Benchmarking and Resource Analysis for Augmented-Lagrangian Quantum Hamiltonian Descent
Abstract
Quantum Hamiltonian Descent (QHD) is a continuous optimization algorithm based on simulating a time-dependent quantum Hamiltonian whose potential energy encodes the objective function and whose kinetic energy promotes exploration through quantum interference and tunneling. While QHD is formulated for unconstrained optimization, many real-world optimization problems are constrained and highly nonconvex. In this paper, we benchmark AL-QHD, a hybrid framework that embeds QHD within the Augmented Lagrangian Method (ALM), thereby solving a sequence of unconstrained subproblems while using ALM to enforce constraints. We evaluate AL-QHD on standard nonconvex test functions and use iterative refinement to improve solution accuracy at fixed per-run qubit cost. We also perform a gate-based resource analysis on ACOPF-derived power-system subproblems constructed from power-network data to estimate the quantum-computer scale required for practical applications. Resource estimates on Texas7k-derived ACOPF instances show steep hard-gate scaling, reaching ~4.46×107 entangling gates in a NISQ-oriented model and ~9.42×108 T gates in a fault-tolerant model at ~5.3×102 active variables. These results suggest that AL-QHD is a useful framework for studying constrained nonconvex optimization with QHD, but that practical ACOPF-scale applications would likely require large-scale fault-tolerant quantum hardware.
Executive summary
This paper proposes AL-QHD, a quantum-classical hybrid that embeds Quantum Hamiltonian Descent (a continuous-variable quantum optimization algorithm) inside an outer Augmented Lagrangian loop to handle constrained nonconvex problems. It is structurally the QHD analogue of what Y4 does with Grover/ADMM and what Y2/Y3 do with QAOA: a classical outer loop couples constraints to a quantum inner solver, with iterative refinement playing the same accuracy-vs-qubit role as Yuan's iterative QAOA refinement. The paper's headline negative result — that ACOPF-scale ($\sim$530 variables) needs roughly $10^9$ T gates and is therefore a fault-tolerant target, not a NISQ one — mirrors the conclusion of Y3 that thermal relaxation precludes quantum advantage at NISQ scale. For Yuan, this is a directly comparable end-to-end resource study from a non-overlapping research group; the iterative-refinement adaptive-zoom procedure is also a natural object to compare with the quasi-binary refinement of Y2.
Main contribution
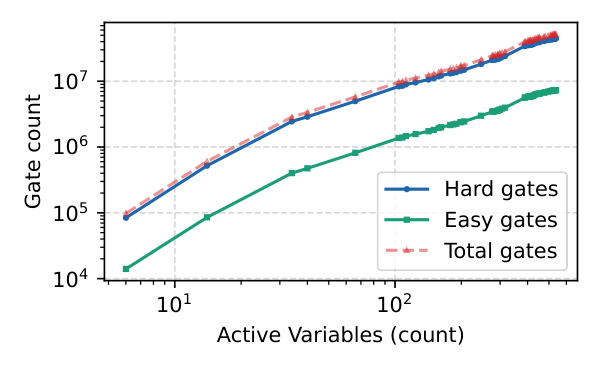
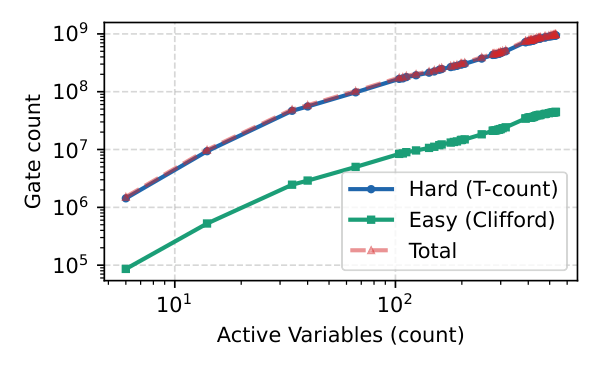
The paper extends QHD — a Schrödinger-equation-based continuous optimizer with kinetic exploration and potential-encoded objective — from the unconstrained setting to general nonlinearly constrained nonconvex programs by reusing the textbook ALM mechanism: the augmented Lagrangian $\mathcal{L}_\rho(x,\lambda) = f(x) + \sum_i \lambda_i h_i(x) + (\rho/2)\sum_i h_i(x)^2$ becomes the QHD potential at each outer iteration, and Lagrange multipliers are updated classically using the inner QHD-returned candidate. On top of this, the authors add an adaptive-zoom iterative refinement: after each QHD run, the wavefunction's peak marginal region defines a tighter box for the next run at the same qubit count, decoupling final accuracy from grid resolution. They build a one-hot encoding pipeline (r qubits per variable at resolution r), compile both kinetic and potential evolutions (parity decomposition for k-local Z-strings → $2(k-1)$ CNOTs $+ R_z$), and produce gate counts under both NISQ and surface-code-compatible FT models, applied to ACOPF subgraphs extracted from the Texas7k synthetic grid (6–538 active variables).
Key algorithms / lemmas / experimental protocol
- QHD Hamiltonian (Eq. 3): $\widehat{H}(t) = a(t)\widehat{K} + b(t)\widehat{V}$ with $\widehat{K} = -\nabla^2/2$ and $\widehat{V} = f(x)$, using QHD-C damping schedule $a(t) = (2/(s+t))^3$, $b(t) = 2t^3$.
- AL-QHD outer loop (Sec. III.C): initialize $\lambda_0,\rho_0$; at iteration $k$, run QHD on $\mathcal{L}_{\rho_k}(x,\lambda_k)$, extract minimizer $x_{k+1}$, update $\lambda_{k+1,i} = \lambda_{k,i} + \rho_k h_i(x_{k+1})$, optionally inflate $\rho_k$.
- Iterative-refinement procedure (Sec. IV): coarse QHD → identify peak of $|\Psi|^2$ → build a smaller box from marginal probability intervals satisfying $\sum_k p_{z,j}(k) \ge \eta = 0.99$ → rerun QHD at the same grid size on the shrunken domain. Effective resolution improves geometrically while qubit cost stays constant.
- One-hot encoding cost model (Sec. III.B): grid value $g_{j,k}$ → occupation operator $n_{j,k} = (I - Z_{j,k})/2$; potential evolution decomposed into Pauli-$Z$ strings; each $k$-local string costs $2(k-1)$ CNOTs + 1 $R_z$.
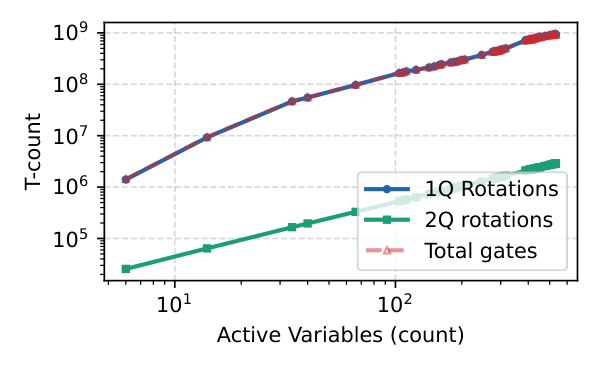
- FT cost estimator (Eq. 9): $N_{T,\text{total}} = N_{T,K} + r(\epsilon)(N_{r,K} + N_{r,V})$ where $r(\epsilon)$ is the average $T$-count to gridsynth a single $R_z$ to tolerance $\epsilon$, sampled over 5000 random angles.
- Empirical scaling fits (Sec. V.D): FT hard-T count $\approx 3.48\times 10^5\, n^{1.27}$, NISQ entangling-gate count $\approx 2.17\times 10^4\, n^{1.23}$ over Texas7k ACOPF instances ($R^2 \approx 0.98$).
Detailed walkthrough
Setup. The authors target two structurally different benchmarks. The unconstrained Ackley function (Sec. V.A) is a 2D nonconvex landscape with one deep narrow well and a flat outer plain — effectively unimodal for any local solver, so the relevant question is purely precision. The constrained scaled Rastrigin function with $\alpha = 3$ (Sec. V.B) has $\sim 900$ local minima in $[-5,5]^2$, with two nonlinear curved lower-bound constraints chosen specifically to be non-rectangular (so they cannot be folded into domain truncation). The constrained optimum sits at $\mathbf{x}^* \approx (0.6633, 0.6633)$ with $f^* \approx 7.96$. Both QHD runs use a QHD-C schedule, classical split-step Fourier (Strang-split) simulation with 50,000 Trotter steps, and either a 32×32 or 64×64 grid.
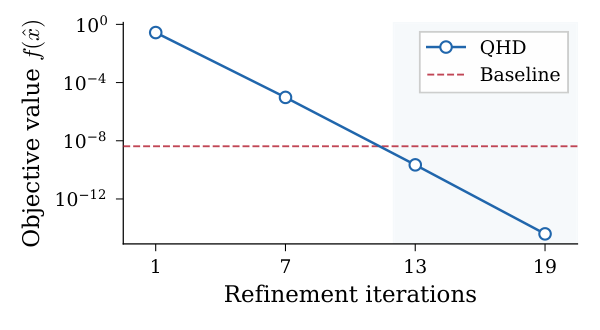
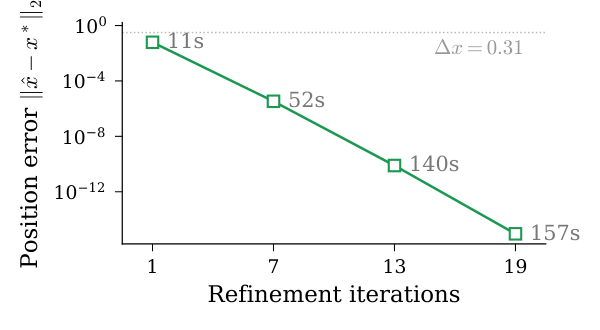
Ackley result (Table I). Without zoom ($Z=1$), QHD returns $f \approx 0.27$ — one grid spacing of error, as expected. With $Z=7$ zooms the objective drops to $\sim 10^{-5}$; with $Z=13$ to $\sim 2 \times 10^{-10}$ (beating the 100-start L-BFGS-B baseline of $4.2 \times 10^{-9}$); with $Z=19$ to $\sim 4 \times 10^{-15}$ — essentially machine epsilon for double precision — while still using only $2 \times 32 = 64$ qubits in the one-hot encoding. The wall-clock comparison is intentionally not framed as a quantum-advantage claim: classical L-BFGS-B finishes in $<1$s and also finds the basin. The Ackley result is purely a refinement-accuracy stress test.
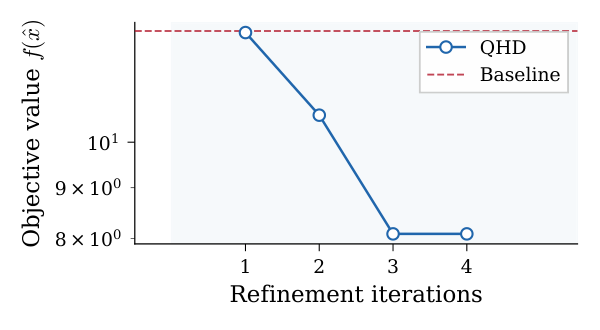
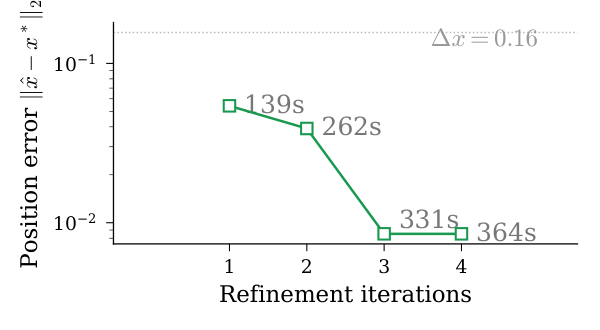
Constrained Rastrigin result (Table II). All zoom levels achieve zero constraint violation in 6–7 ALM iterations with moderate $\rho_{\text{final}} \in \{32, 64\}$. At $Z=1$, QHD already places both coordinates in the correct $k=2$ basin near $(0.625, 0.625)$ with $f = 12.89$. At $Z=3$ and $Z=4$, $f$ drops to 8.089, just $1.63\%$ above the known constrained optimum. The 100-start SLSQP baseline, by contrast, gets stuck at $(0.995, 0.663)$ with $f = 12.93$ — one coordinate in the $k=3$ basin and the other in the $k=2$ basin, an objective excess of $62.5\%$. The authors add a critical honesty note (Table III): a 200-start SLSQP does recover the optimum, so the comparison is budget-dependent, not an impossibility result. This restraint is rare and worth flagging when summarizing the paper.
ACOPF resource study (Sec. V.D). The authors extract connected subgraphs from the Texas7k synthetic transmission grid ranging from 2 to 198 buses, build the symbolic ACOPF objective with quadratic generation cost subject to AC power balance, voltage and generator bounds, and reduce it to a one-hot Ising Hamiltonian with 6–538 active variables. The dominant cost is from the potential evolution, not the kinetic template: at $n=6$, the parity-decomposed potential block accounts for $99.7\%$ of NISQ hard gates and $98.2\%$ of FT $T$ gates; at $n \approx 530$ those fractions rise to $\sim 99.95\%$ and $99.7\%$ respectively. The kinetic template is essentially linear in $n$ ($44n$ hard 2-qubit gates NISQ, $42n$ rotations + $2n$ exact $T$ gates FT), so the empirical $n^{1.27}$ FT scaling is essentially the potential-side polynomial scaling.
Conclusion (Sec. VII). The headline negative number is that the largest extracted Texas7k subgraph (538 variables) needs $\sim 9.42 \times 10^8$ $T$ gates and $\sim 4.46 \times 10^7$ entangling gates — orders of magnitude beyond what current NISQ devices can run reliably and likely past the magic-state-distillation throughput of early FT machines. The authors correctly frame this as: AL-QHD is a viable framework, iterative refinement is a useful qubit-saving primitive, but ACOPF at scale is a fault-tolerant target rather than a NISQ application. They explicitly do not claim quantum advantage. Limitations they own: the experiments are 2D, classical baselines are limited (no global solvers like differential evolution or branch-and-bound), and the Trotterized realization may not be the most resource-efficient.
Figures
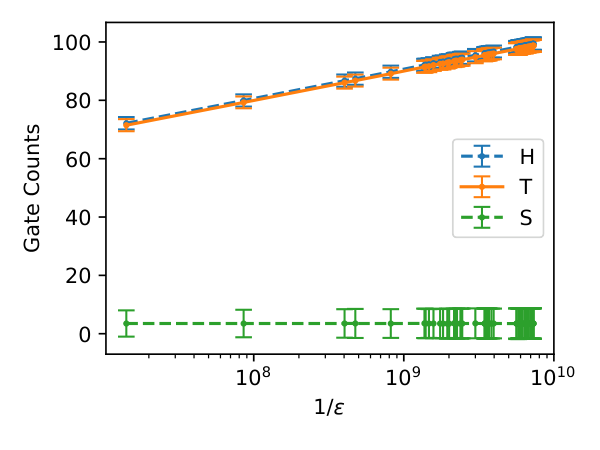
gridsynth; per-rotation tolerance $\epsilon$ is determined from the total number of $R_z$ rotations and target QHD-run accuracy. Each data point: 5000 sampled angles in $(-\pi,\pi]$.Citations to Yuan's papers
Overlap with Y1–Y6
Y4 (Grover + ADMM cardinality-constrained BO) — strongest method link. Y4 and AL-QHD share the same architectural pattern: a classical outer loop (ADMM in Y4, ALM in this paper) that handles constraints via Lagrange-multiplier-style updates while delegating the inner subproblem to a quantum primitive (Grover-based search in Y4, QHD in this paper). Both papers explicitly justify the hybrid structure by noting that pure penalty methods are too sensitive under quantum approximation error. AL-QHD targets continuous variables; Y4 targets discrete cardinality constraints — complementary niches of the same family.
Y2 (Quasi-binary QAOA + iterative refinement, portfolio). Y2 used an iterative refinement loop combined with a quasi-binary QUBO encoding; this paper's adaptive-zoom refinement is the QHD-grid analogue. Both decouple final solution accuracy from per-iteration qubit count; both motivate the technique by qubit scarcity on near-term hardware. Worth a side-by-side comparison: AL-QHD's zoom is wavefunction-marginal-driven, whereas Y2's refinement is bit-flip/perturbation-driven on a discrete encoding.
Y3 (QAOA DGMVP portfolio, NISQ vs FT). Y3 concluded that thermal relaxation precludes quantum advantage at NISQ for the DGMVP portfolio, but shot-noise-only regimes show favourable scaling. AL-QHD reaches a strictly stronger version of the same conclusion for ACOPF: even a noiseless gate count of $\sim 4.46\times 10^7$ entangling gates already rules out NISQ, and $\sim 9.42\times 10^8$ $T$ gates places ACOPF firmly in the early-FT regime. The authors cite Liu et al. on quantum power-flow but do not cite Y3 — a citation in either direction in future work would be natural.
Y1 (warm-started QAOA). Indirect connection: the iterative-zoom procedure can be read as an iterative warm-starting where the “state” being warm-started is the search box rather than the variational parameters. Different mechanism, same philosophy of exploiting prior coarse solutions to seed sharper subsequent ones at fixed quantum resource.
Y5 (GW SDP via Pauli-sparse Gibbs). Method overlap is shallow but not zero: AL-QHD's potential evolution is a sum of Pauli-$Z$ strings of bounded locality (since the ACOPF objective is a polynomial in one-hot indicators); Pauli-sparsity-aware compilation tricks from Y5's domain (and adjacent work like the 2605.11016 Pauli-pair counting paper in today's digest) could in principle reduce the dominant potential-side $T$-count.
Y6 (PBR on Heron2). No meaningful overlap.
Recommended action for Yuan
- Read — high priority. This is the closest non-Yuan paper today to Y4's ADMM-quantum philosophy and to Y2/Y3's constrained-optimization portfolio framing. The end-to-end resource analysis (NISQ + FT) on a real grid problem is exactly the kind of comparison that strengthens the framing of Y3 and Y4.
- Cite in next ACOPF/portfolio-adjacent draft. When updating Y3 or pushing Y4 toward continuous-variable extensions, AL-QHD is a natural reference point as the QHD-side counterpart to your QAOA/Grover-side resource conclusions. Because they did not cite Y3 or Y4, citing them gives you the chance to set the comparison framing first.
- Consider a short note or follow-up. The iterative-zoom mechanism in this paper is a natural object to compare side-by-side with Y2's iterative quasi-binary refinement. A 1–2 page comparative analysis (or an appendix in a future paper) could illuminate when wavefunction-marginal zoom beats bit-flip refinement and vice versa.
- Reach out to authors. The PNNL/Pitt group (Liu, Wu, Stein) is active in quantum optimization for power systems — an introductory email pointing at Y3 (portfolio) and Y4 (ADMM) would land naturally given the explicit topical overlap and would not require any reciprocal citation to be in place yet.