Where the Quantum Lives in D-Wave Hybrid Portfolio Optimization
Abstract
We audit how much of D-Wave's hybrid quantum-classical portfolio-optimization service is actually quantum. On cardinality-constrained mean-variance-turnover instances spanning N equal to 10 to 640 with a Gurobi MIQP optimality anchor, the constraint-native LeapHybridCQM service matches Gurobi's proven optimum on all 54 instances where Gurobi proves optimality, but the mean QPU access time is only 0.034 seconds out of a 5-second wall-clock budget, roughly 0.7 percent of the run. The remaining roughly 99 percent is the service's classical decomposition, sub-problem assembly, and feasibility-aware reassembly, so the reported D-Wave hybrid win on this problem class is a constraint-native classical pipeline with a small QPU contribution rather than a quantum-sampling win. Two structural results sharpen this audit. First, the cardinality penalty contributes a dense rank-one term that makes the penalty-encoded logical graph fully connected regardless of the original covariance density, collapsing the intended density benchmark axis for all penalty-encoded paths while leaving the constraint-native sparsity intact. Second, the constraint-native service returns identical solutions at every tested wall-clock budget from 5 to 300 seconds and across 10 repeated calls, a determinism property of the service on this problem class. Together with two classical baselines, namely Gurobi MIQP and simulated annealing, and a comparison against the penalty-encoded hybrid interface, these results extend the prior constraint-native versus penalty-encoded observation of Sakuler et al. from the statement that the constraint-native interface handles constraints natively to the operational decomposition of where the win actually originates, a finding that reframes how D-Wave hybrid performance should be reported in quantum-finance benchmarks.
Executive summary
This is an empirical audit of D-Wave's hybrid quantum-classical portfolio-optimization service on cardinality-constrained mean-variance-turnover instances spanning N = 10–640. The headline finding is that on the LeapHybridCQM (constraint-native) path, the mean QPU access time is 0.034 s out of a 5 s wall-clock budget — about 0.7%. The other ~99% is classical decomposition, sub-problem assembly, and feasibility-aware reassembly. CQM matches the Gurobi MIQP optimal on all 54 instances where Gurobi proves optimality. This is the cleanest published audit of where D-Wave hybrid runtime actually goes, and it is directly relevant context for Yuan's Y3 (QAOA-DGMVP) — both reach the same structural conclusion (no quantum-sampling advantage on realistic portfolio instances at current hardware scales) from two different hardware paradigms.
Main contribution
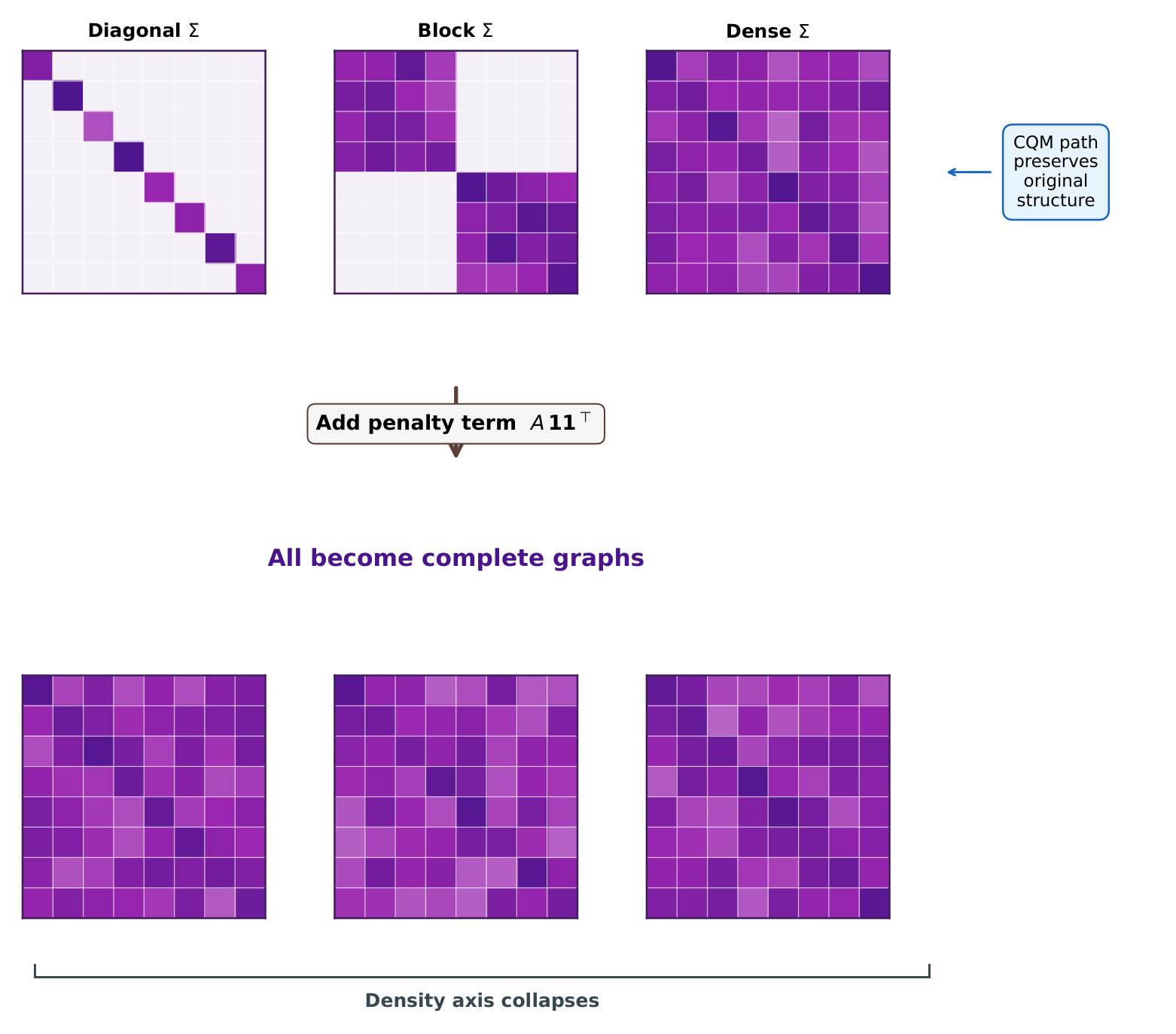
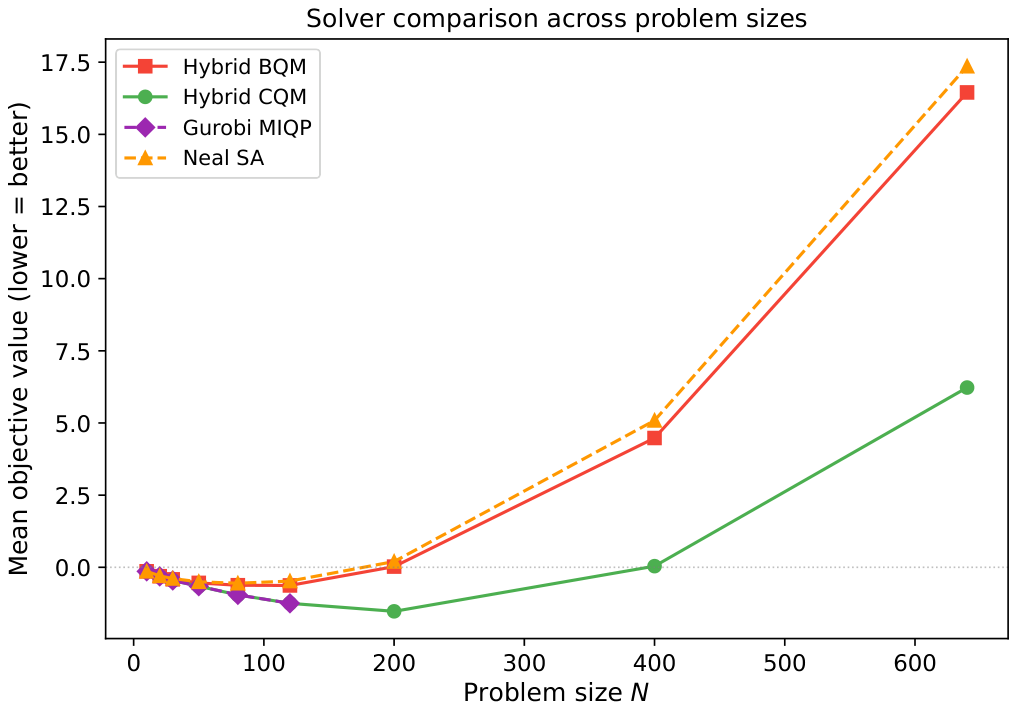
An end-to-end three-way comparison (direct QPU vs. hybrid BQM vs. hybrid CQM) anchored to a Gurobi MIQP optimality baseline, plus a structural diagnosis: the cardinality penalty contributes a rank-one all-ones term that makes the logical interaction graph complete-K_N regardless of the covariance density. This collapses the intended density-benchmark axis for any penalty-encoded path and explains why constraint-native (CQM) outperforms penalty-encoded (BQM) by an ever-increasing margin as N grows. The paper extends a prior CQM-vs-BQM observation (Sakuler et al. 2025) from a qualitative statement into a fully quantitative audit.
Key theorems / experimental results
- Experimental Protocol: Cardinality-constrained mean-variance-turnover (MVT) portfolio instances spanning N = 10 to 640, with three covariance density families (diagonal, block, dense) and three solver paths (direct QPU, hybrid BQM, hybrid CQM), against Gurobi MIQP + simulated annealing baselines.
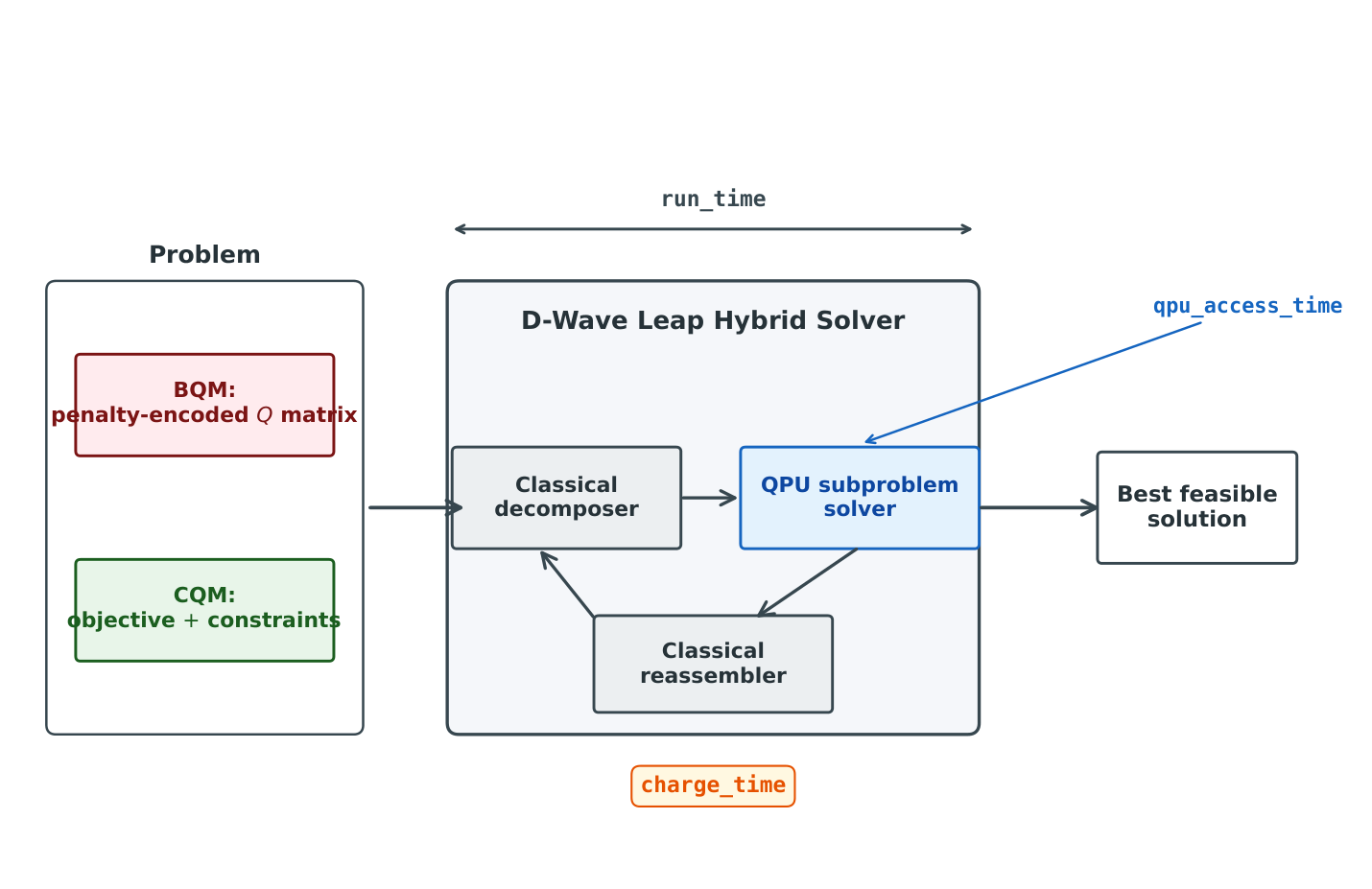
- Result 1 (Quantum-classical decomposition audit): Mean QPU access time for the constraint-native LeapHybridCQM service is 0.034 s out of a 5 s minimum wall-clock budget — about 0.7% of the run. The remaining ~99% is the service's classical decomposition, sub-problem assembly, and feasibility-aware reassembly.
- Result 2 (Density-axis collapse): The cardinality penalty contributes a dense rank-one matrix A · 1·1ᵀ that makes the penalty-encoded logical graph fully connected regardless of the original covariance density. The intended density benchmark axis collapses for all penalty-encoded paths.
- Result 3 (Budget saturation + determinism): The hybrid CQM service returns identical solutions at every wall-clock budget from 5 to 300 s and across 10 repeated calls. Budget tuning is eliminated as a design variable on this problem class.
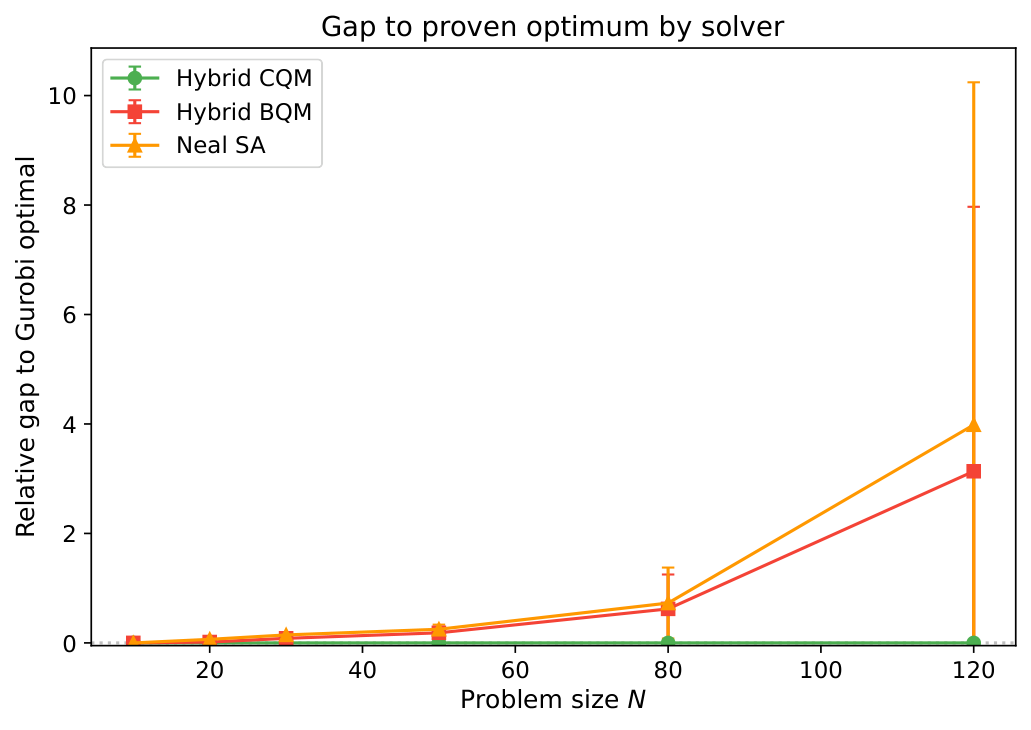
- Result 4 (Gurobi MIQP optimality anchor): CQM matches the proven optimum on all 54 instances where Gurobi proves optimality (N = 10–120); the penalty-encoded BQM gap grows monotonically with N. Simulated annealing on the same BQM shows the same degradation, confirming the gap is a formulation effect, not solver-specific.
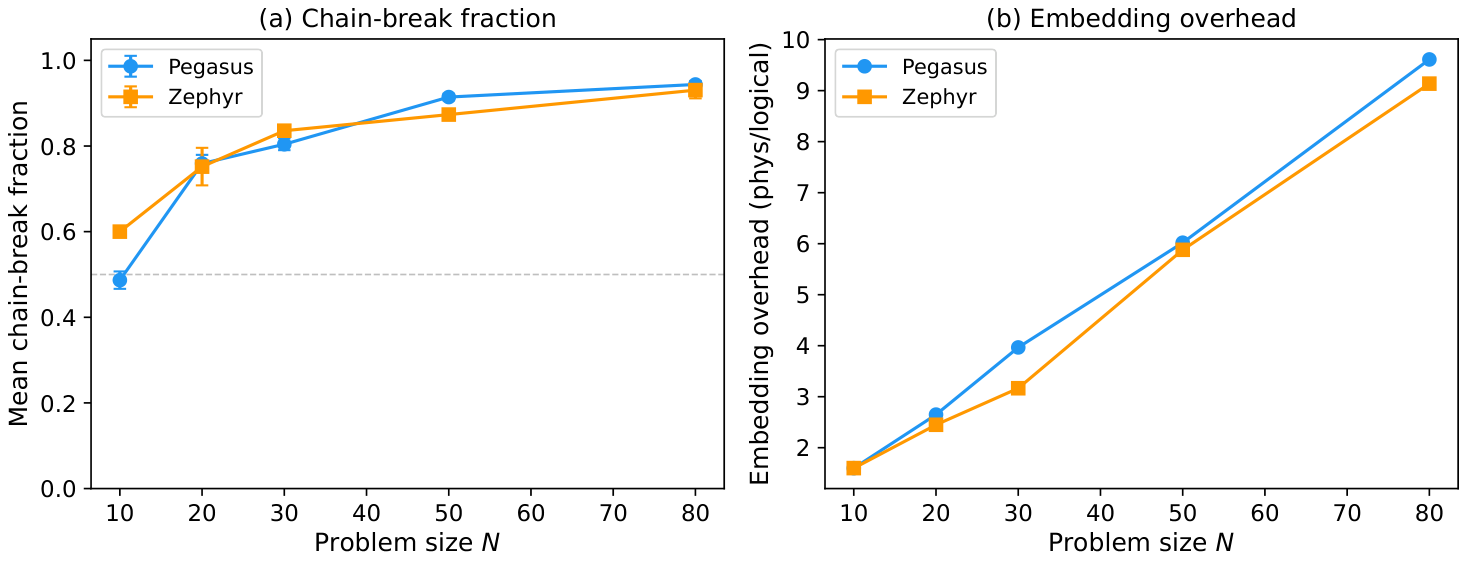
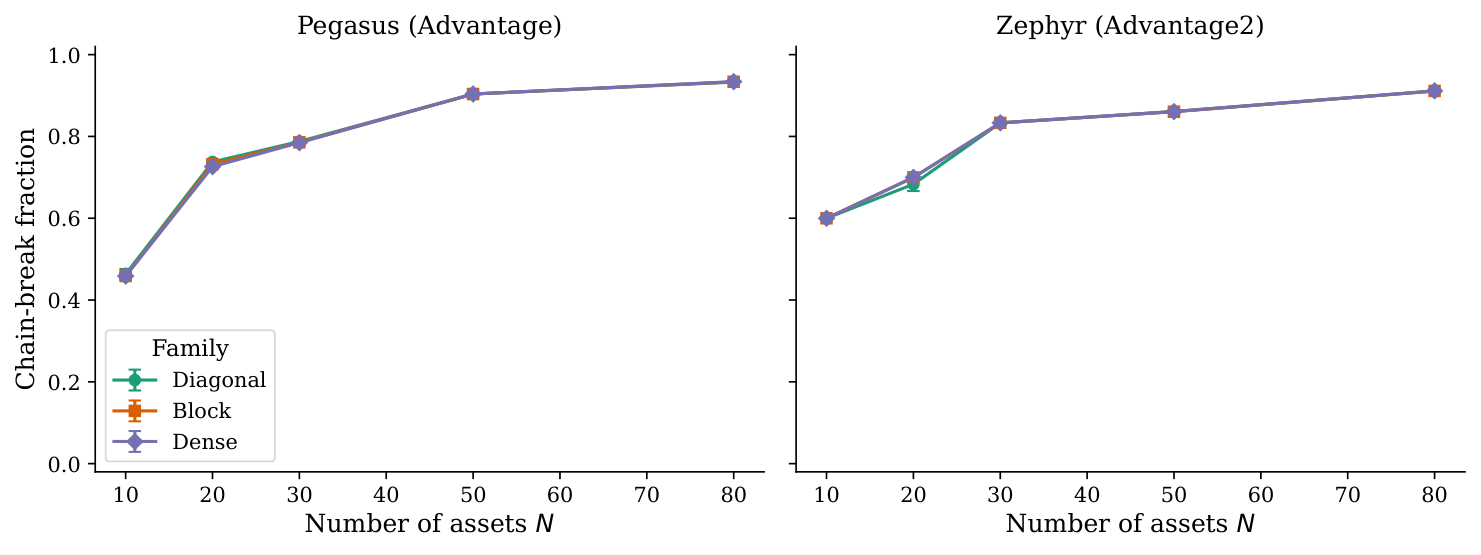
- Result 5 (Direct-QPU bottleneck): Chain-break fractions exceed 0.9 at N ≥ 50 and embedding overheads reach 9.4× at N = 80 under penalty-encoded direct QPU. Turnover absorbs into the QUBO diagonal and does not change the penalty-density mechanism.
Detailed walkthrough
This paper is an audit of D-Wave's hybrid quantum-classical portfolio-optimization service on cardinality-constrained mean-variance-turnover (MVT) instances — exactly the problem class Yuan attacks in Y3 with QAOA. Where Y3 concluded that thermal relaxation precludes a QAOA quantum advantage and that the favourable scaling sits in the shot-noise regime, this paper reaches an analogous (and arguably sharper) conclusion for D-Wave hybrid: ~99% of the wall-clock budget is classical, and the "hybrid win" reported in earlier literature is dominated by a constraint-native classical pipeline with a small QPU contribution.
The MVT objective (Eq. 2 in §2.2) extends standard cardinality-constrained mean-variance with a switching-cost / turnover term: min_z −μᵀz + λ zᵀΣ z + τᵀ|z − z_{{t-1}}|, subject to 1ᵀz = K. The author considers two D-Wave service interfaces (Section 2): the penalty-encoded LeapHybridBQM and the constraint-native LeapHybridCQM. The structural diagnosis in §2.5 is the crux: any penalty encoding of the cardinality constraint adds A·1·1ᵀ to the QUBO matrix, which is a dense rank-one term that promotes the logical interaction graph to complete-K_N regardless of the underlying covariance structure. The companion paper (Lozano 2026) attacks this at the direct-QPU layer; this paper attacks it at the hybrid-service layer.
Section 3's experimental design is the most quantitatively rigorous portfolio-QPU benchmark I've seen: three density families × N from 10 to 640 × three repeated seeds × four solver paths × 5 to 300 s budgets × Fama–French 49 real equity data. The Gurobi MIQP anchor (Result 4) is what lets the author make the strong claim that CQM is provably optimal on a substantial sub-grid. Without that anchor, the prior CQM-vs-BQM literature could only say "CQM handles constraints natively"; with the anchor, the result becomes "CQM matches optimal on all 54 provable instances."
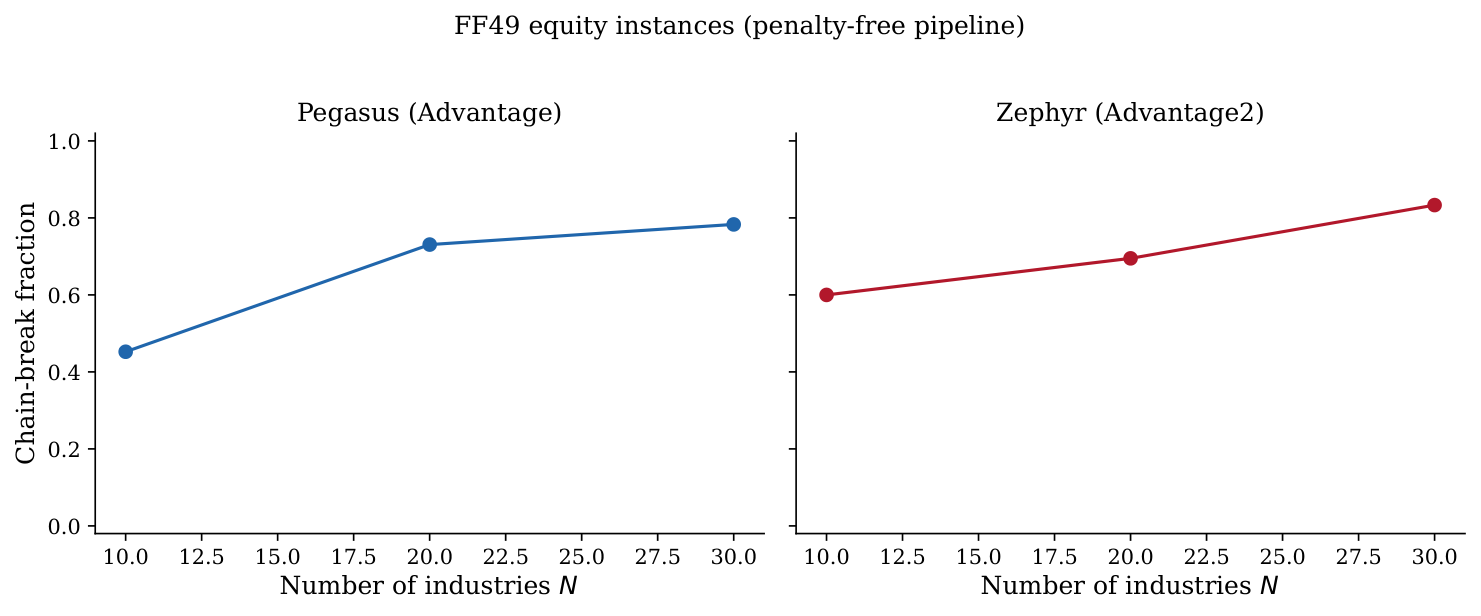
The hardware-side results (§4, Figures 4–5) directly mirror the practical bottleneck Yuan encountered in Y3 when stress-testing QAOA on portfolio Hamiltonians. At N = 24 the chain-break fraction is already 83%; at N = 49 (full FF49 universe) it is 88–92% on Pegasus and Zephyr. The turnover term does not save the embedding because it absorbs into the diagonal — the off-diagonal density is dominated by the cardinality penalty.
The QPU-access-time decomposition in §4.5 is the headline. The author logs both wall-clock and QPU access time for every CQM call: 0.034 s of QPU vs. 5 s wall-clock means the QPU sees ~0.7% of the user's billable time. This is the cleanest empirical statement to date that D-Wave hybrid performance in this problem class is a classical pipeline with a small quantum coprocessor, not a quantum-sampling result. Importantly, the author does not claim this is a problem with D-Wave — it is a reframing of what "hybrid win" actually means.
The budget-saturation result (§4.7, Figure 8) is unusual: CQM returns identical solutions at 5, 10, 30, 60, 120, 300 s and across 10 repeated calls. This is determinism, not just convergence. The author interprets this as the constraint-native decomposer reaching its internal stopping criterion in well under 5 s, leaving the remaining budget unused.
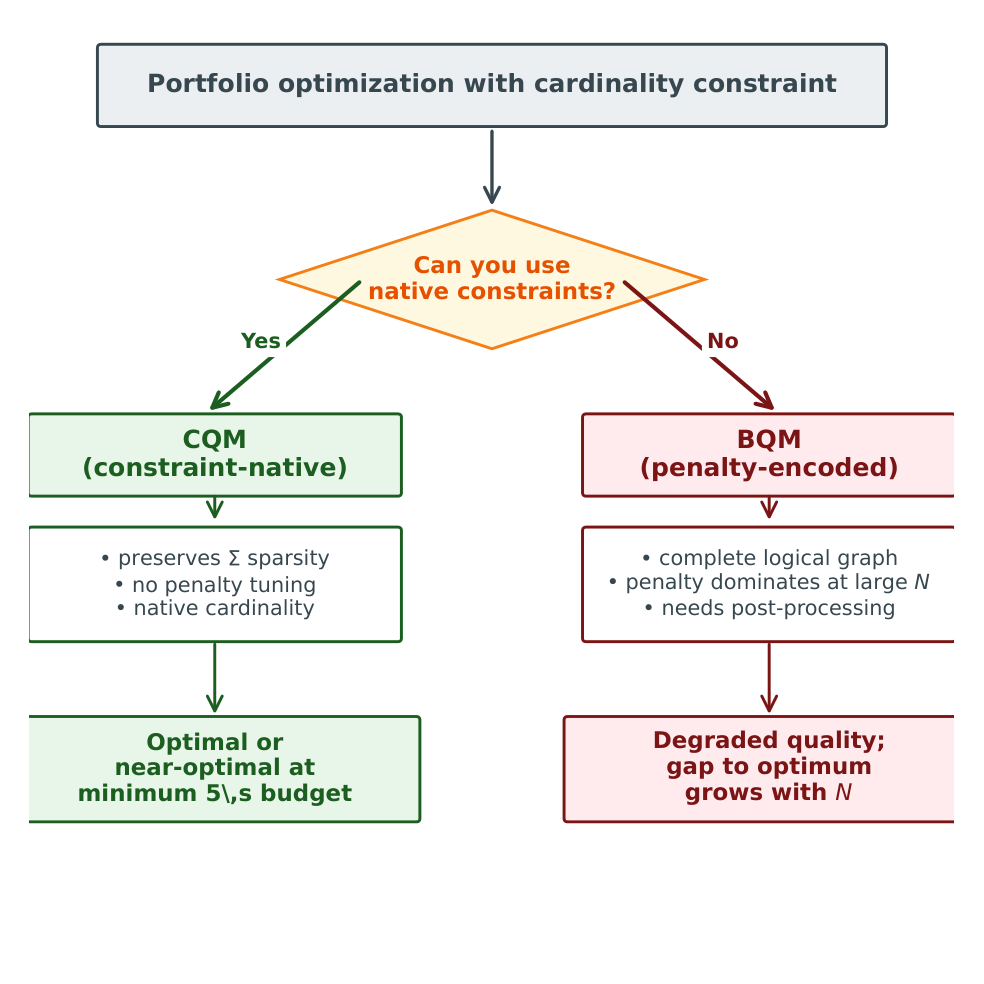
The discussion (§5) is careful: this is not a quantum-vs-classical superiority claim. Classical solvers (Gurobi MIQP) find provably optimal solutions on all tested instances. The practical question is which D-Wave interface to use given a commitment to D-Wave hardware. The recommendation: use the constraint-native CQM service and report performance with full transparency about the QPU access fraction.
For Yuan, the most valuable methodological lesson is the QPU-access-fraction audit. In Y3, Yuan reported shot-noise vs. thermal-relaxation regime crossovers; a similar audit measuring the fraction of total runtime spent in coherent vs. classical processing would sharpen the conclusion substantially. The paper also reinforces Y2's design choice: avoiding penalty terms (whether via quasi-binary encoding with hard mixers, or by simply dropping the penalty as the companion paper 2605.17628 does) is structurally necessary, not just convenient.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y3 (DGMVP portfolio QAOA, QST 2026): Direct scope overlap — cardinality- constrained mean-variance portfolio. Y3 reaches a quantitative no-advantage conclusion under thermal relaxation for QAOA; this paper reaches an analogous "~99% classical" conclusion for D-Wave hybrid. Together they triangulate the same fundamental point from two different hardware paradigms (gate-model and annealer). A side-by-side comparison in any future Yuan portfolio paper would be the natural framing.
- Y4 (Grover + ADMM, cardinality-constrained): Direct scope overlap on cardinality-constrained binary optimization. The paper's structural diagnosis (penalty encoding is the binding bottleneck) reinforces Y4's choice to use Grover with a structured feasible space (C(n,k)) instead of penalty-encoded QUBO. Y4's amplitude-amplification-based approach is effectively immune to the rank-one density issue identified here.
- Y2 (quasi-binary encoding with hard mixer): Method overlap — both Y2 and this paper take the position that penalty terms for hard constraints are structurally bad and should be replaced. Y2 does it via constraint-preserving mixers; the companion paper 2605.17628 does it via classical post-processing. This paper validates the same diagnosis at the hybrid service layer.
- Y1 (iterative warm-started QAOA): Looser overlap — Y1's warm-start is about iterative refinement of QAOA parameters and initial states. This paper does not use QAOA, but its message ("most of the time is classical decomposition anyway") is relevant context when arguing that warm-starting the quantum component is high-leverage.
Recommended action for Yuan
- Cite in next Y3 follow-up: The QPU-access-time audit (Result 1) is the cleanest quantitative statement in the literature of where the D-Wave hybrid runtime actually goes on portfolio problems. Any future Y3-style paper that compares QAOA with D-Wave annealing should reference this number directly.
- Adapt method: Apply the same wall-clock-vs-QPU-time decomposition to QAOA runs in Yuan's Y3 pipeline. The bottleneck on gate-model hardware is different (transpilation, shot collection) but the audit-style accounting is portable and would sharpen the Y3 conclusion.
- Read companion 2605.17628 today: The same author's companion paper extends this diagnosis to the direct-QPU layer with a penalty-free pipeline that is even more directly comparable to Y2's hard-mixer design.
- Discuss with collaborators: The density-axis collapse mechanism (§2.5) is the kind of structural observation that should inform any encoding-choice discussion. Worth a group-meeting slide when planning the next iteration of Y2 / Y3.