Pauli Correlation Encoding for mRNA Secondary Structure Prediction: Problem-Aware Decoding for Dense-Constraint QUBOs
Abstract
Pauli Correlation Encoding (PCE) compresses m binary variables onto n = O(m1/k) qubits for a tunable compression order k ≥ 2 by mapping them to commuting Pauli correlators, but the continuous expectation values it produces must be decoded into feasible binary solutions, a challenge that becomes acute for problems with dense constraints. We apply PCE to the mRNA secondary structure prediction problem, formulated as a densely-constrained QUBO. We train throughout with a QUBO-space sigmoid loss that preserves the QUBO penalty structure directly. For decoding, we introduce the Problem-Aware Guided Decoder (PAGD), which scores candidate variable commitments by the product of their marginal QUBO energy reduction and a trained expectation-value prior, with constraint-aware feasibility pruning at each step. On six benchmark mRNA sequences (30–60 nt, 50–240 variables, 7–14 qubits), PAGD with 100 restarts achieves 75–100% near-optimal recovery, defined as P(gap<1%), for sequences up to m=152 variables, vs. 0–30% for the sign-rounding+local-search baseline. We demonstrate that PCE-trained expectation values provide a useful prior. Hardware-scale tests extend the pipeline to three 102–105 nt instances (694–745 variables, ~190 000 pair constraints, 23 qubits) on IBM Heron processors. The circuits transpile SWAP-free into 480 native two-qubit gates at depth 256, and PAGD-decoded gaps on QPU runs match or beat simulator means for all three instances, including exact CPLEX-optimum recovery for one sequence.
Executive summary
Friedhoff et al. apply Pauli Correlation Encoding (PCE) — a polynomial-compression scheme mapping m classical bits to ~m1/k qubits via commuting Pauli correlators — to densely constrained QUBOs, specifically mRNA secondary structure prediction. PCE's central pain point is decoding: continuous expectation values must be rounded to feasible binary strings, which is hopeless under dense pairwise constraints. Their contribution is a Problem-Aware Guided Decoder (PAGD) that interleaves marginal-energy reduction with feasibility pruning, plus a QUBO-space sigmoid loss that preserves the penalty structure during training. The pipeline scales: 745-variable mRNA folds on 23 qubits of an IBM Heron device, transpiled SWAP-free to a heavy-hex subgraph, and hardware results match simulator on all three biological-scale sequences. For Yuan, this is a parallel to Y2 in spirit (compressed encoding for hard-constrained binary optimisation) but a substantially different mechanism — and a Y6-class hardware demonstration on Heron.
Main contribution
Three pieces. (i) A QUBO-space sigmoid loss: rather than training PCE expectation values in Ising space and post-hoc decoding, they push the loss into QUBO space directly by mapping each Pauli correlator through a sigmoid into a [0,1] continuous relaxation of the binary variable, then evaluating the QUBO penalty exactly on that relaxation. This preserves the penalty structure (rather than smearing it through a hyperbolic-tangent change of variables). (ii) A Problem-Aware Guided Decoder (PAGD): at each step, score every still-unfixed variable's commitment to 0 or 1 by the product of its trained expectation-value prior and the marginal QUBO energy reduction it would provide, with hard pruning of choices that violate dense constraints. (iii) Hardware-aware Informed-k ansatz topology: choose entangling-pair edges by ranking QUBO-importance pairs and routing the resulting maximum spanning tree onto the device's heavy-hex coupling map, padding with native heavy-hex edges. Result: SWAP-free transpilation to 480 native two-qubit gates at depth 256 on 23 qubits, end-to-end deployable on IBM Heron.
Key results / experimental protocol
- PCE compression: m binary variables → n = O(m1/k) qubits with compression order k ≥ 2. They use k = 2 and k = 3 in different regimes; n = 7–14 for benchmark sequences (m = 50–240).
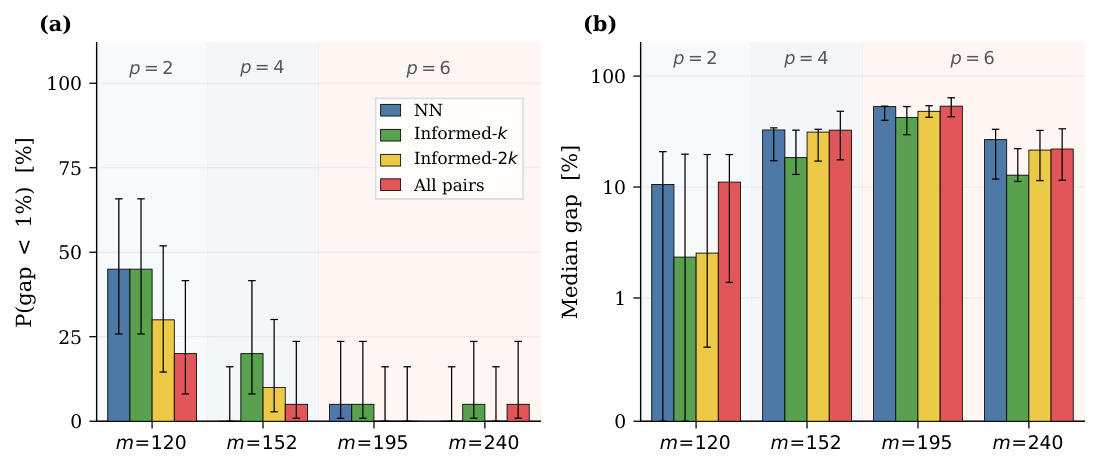
- Ansatz topology (Sec. Results — Ansatz Topology): four topologies compared — NN (nearest-neighbour), Informed-k (top-k QUBO-weighted pairs), Informed-2k, plus a hardware-aware variant. Informed-k dominates on simulator across 20 random seeds; hardware-aware Informed-k is used for QPU deployment.
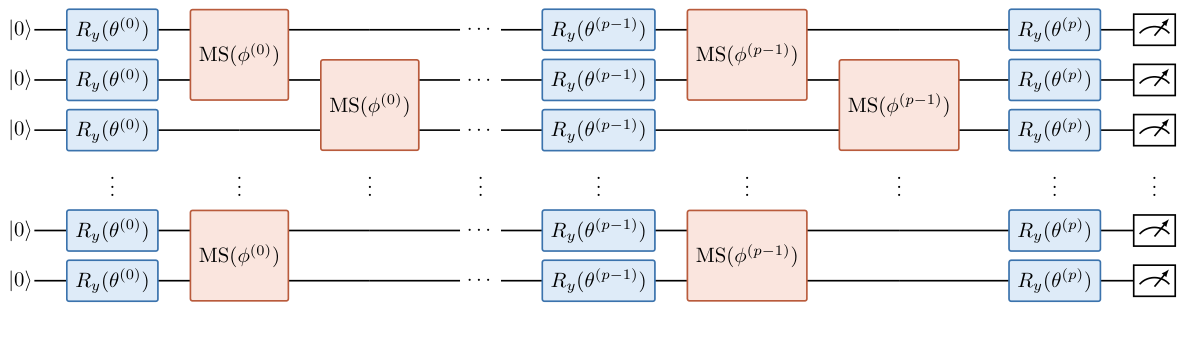
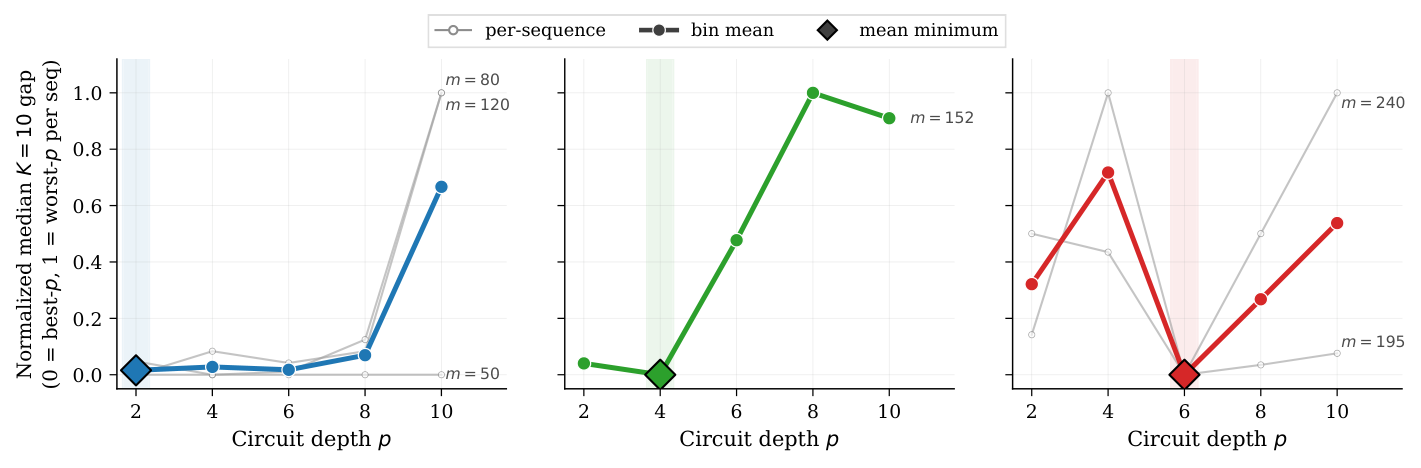
- Depth selection (Sec. Circuit-Depth Selection): optimal p depends on size — p=2 for m ≤ 120, p=4 for m=152, p=6 for m=195/240. Layerwise parameterisation: a single Ry angle θ(ℓ) and single MS angle φ(ℓ) per layer, giving 2p+1 trainable parameters total — the layerwise parameter sharing is the key to depth scalability.
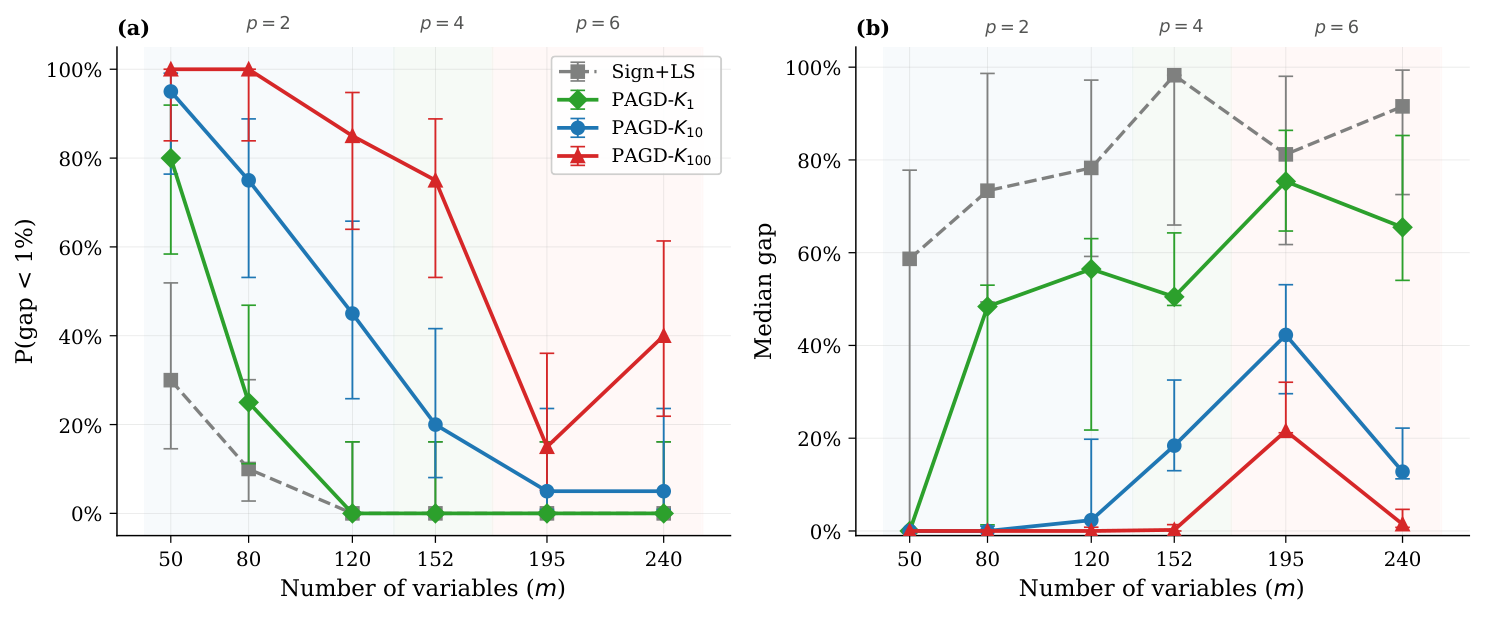
- Decoder comparison (Sec. Decoder Comparison): on 6 benchmark sequences, PAGD-K100 achieves 75–100% P(gap<1%) for m ≤ 152, vs. 0–30% for sign-rounding + local-search baseline. Median optimality gaps drop by an order of magnitude.
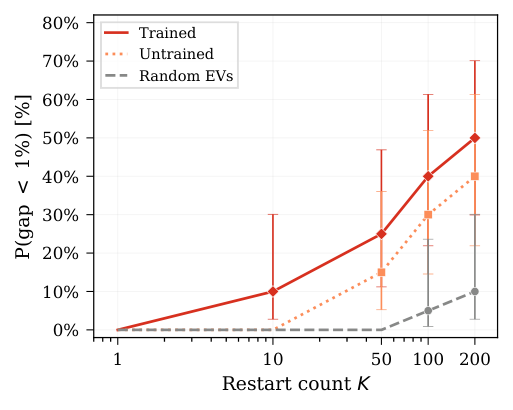
- Trained-prior ablation (Sec. Restart Budget): on seq_240 (m=240, n=14), trained-PCE PAGD reaches 50% P(gap<1%) at K=200 restarts, outperforming untrained-circuit by 10 pp and random-EV by 40 pp.
- Hardware (Sec. Hardware-Scale Results): three biological sequences (102–105 nt, 694–745 variables, 172k–193k pair constraints) on IBM Heron (ibm_aachen, 23-qubit subgraph). SWAP-free transpilation, 480 2-qubit gates, depth 256. PAGD decoded gaps match or beat simulator means; exact CPLEX recovery on one sequence.
Detailed walkthrough
The setup (Sec. Introduction). mRNA secondary structure prediction is formulated as a Sankoff-style QUBO with O(m²) pairing variables and dense constraints (no two pairs may share a base, no pairs may cross). Densely constrained QUBOs are the worst case for any naive expectation-value decoder: a small expectation error per variable compounds into infeasibility almost surely.
PCE compression and the decoding problem (Sec. Methods). PCE maps binary variable xi to an expectation ⟨Pi⟩ of a commuting Pauli correlator. With k qubits per "block", up to ~3k commuting correlators can be defined. Training optimises the circuit parameters so that the correlator expectations approximately match the optimal binary assignment. The hard part is decoding: a continuous [-1,1] expectation does not directly yield a feasible bitstring under dense constraints. The naïve sign-rounding baseline almost always lands infeasible.
Loss in QUBO space (Sec. Training Loss). Rather than the standard Ising-space penalty (which sees the encoded variables as continuous Ising spins and applies the quadratic cost), the authors apply a sigmoid σ to each correlator to push it onto [0,1] (a relaxation of the binary variable), and evaluate the QUBO penalty exactly on this [0,1] relaxation. This means soft-feasibility violations are surfaced during training, not just at decoding. A theoretical analysis shows the QUBO-space loss preserves the penalty structure (sharp barriers around feasibility) while the Ising-space loss flattens them.
The Problem-Aware Guided Decoder (Sec. Decoding Schemes). Greedy with feasibility lookahead. Start from the fully unfixed problem. At each step, for each (unfixed variable i, candidate value v ∈ {0,1}) pair, compute score(i,v) = prior(i,v) × ΔEQUBO(i,v) where prior comes from the trained expectation, and ΔEQUBO is the marginal QUBO-energy reduction. Then check feasibility — if committing xi=v would force a constraint violation under any feasible completion, prune; otherwise commit greedily. Restart K times from different random orderings/break-ties to get an empirical decoded-gap distribution.
Ansatz design (Sec. Methods — Problem-Informed Ansatz). Layerwise parameter sharing keeps the parameter count at 2p+1 regardless of qubit number, making COBYLA optimisation tractable. The Informed-k topology connects the top-k QUBO-importance pairs, picking up the most relevant problem structure with the fewest entangling gates. Hardware-aware variant routes this onto the device's heavy-hex coupling map: 22 of 22 informed pairs land natively, 2 padding edges add unavoidable heavy-hex constraints.
Results — simulator (Sec. Results). Across 20 seeds per configuration, the PAGD + Informed-k + layerwise pipeline outperforms every ablation by a wide margin. The improvement comes from (a) the QUBO-space loss training, (b) the PAGD feasibility pruning, and (c) the multi-restart aggregation. Fig. 4 isolates each contribution; trained EV is the single largest factor.
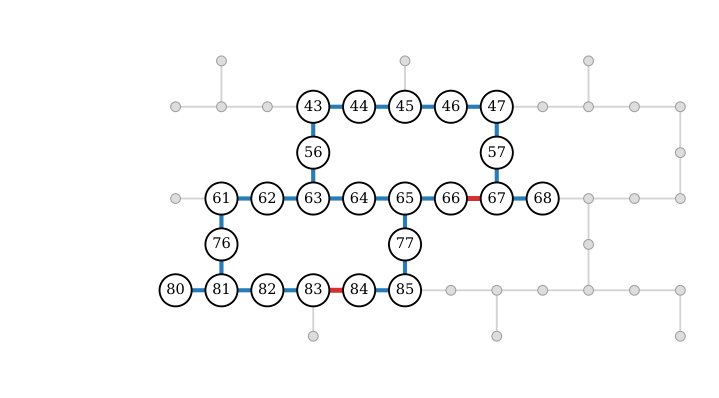
Results — hardware (Sec. Hardware-Scale Results). On three real mRNA sequences (102–105 nt, 694–745 variables, 23 qubits on ibm_aachen), the QPU samples are decoded by PAGD and yield gaps that match or beat the simulator's mean for all three instances, with exact CPLEX optimum recovered on one. The SWAP-free transpilation is achieved by aligning the Informed-k spanning tree to the heavy-hex coupling map. Depth is 256, well within Heron's coherence budget. Fig. 6 shows the 23-qubit subgraph used; Fig. 7 shows the lowest-energy folds for all benchmark sequences.
Figures

Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary encoding + hard XY mixer): closest peer — both papers compress m binary variables onto fewer qubits to bring constrained problems within near-term reach. Y2 uses a quasi-binary encoding (~2 log2(U−L+1) qubits per variable) with a hard mixer that preserves feasibility by construction; PCE uses m1/k qubits but no hard mixer — feasibility is enforced post hoc via PAGD. Direct comparison of the two encodings on a portfolio QUBO would be a natural Y2 follow-up.
- Y3 (DGMVP portfolio QAOA + layerwise opt): the layerwise parameter sharing (2p+1 parameters at depth p) is exactly the layerwise scheme Y3 identifies as most robust for portfolio QAOA. The "Informed-k" idea of QUBO-importance-weighted entangling pairs would be worth porting back to the DGMVP setting.
- Y4 (Grover for cardinality-constrained BO + ADMM hybrid): different mechanism but same target — feasibility under dense binary constraints. Y4's ADMM splits problem structure; PAGD does a greedy feasibility-aware decoder. Comparing on the same instance set would clarify the depth-vs-shots vs. classical-greedy-pruning trade-off.
- Y6 (PBR test on IBM Heron2): both run on Heron-class IBM hardware; this paper achieves SWAP-free transpilation on a 23-qubit subgraph at depth 256 — useful operational data points for Y6-style hardware analysis.
- Y1, Y5: weaker overlap (no warm-starting; no SDP/Gibbs).
Recommended action for Yuan
- Compare PCE vs. quasi-binary encoding (Y2) on a portfolio QUBO: both encodings target the same compression goal but with different feasibility-handling philosophies. A side-by-side benchmark on the DGMVP instance set of Y3 would be publishable as a dedicated encoding-comparison study.
- Adapt PAGD as a feasibility-aware classical post-processor for Y2's CVaR-QAOA portfolio results: even if the hard mixer keeps you in the feasible Hamming-weight sector, dense additional constraints (e.g. risk-bound chance constraints) could benefit from PAGD-style decoding.
- Read the layerwise parameter-sharing claim carefully — Y3 already advocates layerwise; this paper provides an independent validation on a different problem class.