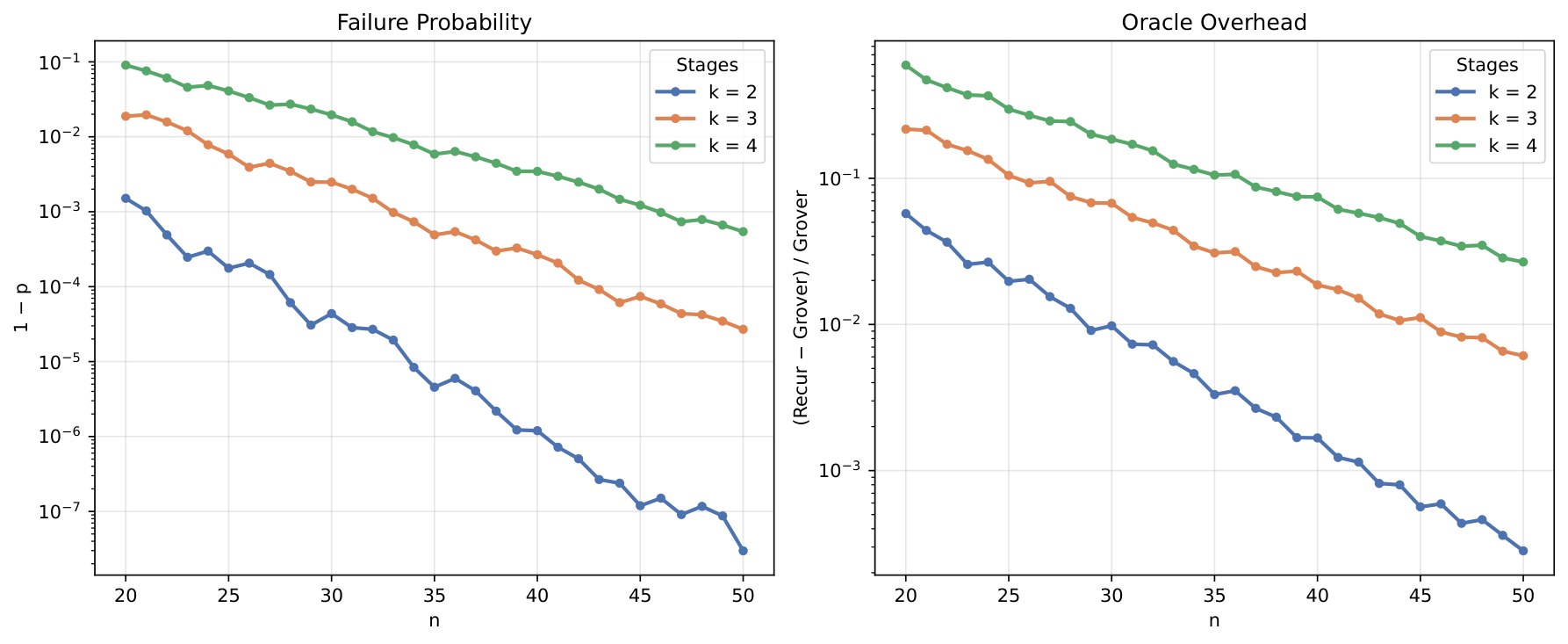
Section V scaling analysis extrapolates to n = 20–50 qubits. The failure probability and oracle overhead both decay rapidly with n for fixed stage count; conversely, more stages become viable at larger n. The crossover shown in Fig. 4 makes the practical engineering choice explicit: small n favours fewer stages, large n favours more stages.
The discussion (Sec. VI) raises three points worth flagging for Y4-style applications. First, the per-stage measurement overhead scales only with m, so for a 100-qubit problem partitioned into 10 stages of 10 the algorithm uses 9 mid-circuit measurements against ~250 oracle calls — negligible. Second, the algorithm is naturally distributed: all non-oracle operations stay within a node, only the oracle requires inter-node entanglement. Third, the construction only directly applies when A factorises; for cardinality-constrained Grover (Y4) the initial state is a uniform superposition over k-of-n bitstrings, which is not a tensor product — extending the analysis would require either an approximate factorisation or a redesigned per-register reflection that respects the cardinality constraint. The paper's "approximate tensor product decompositions" comment (Sec. VI, Limitations) is precisely the bridge that would be interesting to explore.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y4 (Grover + ADMM cardinality-constrained BO): closest match. Y4 builds a Grover-style algorithm with O(√(C(n,k)/M)) rotations over a structured feasible space (k-of-n bitstrings). Burke & Mc Goldrick's construction shows the non-oracle depth of any Grover-style scheme can be slashed when the state-preparation unitary factorises. Cardinality-state preparation does not factorise as a tensor product across a partition, so the result does not apply directly — but the underlying principle (degeneracy of principal angles → 2×2 scalar dynamics) is the kind of structural property worth checking for the Dicke-state preparation that Y4 uses.
- Y1 (iterative warm-started QAOA): shared method axis (iterative refinement of a quantum optimisation primitive) but Y1 is QAOA + measurement-based warm-starting; the new paper is Grover-amplification with recursive locality. The "exponential-eigenspace-collapses-to-2×2" observation in this paper is methodologically analogous to Y1's exploitation of measurement-induced structure to drive iteration — different mechanism, similar flavour.
- Y3 (QAOA DGMVP portfolio): only weakly aligned. Y3 is about end-to-end portfolio optimisation under noise; this paper is asymptotic algorithm design without a noise model. The depth-reduction results would matter to Y3 only if a Grover-style alternative to QAOA were on the table.
- Y2 (quasi-binary QAOA, hard mixer): Y2 uses encoding-aware mixers that preserve hard constraints. The new paper's locality-preserving reflections are an analogous structural move — designing the non-oracle operators to preserve a tensor structure — but on the Grover side rather than QAOA.
- Y5, Y6: no real overlap.
Recommended action for Yuan
- Read deeper. The principal-angle-collapse phenomenon (Subsec. III.B) is the technical novelty most likely to generalise. Specifically: does the same scalar-2×2 reduction hold when
Aonly approximately factorises, e.g., whenAprepares a Dicke state (cardinality-constrained uniform superposition)? If yes, this would slot directly into Y4's Grover-amplification step. - Adapt method for Y4 follow-up. The 5%–35% total-depth reductions at n = 50 (Fig. 3, bottom row) are exactly in the regime where Y4's hardware estimates live. A short numerical experiment substituting the recursive scheme into Y4's pipeline (assuming an appropriate tensor-friendly oracle) is a low-cost way to estimate whether the depth advantage carries through.
- Possibly cite in Y4 revisions / follow-up. If the depth-reduction principle survives the cardinality-constraint adaptation, this paper would be a natural reference for the "non-oracle cost" discussion that is usually glossed over in Y4-style works.