Quantum End-to-End Learning for Contextual Combinatorial Optimization
Abstract
Contextual combinatorial optimization (CCO) plays a critical role in decision-making under uncertainty, yet remains a significant challenge. We present Quantum End-to-End Learning (QEL), the first quantum computing-based end-to-end learning framework for CCO that leverages Quantum Approximate Optimization Algorithms. Inspired by the integration of state preparation and evolution in data re-uploading, we propose a context re-uploading phase-separator that jointly captures the complex relations among contexts, uncertain coefficients, and optimal solutions. This allows a contextual encoder to be seamlessly integrated within a quantum surrogate policy, enabling joint end-to-end training with a stationarity guarantee. Exploiting an optimization-aware structure grounded in physical principles that classical methods cannot readily leverage, our approach demonstrates practicality by directly training on task loss despite the discreteness and nonconvexity, while avoiding calls to NP-hard optimization solvers. QEL empirically achieves competitive performance while requiring substantially fewer parameters than classical benchmarks, highlighting its industrial-level potential for the future quantum era.
Executive summary
QEL is a hybrid quantum framework that fuses QAOA with data re-uploading to handle contextual combinatorial optimization — problems where the cost coefficients y are not known at decision time but a context x is. The novelty is a context re-uploading phase-separator: a context-dependent final Hamiltonian whose Ising weights are produced by a small linear or logistic encoder gw(x), then exponentiated inside each QAOA layer. The authors prove the QEL loss is equivalent to empirical risk minimisation of the task loss (Theorem 3.1) and that a diminishing-step parameter-shift SGD converges to stationarity (Theorem 3.2). Empirically on 16- and 25-variable MaxCut, QAP, and bipartite-matching instances, QEL matches or beats classical PnO baselines (LODL, List-LTR) with one to three orders of magnitude fewer trainable parameters. For Yuan, this is closely adjacent to Y2/Y3 — same QAOA-on-Ising machinery, but with the twist that the cost coefficients are learnt from context rather than supplied as data.
Main contribution
The paper's central technical move is replacing the fixed final Hamiltonian HF = ΣhiZi + ΣyijZiZj with a context-conditioned Hamiltonian ĤF = ΣhiZi + Σgw(xij)ZiZj, where gw is either linear (Eq. 13) or logistic (Eq. 14). Repeated phase-separator applications (the QAOA depth p) double as data re-uploading layers, so a single trainable parameter set φ = {θI, θF, w} encodes the predictor and the variational policy. Theorem 3.1 ("QEL as End-to-End Learning") shows that minimising the variational expectation of HF(y) against the QEL ansatz is exactly the empirical risk minimisation problem of contextual optimisation — eliminating the differentiation-through-solver headache that classical PnO approaches face for discrete decisions.
Key theorems / lemmas / algorithms
- Theorem 3.1 (QEL as End-to-End Learning): minimising the QEL variational loss L(φ) is equivalent to minimising the empirical risk (1/N)Σ C[πθ(x(l), gw), y(l)] over the stochastic policy induced by computational-basis measurement. Proof: since HF(y) is diagonal, the expectation equals an expected sampled cost.
- Theorem 3.2 (Convergence to stationarity): diminishing-step SGD with full-batch parameter-shift gradients satisfies E‖∇L(φt)‖² → 0 and trajectory stationarity almost surely, under regularity conditions R1–R4 (Appendix F).
- Proposition 3.3 (Equivalence of sampling): sampling bitstrings z and averaging f(z, y) yields the same expectation as ⟨ψ|HF(y)|ψ⟩, justifying test-time inference without access to true y.
- Algorithm 1 (training): parameter-shift gradient SGD over the QEL ansatz with Nshots measurements per training pair per epoch.
- Algorithm 2 (test-time): measure Nshots bitstrings from the trained circuit conditioned on x; decode via most-probable feasible bitstring.
Detailed walkthrough
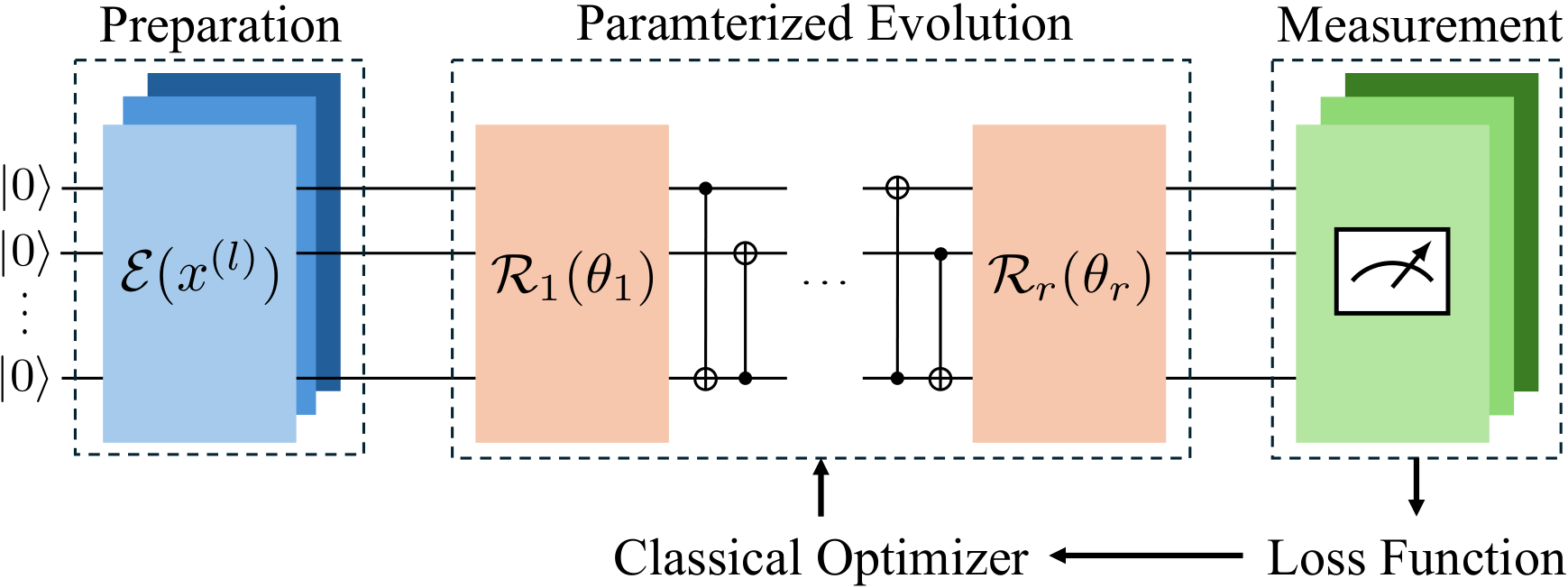
Section 2 (preliminaries) rehearses the variational principle and the adiabatic theorem, then formulates the standard Ising final Hamiltonian (Eq. 11) and observes that any QUBO reduces to it via Zi = 1 − 2xi. Standard QAOA territory — the value-add comes in §3.
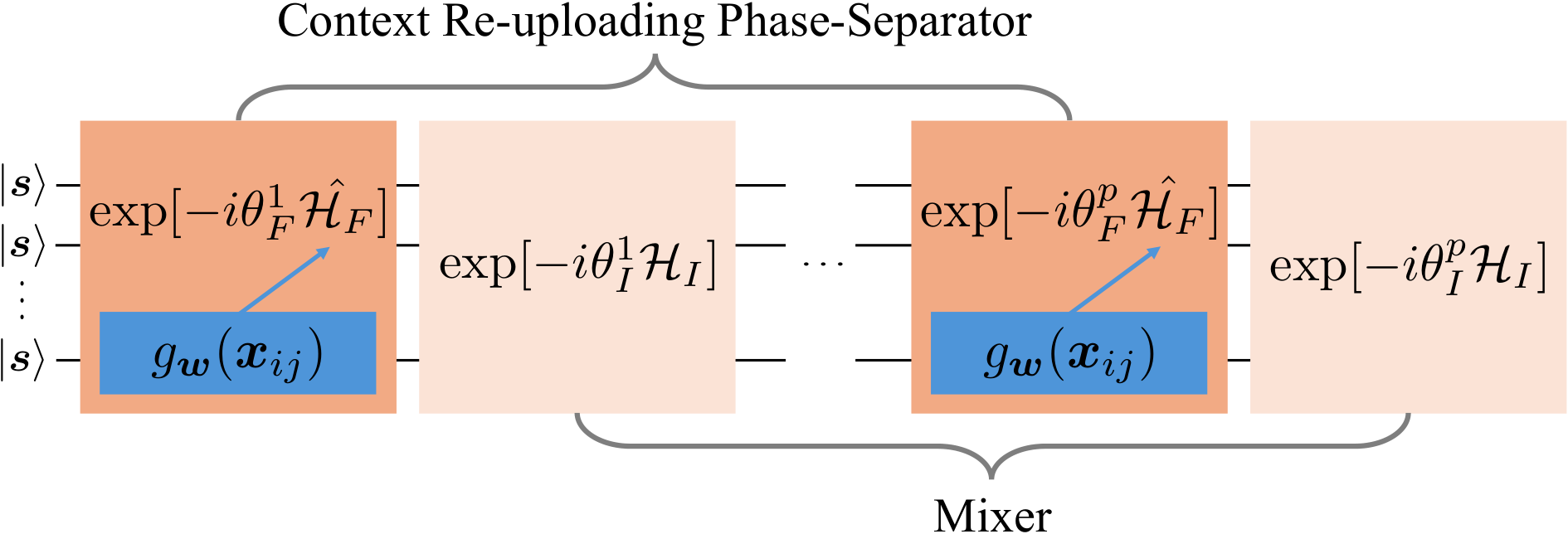
Section 3.2 (context re-uploading phase-separator) is the novelty. The authors note an awkward mismatch: QML uses fixed amplitude/kernel encodings; QAOA strictly requires the equal-superposition initial state. Conventional contextual-optimisation pipelines therefore cannot plug an ML predictor into the QAOA circuit. Their fix is to embed the contextual encoder inside the phase-separator. Each phase-separator application exp[−iθFk ĤF(gw(x))] simultaneously (i) injects edge-level context features xij and (ii) advances the variational evolution. Because the angle θFk is bounded by the parameter-shift mechanics, they argue a logistic encoder (Eq. 14) — saturating in [0, w0] — better matches the rotation-angle range than a raw linear encoder. Depth p doubles as the data re-uploading count.
Section 3.3 (training and test-time process) ties the construction to empirical risk minimisation. The proof of Theorem 3.1 is two lines but conceptually important: because HF is diagonal in the computational basis, ⟨ψ|HF(y)|ψ⟩ = Ez∼π[f(z, y)], so the variational principle's lower-bound objective is exactly a policy-gradient-style expected cost. They use full-batch parameter-shift gradients (Schuld 2019; Wierichs 2022). Theorem 3.2 deferes regularity conditions to Appendix F; the key claim is that despite finite-shot stochasticity, diminishing step sizes (Robbins-Monro conditions: Σηt = ∞, Σηt² < ∞) recover both expected-norm and almost-sure stationarity.
Section 4 (experiments) uses three problems at 16 and 25 variables: MaxCut, QAP, and a bipartite-matching variant (BMP) from Elmachtoub & Grigas. Constraints are handled by penalty terms (the authors flag constraint-preserving mixers as future work — this is a key point of contact with Y2). Baselines are LODL (Shah 2022) and List-LTR (Mandi 2022). The headline results (Table 1): on MaxCut-25V, QEL-Log p=4 achieves 4.21% regret with 13 parameters versus LODL's 8.88% with 30,188 parameters — a 3-order-of-magnitude parameter reduction at half the regret. QAP results are mixed (LODL wins on QAP) but the parameter ratio is similar. For BMP-25V (the constrained problem), QEL-Log p=4 hits 60% relative regret versus 80% for LODL, but neither is competitive in absolute terms — penalisation hurts both. Increasing p from 3 to 4 generally lowers regret, consistent with QAOA → adiabatic in the p→∞ limit. QEL-Log dominates QEL-Lin everywhere, suggesting nonlinear context encoders matter.
Section 5 (conclusion) calls out constraint-preserving mixers, higher-order objectives, and real-hardware validation as immediate follow-ups. The authors do not benchmark on noisy simulators or actual NISQ devices — all results are noiseless GPU statevector simulation. For Yuan's portfolio-optimisation lineage (Y3) which extensively studied thermal-relaxation regimes, this is a notable gap.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (warm-started QAOA, MaxCut, iterative warm-starting): direct adjacency. Both papers use QAOA on MaxCut-type problems and exploit structure of the parameter landscape (Y1 via measurement-based warm-starting, QEL via a learned encoder absorbing context). QEL is parameter-light but pays no attention to warm-start initialisation; combining QEL's encoder with Y1's iterative warm-start could be a clean methodological hybrid.
- Y2 (quasi-binary encoding + hard mixer, portfolio): the paper explicitly cites constraint-preserving mixers as the natural successor — Y2's hard-mixer machinery would slot directly into QEL for QAP and BMP. QEL uses penalty terms throughout, which the authors acknowledge as a limitation. Direct extension target.
- Y3 (QAOA DGMVP portfolio, layerwise optimisation): closest in spirit but for contextual data rather than fixed covariance. The optimisation methodology (parameter-shift SGD, no warm-start, no layerwise schedule) is more naive than Y3's dual-annealing + layerwise pipeline. Y3's robust optimiser comparison would likely strengthen QEL — and a head-to-head on contextual DGMVP would be informative.
- Y4 (Grover + ADMM cardinality): tangential — different algorithmic family. QEL handles cardinality only through penalty terms; Y4's exact feasibility via Grover would solve QEL's BMP-feasibility problem cleanly.
- Y5 (Pauli-sparse Gibbs SDP): no overlap on method.
- Y6 (PBR / hardware): no overlap.
Recommended action for Yuan
- Adapt method: the context re-uploading phase-separator is a natural ingredient for a contextual variant of Y3's portfolio QAOA — replace the fixed covariance matrix with gw(x) conditioned on contemporaneous market features. The implementation cost is low (QEL is essentially Y3's circuit with one extra trainable map per edge) and the result would be a contextual DGMVP — likely publishable.
- Read deeper: Appendix F (regularity conditions and Lemma F smoothness) — Yuan's portfolio work uses dual annealing rather than SGD, so the stationarity guarantees do not transfer directly, but the parameter-shift smoothness lemma may inform layerwise optimiser design.
- Consider citing in next draft: as the "first QC framework for CCO", QEL is a natural reference whenever Y3-lineage portfolio work is extended to feature-aware regimes.