Efficient Fourier-Based Linear Combination of Unitaries and Applications in Quantum Optimization
Abstract
We investigate ancilla-free linear combination of unitaries (LCU) as a framework for approximating complex quantum circuits. This is particularly effective for quantum optimization algorithms, where candidate solutions can be evaluated classically and the task is to sample high-quality bitstrings rather than reproduce the full output distribution. We show that Fourier-based LCU constructions efficiently decompose broad classes of diagonal and non-diagonal unitaries, replacing highly connected qubit interactions with single-qubit gate layers or significantly simpler structures at the cost of a polynomial sampling overhead. Applied to algorithms such as QAOA, this yields efficient, hardware-friendly decompositions of, for instance, cardinality-constraint penalties and the fully connected XY-mixer, while maintaining rigorous performance guarantees compared to fully coherent implementations. Furthermore, we establish a formal connection between Fourier-based quantum penalties and Lagrangian relaxation, offering a unified perspective on constraint handling. We validate our approach using exact statevector simulations of 12-qubit circuits and large-scale experiments on 106 superconducting qubits.
Executive summary
Carrera Vazquez, Egger, and Woerner (IBM) present an ancilla-free Fourier-based LCU approximation for quantum optimization that recasts highly-connected operators (cardinality penalties, fully-connected XY mixers) into a sum of much simpler unitaries that are sampled classically run-by-run rather than coherently summed via an ancilla. The scheme exchanges circuit depth/connectivity for a polynomial sampling overhead and comes with rigorous performance guarantees relative to the coherent QAOA. They run a 106-qubit densest-k-subgraph (DkS) experiment on an IBM Heron-class device and a 12-qubit benchmark with both penalty and XY-mixer constructions. For Yuan, this is one of the most directly relevant papers of the cycle: the cardinality-constraint penalty + XY mixer combination is exactly the constraint regime of Y2 (quasi-binary portfolio) and Y4 (Grover for cardinality), and the IBM 106-qubit demonstration shares the noise regime of Y3.
Main contribution
The paper formalises an ancilla-free LCU sampler: a target unitary U is written as a (signed) convex combination U = Σj αj Vj of cheap basis circuits, and one stochastically draws Vj per shot, post-processing measurement outcomes by classical re-weighting. They build a Fourier-LCU library: diagonal unitaries diag(eiφ(x)) get truncated Fourier series in the bit-pattern, and non-diagonal permutation-invariant unitaries (e.g. XY mixers acting on a Hamming-weight sector) decompose via SU(2) Fourier modes. The penalty version replaces costly all-to-all RZZ ladders for the (Σxi−k)² cardinality term by Z-only LCU layers; the XY-mixer version replaces the fully-connected complete-bipartite XY graph by O(N) RZRY circuits. The sampling overhead is controlled by the "1-norm" of the LCU coefficients ΓU, which they bound polynomially. They also prove a formal correspondence between the Fourier-penalty parameter and Lagrangian-relaxation multipliers — i.e. each shot effectively realises a different Lagrangian relaxation, and the average reproduces a soft constraint.
Key theorems / lemmas / algorithms
- LCU sampling lemma: for U = Σj αj Vj, sampling Vj with probability ∝ |αj| and re-weighting by sign(αj) gives an unbiased estimator of any diagonal observable expectation with variance overhead ΓU² = (Σ|αj|)² (Sec. 2, ancilla-free LCU).
- Fourier decomposition of diagonal cost unitaries (Sec. 3): truncating the Fourier series of eiγ·φ(x) at degree D gives an LCU with D+1 basis unitaries, each consisting of single-qubit RZ rotations only — replacing all-to-all ZZ ladders.
- Fourier-LCU for permutation-invariant non-diagonal unitaries (Sec. 4): explicit construction for the fully connected XY-mixer on the Hamming-weight-k sector — basis circuits consist of single-qubit RY/RZ rotations after a Hadamard layer.
- Constraint–Lagrangian correspondence (Sec. 5): each Fourier coefficient corresponds to a Lagrangian multiplier; averaging the per-shot Lagrangian-relaxed problem reproduces the original constrained QAOA expectation.
- Performance theorem: for sampling tasks, the LCU sampler with ΓU sampling overhead inherits the coherent QAOA's approximation-ratio guarantee with a multiplicative factor 1/ΓU on tail probabilities (App. C).
Detailed walkthrough
Setup (Sec. 2). The authors observe that QAOA's job is not to reproduce a coherent output state — only to sample good bitstrings. So a unitary U only needs to be implemented in a way that yields the same diagonal measurement statistics, which is exactly what an LCU+stochastic post-selection accomplishes without an ancilla. Concretely: pick Vj with probability |αj|/Γ, run, measure bitstring x, and weight the empirical estimator by sign(αj). The variance overhead is Γ², making this a depth-vs-shots trade.
Diagonal Fourier (Sec. 3). A penalty term λ·(Σixi−k)² generates a unitary that, in the computational basis, has phases φ(x) = λ(s−k)² where s is the Hamming weight. They write eiγφ as a Fourier series in s, truncate at degree D, and obtain an LCU whose basis circuits are products of single-qubit RZ(γd) — no two-qubit gates at all. Γ scales polynomially in D, and D required for fixed accuracy scales gracefully with system size. This is the central technical move: a hard, all-to-all penalty becomes a stack of single-qubit gates, at the cost of polynomially more shots.
XY-mixer Fourier (Sec. 4 + App. D). The hard XY-mixer constructed from the fully connected XY graph preserves Hamming weight (the cardinality-constraint feasible space) but normally requires O(N²) ladder of RXX+YY gates. The authors give a Fourier-on-SU(2) decomposition that realises the same mixer on the symmetric subspace using O(N) basis circuits of single-qubit RY/RZ after a column of Hadamards. They handle initialisation in the Hamming-weight-k sector via a warm-started Dicke-state preparation (citing Egger 2021).
Lagrangian unification (Sec. 5). A surprising structural result: in expectation, the Fourier-LCU penalty is equivalent to averaging over a family of Lagrangian relaxations of the constrained problem, each with a different multiplier drawn from the Fourier coefficients. So the sampler simultaneously explores a continuum of penalty strengths — a form of automatic Lagrange-multiplier search.
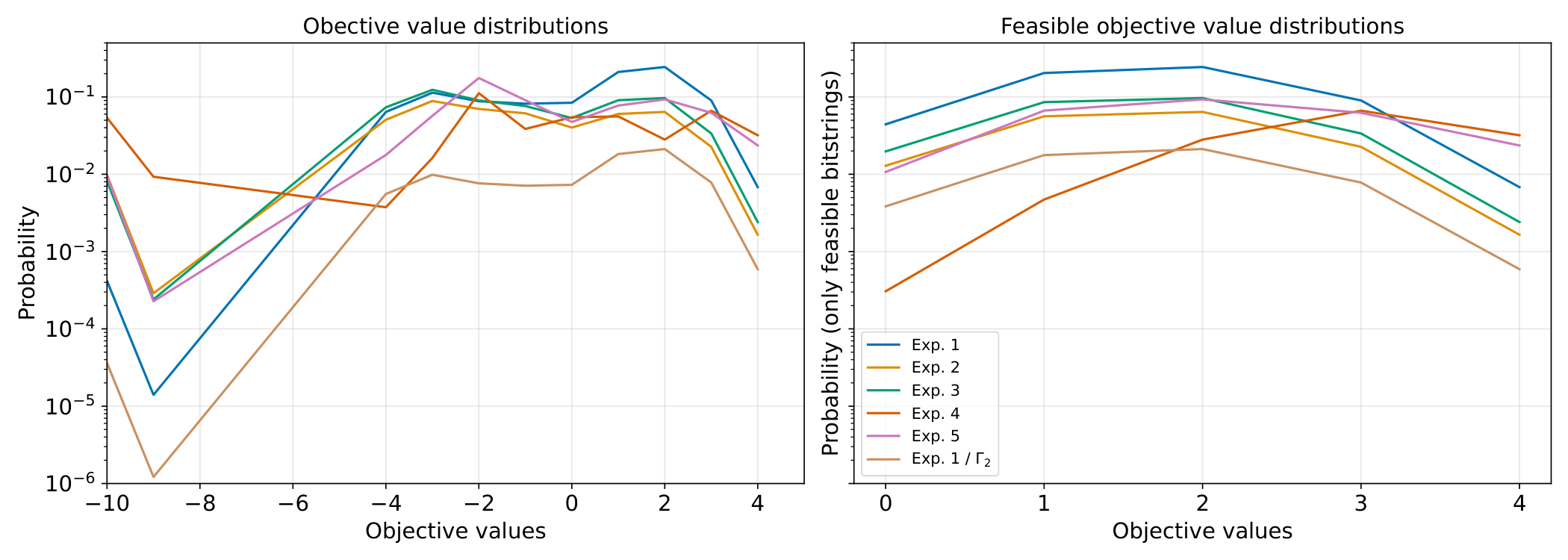
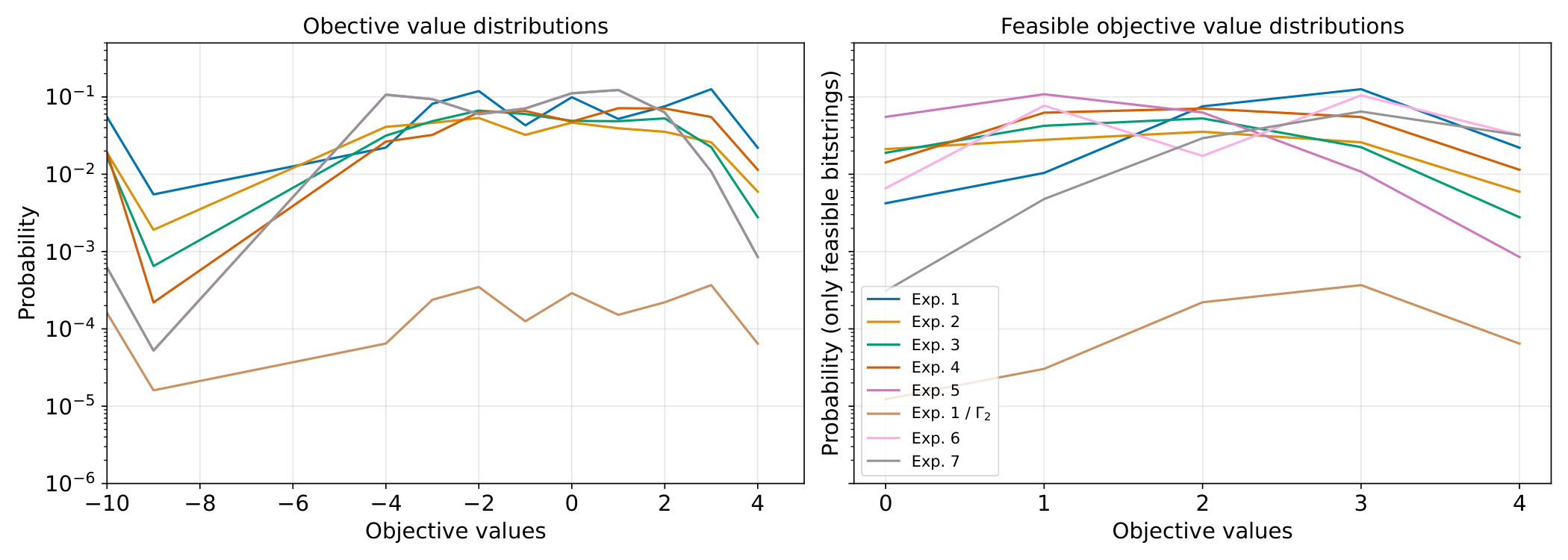
Numerical validation — 12 qubits (Sec. 6.1–6.2). Densest-k-subgraph (DkS, k=4) on a 3-regular 12-node graph. Three experiments per construction: full coherent, truncated LCU, and a comparison using CVaR sampling. Distributions of objective values and of feasible-only subsets show the LCU's Γ-scaled distribution overlaps the coherent distribution remarkably tightly — confirming the theory empirically. The XY-mixer variant restricts samples to the cardinality-feasible sector by construction; the penalty version uses an Egger-style warm-started initialisation followed by the LCU penalty layer.
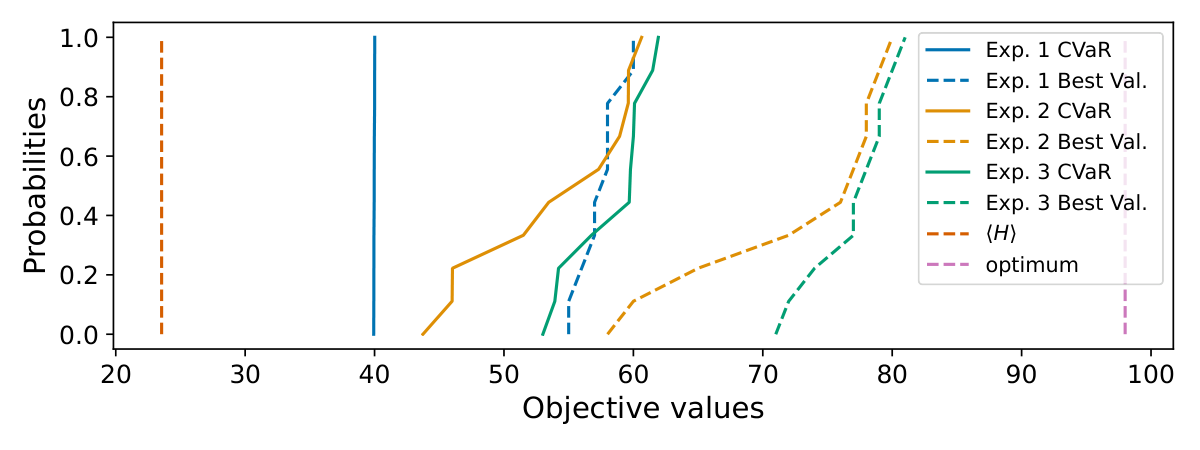
Hardware — 106 qubits on heavy-hex (Sec. 6.3 + App. F). A 5×3 SWAP-extended heavy-hex graph yields a 106-node DkS instance solved on an IBM Heron-class device. They compare CVaR distributions across ten repetitions with the coherent analytical expectation and CPLEX optimum. The LCU approach reaches CVaR within a small factor of the coherent expectation and finds high-quality bitstrings — concretely demonstrating that the depth reduction translates to noise-robustness on real hardware. The best found solution on hardware (highlighted on the device graph in Fig. 8) is very close to CPLEX's optimum (Fig. 9).
Appendices. A: Hilbert-space decomposition justifying the symmetric-sector restriction. B: continuous LCU on SU(2). C: bounding ΓU. D: full XY-mixer LCU construction. E: additional applications — Erdős–Rényi MaxCut, skewed Sherrington–Kirkpatrick, Maximum Independent Set with indicator penalties, and index tracking with risk constraints (essentially a portfolio-style problem). The appendix demonstrating index tracking with risk constraints is unusually relevant — it brings the LCU technology directly into the portfolio-optimisation regime (Y2/Y3).
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (warm-started iterative QAOA): the paper uses warm-started initial states (cited as Egger 2021) for both penalty and XY-mixer constructions — same Egger-school warm-start idea Yuan extends in Y1. The LCU technique is complementary to iterative warm-starting and can be composed with it.
- Y2 (quasi-binary encoding + hard XY-mixer for portfolio): directly parallel — Y2 builds hard mixers that preserve cardinality without penalties; this paper gives an alternative compilation of the same fully-connected XY hard mixer that drastically reduces two-qubit gate count. Combining Y2's quasi-binary encoding with this paper's Fourier-LCU mixer is a concrete proposal worth attempting.
- Y3 (DGMVP portfolio QAOA, layerwise opt, shot-noise scaling): the appendix on index tracking with risk constraints is essentially a portfolio-tracking problem; the LCU sampling overhead language fits naturally with Y3's shot-noise-scaling framework. The 106-qubit hardware demonstration is in the same noise regime Y3 analyses.
- Y4 (Grover + ADMM for cardinality-constrained BO): shares the cardinality-constraint scope but uses LCU sampling instead of Grover amplification. Yuan's ADMM hybrid splits problem structure differently — these are complementary depth-vs-shots trade-offs.
- Y5 (Pauli-sparse Gibbs states, SDP dequantisation): indirect — both papers exploit structural sparsity (Fourier decomposition vs. Pauli sparsity) to reduce coherent resources at the cost of classical sampling.
- Y6 (PBR on Heron2): shared hardware platform (Heron-class IBM device, 106 qubits) and shared noise-regime understanding.
Recommended action for Yuan
- Cite in next portfolio/QAOA draft: this is the most direct competitor to Y2's quasi-binary + hard-mixer approach as a constraint-handling technique on near-term hardware; benchmarking the two side-by-side on the DGMVP instances of Y3 would make a strong follow-up paper.
- Read App. E "Index tracking with risk constraints" carefully: it is a portfolio-style problem and Yuan's CVaR-QAOA + DGMVP machinery is the natural comparison baseline; consider whether the LCU sampling overhead actually beats Y2/Y3's resource counts.
- Email Egger/Woerner: they are explicit collaborators of the warm-start school Yuan builds on (Y1); a discussion combining iterative warm-starting (Y1) with Fourier-LCU XY-mixer compilation would be mutually useful.