A Penalty-Free Pipeline for Direct Quantum-Annealer Portfolio Optimization
Abstract
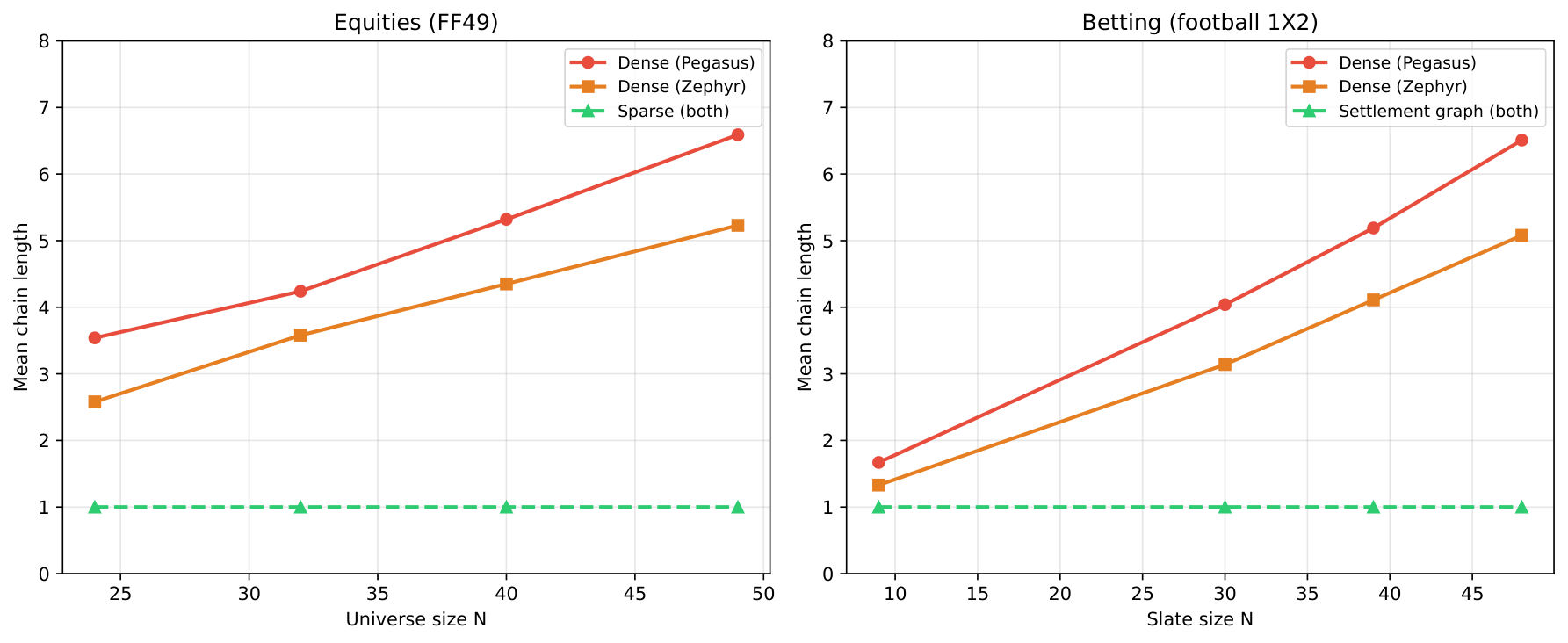
Direct quantum-annealer portfolio optimization is commonly formulated as a penalty-encoded QUBO and submitted to D-Wave hardware. We show that this standard formulation fails on current devices and identify the structural reason: the cardinality penalty contributes a dense rank-one term proportional to the all-ones matrix that makes the logical interaction graph complete regardless of the covariance structure. On Pegasus and Zephyr, chain-break fractions reach 83 percent at N equal to 24 and 92 percent at N equal to 49, producing no feasible samples. Attempting to fix this through topology-aware sparsification reveals a second problem: any sparsifier that removes off-diagonal entries also dilutes the cardinality constraint, so raw samples remain infeasible even when chains no longer break, and an ablation shows that for structurally favorable cases such as betting with settlement-graph priors the classical feasibility projector alone explains the result rather than the QPU. We propose dropping the penalty entirely: build an objective-only QUBO from the expected returns and the risk-scaled covariance, sample it on hardware, and enforce the cardinality constraint classically as a post-processing step. On D-Wave Advantage and Advantage2 for equities up to N equal to 49 and betting up to N equal to 48, mean chain-break fractions per sample averaged over reads drop from the range of 71 to 92 percent down to at most 0.04 percent. The QPU returns lower-energy feasible portfolios than the greedy heuristic on betting at N equal to 39 and 48, which is an energy comparison and not a proof of optimality, and the equity post-processed regret is at most 0.03 percent at all tested scales. These results establish that the penalty encoding, not the sparse hardware topology, is the binding constraint for direct QPU portfolio optimization at currently accessible scales.
Executive summary
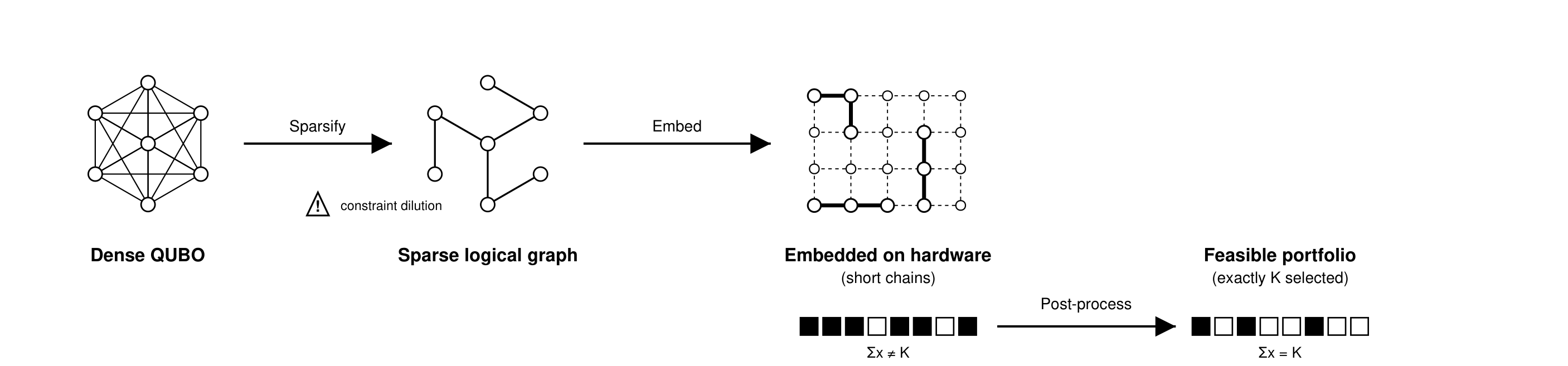
This paper diagnoses why the standard penalty-encoded cardinality-constrained portfolio QUBO fails on D-Wave hardware (the rank-one penalty term A·1·1ᵀ makes the logical graph complete regardless of the covariance structure), shows that the obvious fix (topology-aware sparsification) creates a second failure mode (constraint dilution), and proposes a penalty-free pipeline: objective-only QUBO on hardware + classical cardinality projection. Chain-break fractions drop from 71–92% (penalty) to ≤ 0.04% (penalty-free) on Pegasus and Zephyr up to N = 49 equities and N = 48 betting. This is the closest method-level match in today's batch to Yuan's Y2: both papers independently identify the cardinality penalty as the structural bottleneck and respond by removing it (Y2 via hard mixer, this paper via classical projector). Reading this paper today is a high-leverage cross-paradigm validation of the Y2 design choice.
Main contribution
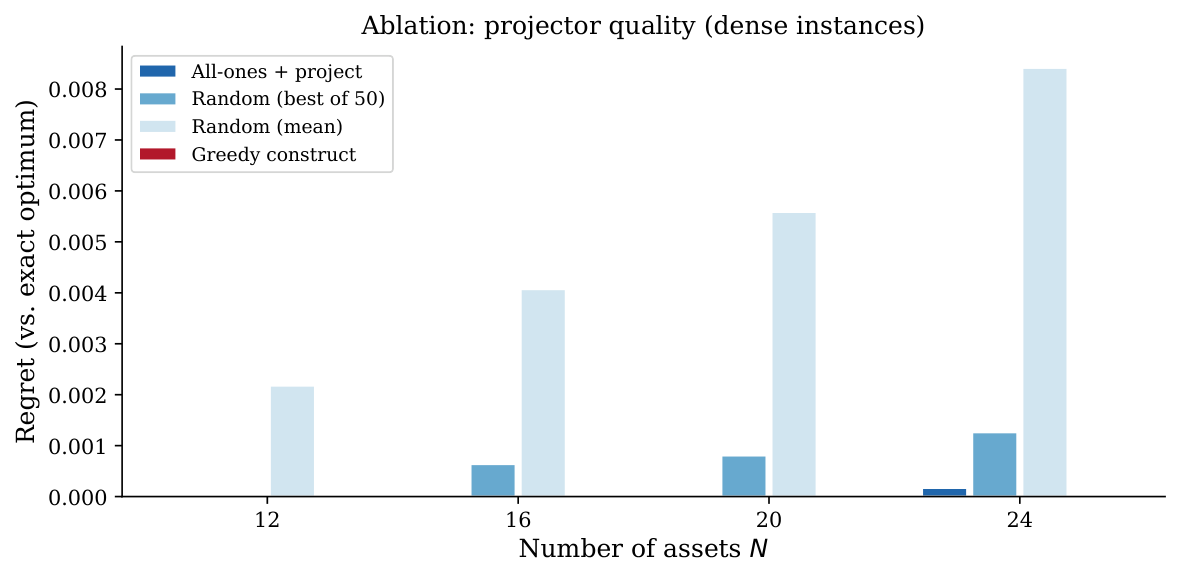
Three findings, in order of importance: (i) the cardinality penalty is the binding bottleneck on current direct-QPU portfolio optimization, not the sparse hardware topology — proved by ablation against random projection; (ii) sparsifying the penalty-encoded QUBO does not work because any off-diagonal entry removed is also constraint mass removed; (iii) the objective-only QUBO with classical post-processing yields essentially-zero chain breaks and competitive regret on live D-Wave Advantage and Advantage2 at the full FF49 universe. The paper is paired with companion 2605.17623, which extends the same diagnosis to the hybrid CQM/BQM layer.
Key theorems / experimental results
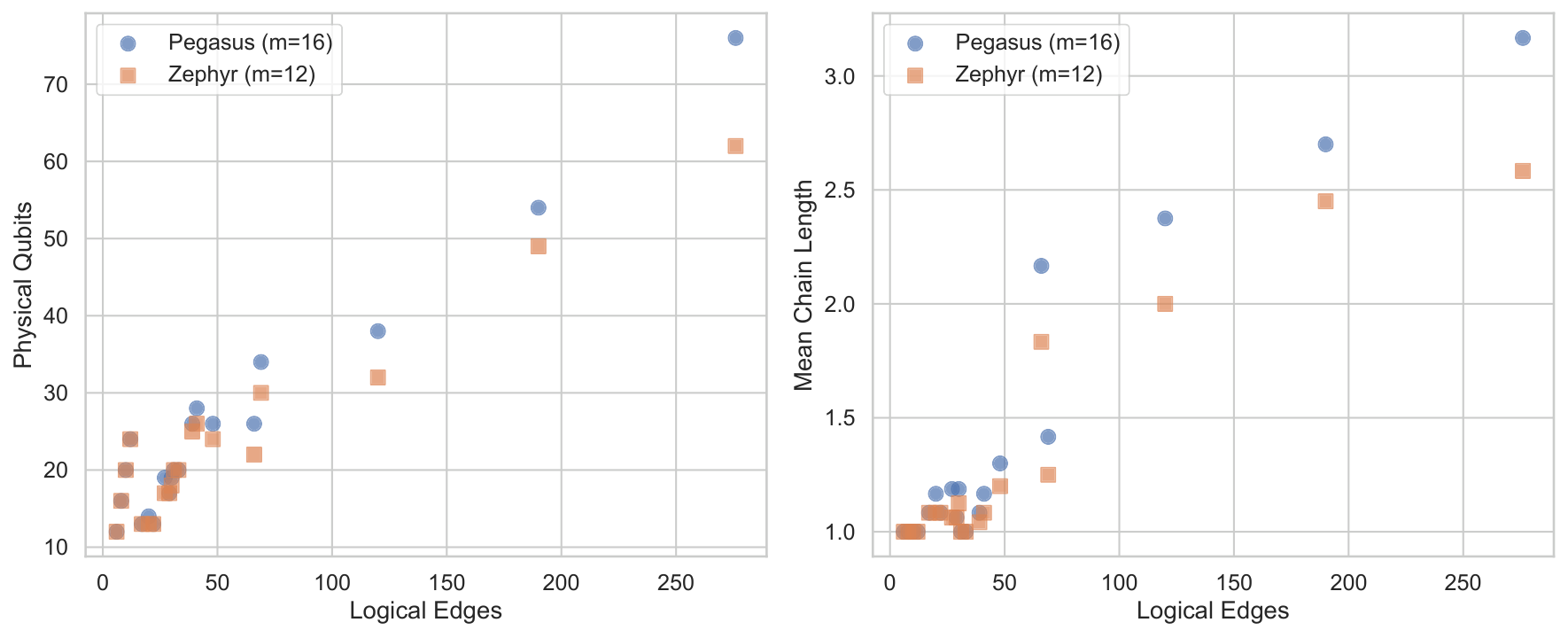
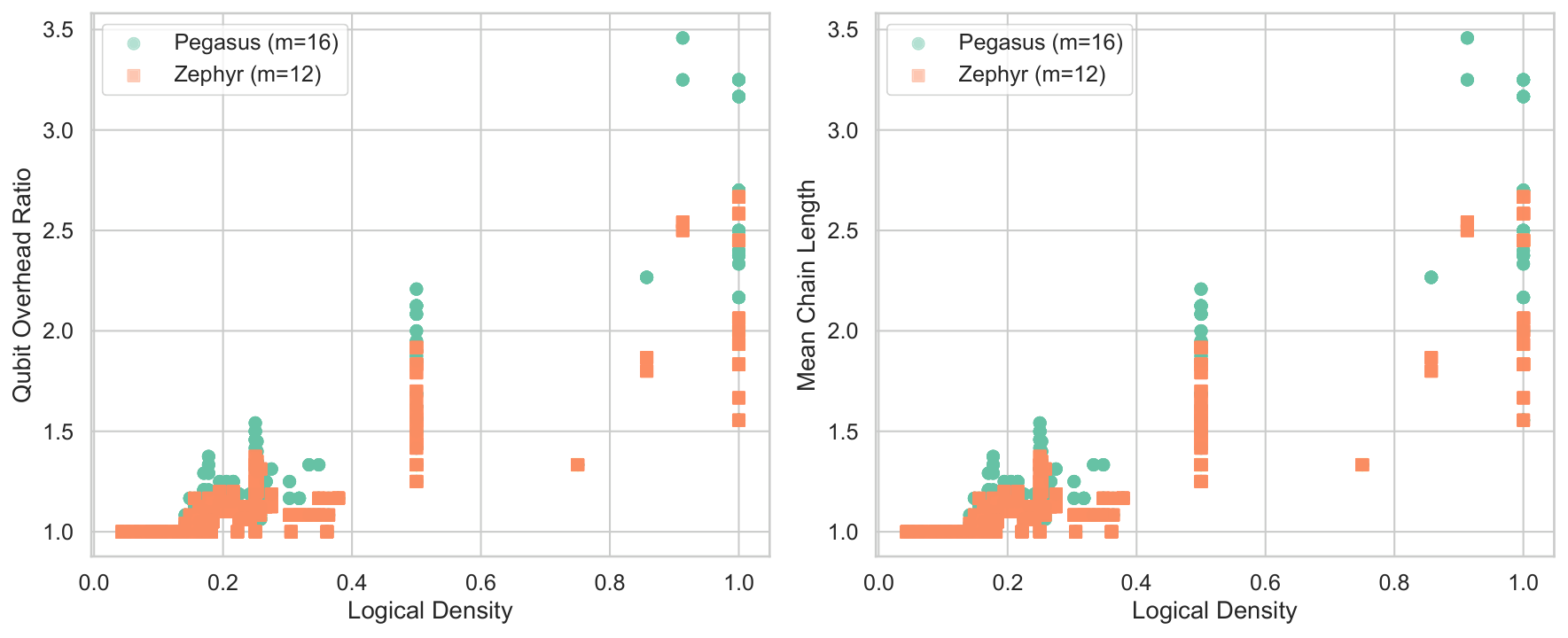
- Diagnosis (§1.1, §3): The standard cardinality-constrained portfolio QUBO Q = −diag(μ) + λΣ + A·1·1ᵀ − 2AK·I contains a rank-one dense penalty term A·1·1ᵀ that makes the logical graph complete regardless of Σ. For a betting slate with block-diagonal payoff covariance, the penalty inflates an instance from 3M edges (one 3-clique per match) to (3M choose 2) edges.
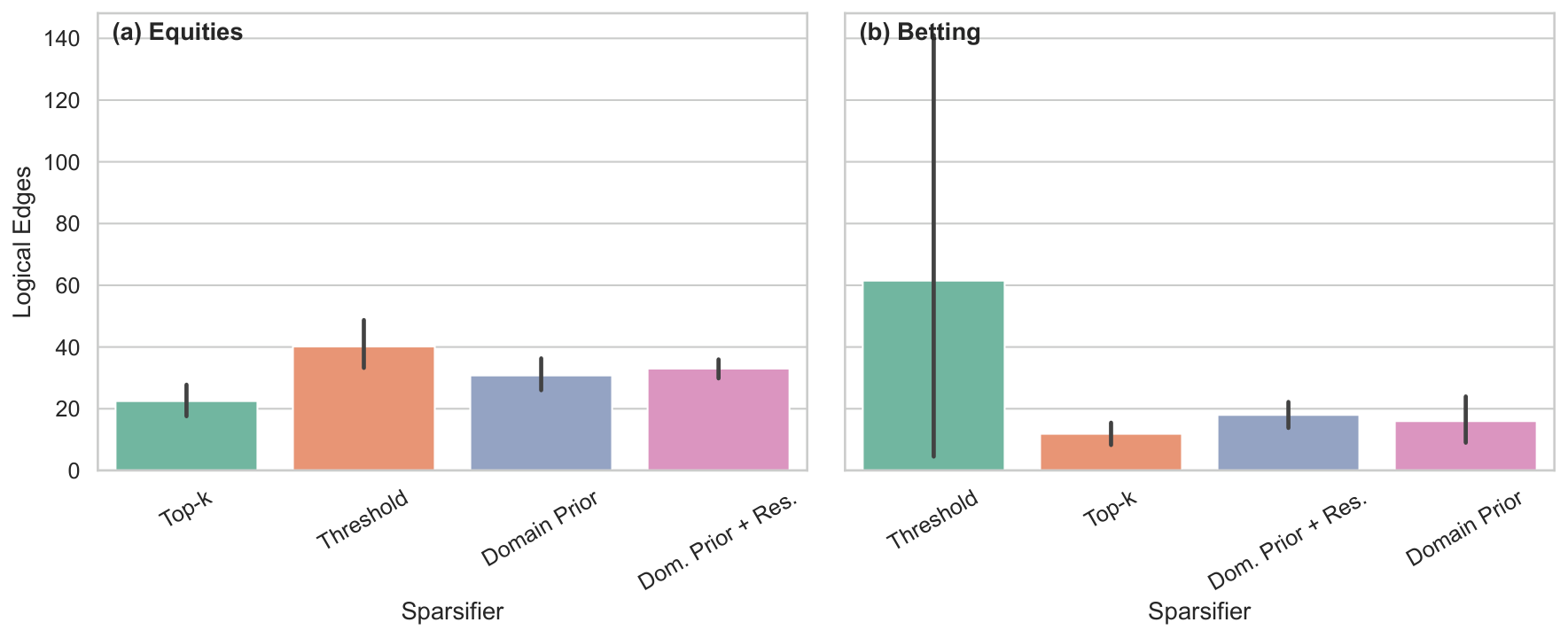
- Proposition A.1 (Spectral bound): A perturbation bound on how much the spectrum of the QUBO matrix shifts under threshold / top-k sparsification, used to justify the topology-aware sparsification protocols.
- Proposition A.2 (Max-entry bound): A pointwise bound on the maximum entry change under sparsification — used to bound the effect on the cardinality constraint.
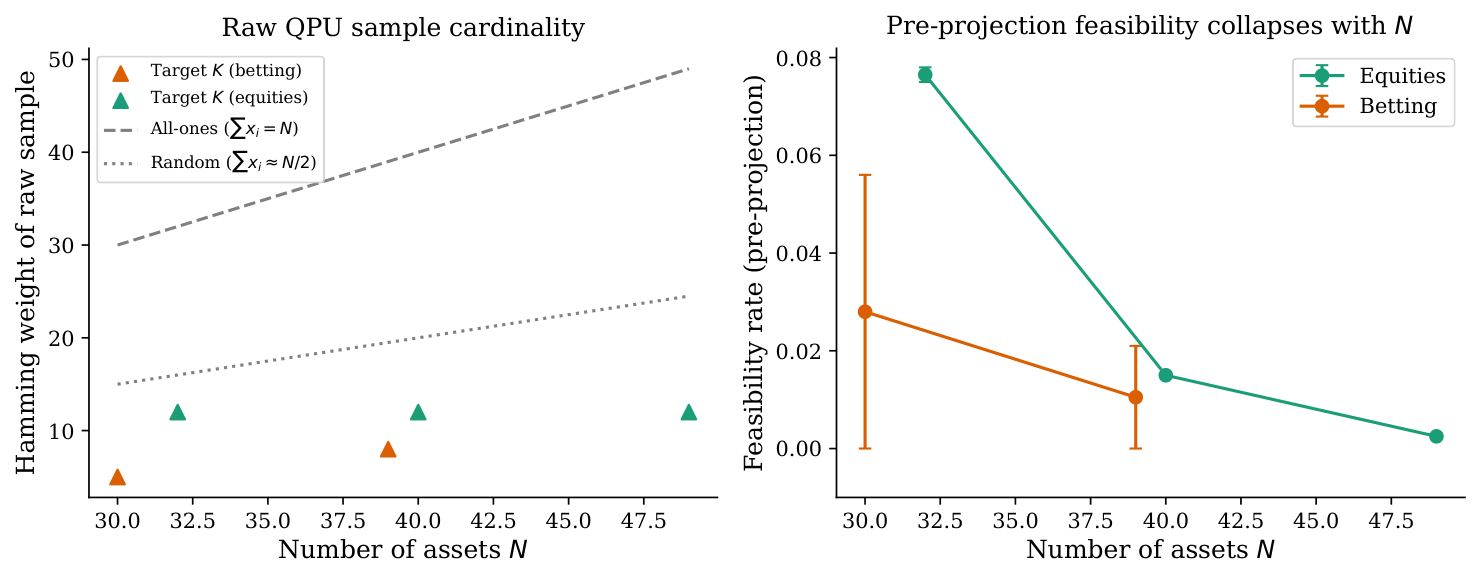
- Empirical observation (constraint dilution): Any sparsifier that removes off-diagonal entries also dilutes the cardinality constraint proportionally. Raw QPU samples remain infeasible (cardinality ≠ K) even when chains no longer break.
- Proposed pipeline (§5.10): Build the objective-only QUBO Q_obj = −diag(μ) + λΣ, sample on hardware, enforce cardinality classically via greedy / backward-elimination projection.
- Empirical Result 1: Penalty-encoded QUBOs at N = 24 yield chain-break fractions ~83% on Pegasus; at N = 49 (full FF49), 88–92% on Pegasus and Zephyr. Zero feasible samples returned.
- Empirical Result 2 (penalty-free pipeline): Chain-break fractions drop from 71–92% (penalized) to at most 0.04% across all tested scales (N up to 49 equities, 48 betting). Post-processed regret on equities is at most 0.03% relative to greedy.
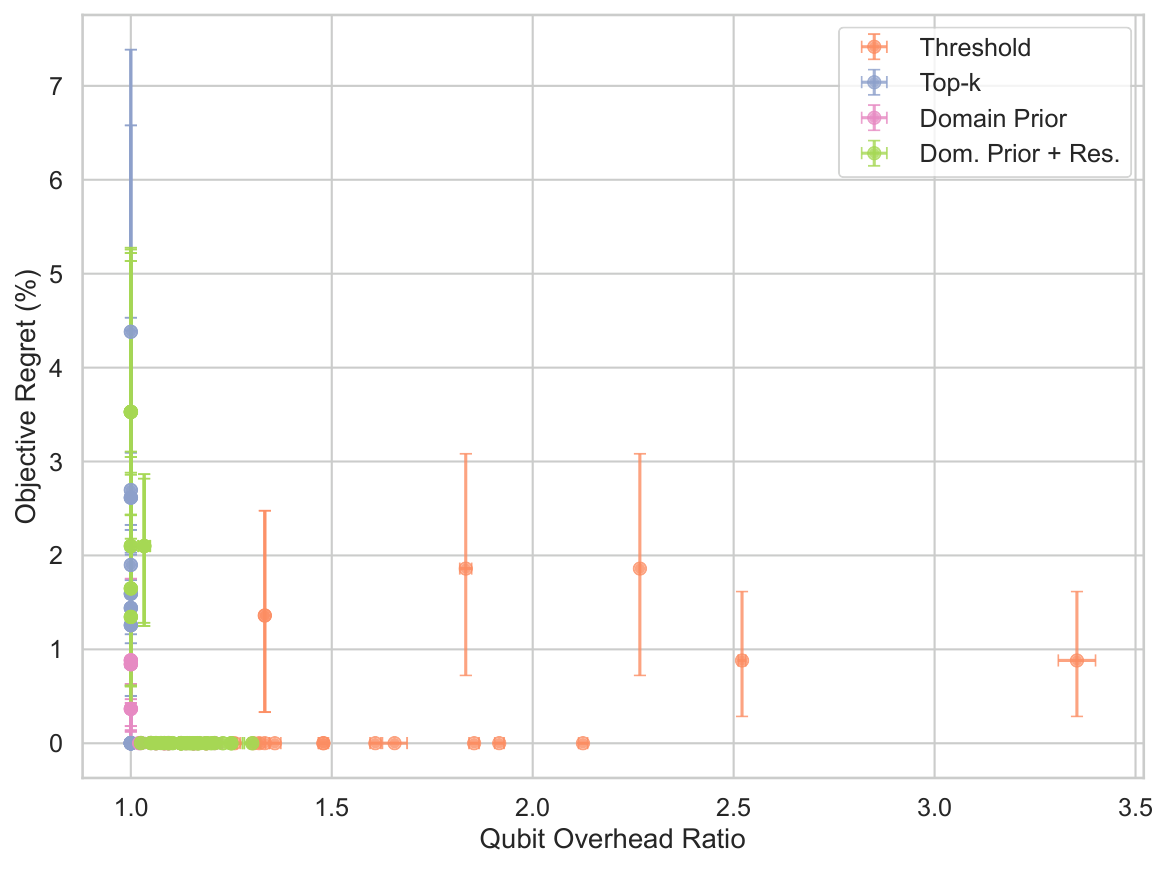
- Empirical Result 3 (ablation): On betting (settlement-graph block-diagonal case) the zero-regret post-processed result is explained entirely by the projector's backward-elimination behavior, not the QPU itself. Random-projection ablation degrades with N while QPU+projector stays competitive — but this isolates the projector as the dominant contributor in the favourable case.
Detailed walkthrough
This is the most direct method-level match in today's batch to Yuan's Y2 (quasi-binary encoding with hard mixer, no penalty terms). The author and Y2 reach independently the same structural conclusion: penalty terms for hard combinatorial constraints are the binding bottleneck on current quantum hardware, and the right response is to remove them entirely. The paper attacks the cardinality-constrained portfolio problem on D-Wave Advantage and Advantage2 — exactly the hardware substrate adjacent to Yuan's QAOA-portfolio work in Y3.
The structural diagnosis (§1.1, §3.1) is sharper than I've seen before. The cardinality penalty A(1ᵀx − K)² expands to A·1·1ᵀ + diagonal + constant. The 1·1ᵀ rank-one matrix adds the value A to every off-diagonal entry of Q. For betting (block-diagonal natural covariance, one 3-clique per match) this turns a 3M-edge instance into a (3M choose 2)-edge instance. For equities (dense natural covariance) it compounds the existing density. Either way, after the penalty is added, the logical interaction graph is K_N and minor-embedding cost on Pegasus / Zephyr scales catastrophically.
Section 4 (Topology-Aware Sparsification) is the failed-fix arc. The author considers four sparsification families: threshold, top-k, domain-prior, and domain-prior with residual edges. Sparsification reliably reduces chain-break fractions to near zero — but Propositions A.1 / A.2 quantify the inevitable side effect: any off-diagonal entry removed is also penalty mass removed, so the cardinality constraint is diluted. The raw samples from a sparsified penalty-encoded QUBO are infeasible (cardinality ≠ K) even when chains hold. This is exactly the failure mode Y2 predicts a priori: any penalty-encoded approach to a hard constraint will fight the encoding's own constraint enforcement against the device's connectivity budget.
The §4.4 ablation is the key honesty move. On betting with settlement-graph priors, the sparsify-and-project pipeline produces zero-regret feasible portfolios. But when the author substitutes random projection for QPU sampling, the random-projection result degrades with N while QPU+projection stays competitive — and on block-diagonal favourable cases, the zero-regret outcome is explained by the projector's backward-elimination behavior alone, not by the QPU. The author writes (§4.4): "Sparsification plus projection is a working pipeline, but the QPU contribution is unclear and the result is dominated by classical post-processing." This is the cleanest published statement of the "where is the quantum actually contributing?" question on this problem class.
Section 5.10 (Penalty-Free Pipeline) is the constructive contribution. The proposal: drop the penalty entirely. Build Q_obj = −diag(μ) + λΣ (objective only). Sample on QPU. Enforce 1ᵀx = K classically via greedy backward elimination. Live hardware results (Tables 5–6, Figures 6–8): chain-break fractions drop from 71–92% (penalty) to ≤ 0.04% (penalty-free) at N up to 49 on Pegasus and Zephyr. For betting at N ∈ {39, 48}, post-processed QPU portfolios are lower-energy than the greedy reference (an energy comparison, not a proof of optimality). For equities, post-processed regret is ≤ 0.03% across all scales including full FF49.
The author is careful not to claim quantum advantage: §1.4 explicitly says "we do not claim quantum advantage; we claim that the penalty encoding, not the hardware, is the binding constraint." This is the right level of claim, and it is structurally identical to Y2's framing of quasi-binary encoding as a constraint-aware design rather than a speed-up.
For Yuan, the cross-paradigm parallel is striking. Y2 attacks the same problem on gate-based QAOA via a hard-constraint mixer; this paper attacks it on annealer hardware via classical post-processing of the projector. Both work because they avoid representing the hard constraint in the Hamiltonian itself. The natural Y2 / Y3 follow-up is a unified comparison: quasi-binary + hard-mixer QAOA vs. objective-only-QUBO + classical projector annealing, on the same DGMVP instances. The paper does not run this comparison, but provides all the apparatus needed.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary encoding + hard mixer, no penalty): Strongest method-level overlap. Y2 enforces hard constraints via a mixer that preserves the feasible subspace, requiring no penalty term. This paper does the same job by removing the penalty from the QUBO entirely and enforcing the constraint classically. Both papers independently identify the cardinality penalty as the structural bottleneck on near-term hardware. A direct comparison of the two approaches on identical DGMVP instances would be a natural follow-up.
- Y3 (DGMVP portfolio QAOA, QST 2026): Same scope (cardinality-constrained mean-variance portfolio) on different hardware paradigm. Y3 concluded that thermal relaxation precludes a QAOA quantum advantage in the realistic regime. This paper concludes that, on annealer hardware, the penalty encoding (not the hardware noise) is the binding constraint. The two diagnoses together are a strong joint statement: the standard penalty-encoded formulation is structurally bad on both gate-model and annealer.
- Y4 (Grover + ADMM, cardinality-constrained BO): Y4's Grover-based approach searches the structured C(n,k) feasible space directly, completely sidestepping the penalty- encoding problem this paper diagnoses. Y4 is effectively immune to the rank-one density issue, which is a useful talking point in any future Y4 motivation section.
- Y1 (iterative warm-started QAOA): Looser overlap — both Y1 and this paper combine a quantum primitive with classical refinement (warm start / projector). The role of the classical refinement is similar in spirit.
- Y5 (Gibbs-state SDP relaxations): Different methodology, but the problem-structure-aware design philosophy is the same: exploit native structure rather than brute-forcing through a penalty encoding.
Recommended action for Yuan
- Cite in next Y2 / Y3 paper: This is a direct empirical validation of the Y2 design choice (avoid penalty terms) from an independent author on adjacent hardware. The chain-break-fraction reduction from 71–92% to 0.04% is a striking number worth referencing.
- Implement for comparison: Set up a head-to-head experiment on identical cardinality-constrained DGMVP instances: (i) Y2-style quasi-binary + hard-mixer QAOA on Heron2, (ii) Lozano-style objective-only QUBO + classical projector on Advantage2. This would be the cleanest cross-paradigm "penalty-free" comparison published to date.
- Email author (Luis Lozano): The author's two-paper companion structure (2605.17623 hybrid audit + 2605.17628 direct-QPU penalty-free pipeline) is unusually disciplined for D-Wave benchmarking. A short follow-up exchange could share Y2's hard-mixer construction — the author would likely be interested.
- Read deeper: The Section 4 sparsification analysis and Proposition A.1 / A.2 perturbation bounds are reusable in any future encoding-comparison work. Worth saving for reference.