Comparing Qubit and Qudit Encodings for EV Charging and Trip Assignment Problems
Abstract
Variational quantum algorithms have attracted attention for their potential to solve combinatorial optimization problems. We study how the choice of encoding affects the resource requirements and optimization behavior of a variational quantum optimization algorithm. In order to quantify these effects, realistically inspired constrained electric vehicle (EV) fleet management problems were considered. These problems couple determining the optimal EV battery charging schedule with assigning EVs to trips requested by customers. We compare a conventional binary (qubit) trip encoding with an integer (qudit) encoding that represents assignments more directly. Both encodings guarantee the same feasible solution set, while the qudit encoding exponentially reduces the required Hilbert-space dimension. We solve many random instances of highly constrained uni- and bi-directional charging problems using qudit-based quantum approximate optimization algorithm (QAOA) and thoroughly evaluate the performance results. We find that the qudit encoding of customer trips achieves similar or better optimization performance at much reduced resource requirements and shorter simulation runtime. These results highlight qudit-native encodings as a practical route for integer and multi-valued scheduling problems in variational quantum optimization.
Executive summary
Ekström, Wang and Schmitt run QAOA on an EV-fleet charging+trip-assignment problem under two encodings: a conventional one-qubit-per-(EV,trip) binary encoding and an integer one-qudit-per-trip encoding whose value names the assigned EV (or 0 if unserved). Both encodings cover the same feasible set, but the qudit encoding shrinks Hilbert-space dimension exponentially in the number of trips R and EVs NEV. Across bi-directional (d=3, NEV=3, T=2, R=2) and uni-directional (d=2, NEV=2, T=3, R=2..4) instances, the qudit encoding matches or slightly beats the qubit one on success probability and mean energy gap, with substantially lower variance and dramatically faster simulation runtime. The result is the most direct empirical cousin to Y2's quasi-binary encoding argument in the published literature so far — same thesis (compact integer-aware encoding beats native binary on constrained QAOA), different problem class (EV fleet vs. portfolio optimization), and a published qudit mixer recipe Yuan can reuse.
Main contribution
The paper isolates encoding choice as a single experimental variable. In both formulations the charging variables ln,t are qudit (d-ary) integers, mixed via a Bottarelli/Deller-style angular-momentum mixer HX=β1,lΣi Lix + β2,lΣi (Liz)2. Only the trip-assignment variable changes: rn,i∈{0,1} (qubit, one per EV-trip pair) versus qi∈{0,...,NEV} (qudit, one per trip; qi=0 means unserved). The integer encoding removes the one-EV-per-trip constraint automatically, since equal qi values are forbidden only across overlapping trips. Hilbert dimension scaling is dim(Hint)/dim(Hbin) = 2−RNEV+R log2(NEV+1), i.e. exponentially smaller in R for any NEV≥2.
Key algorithms / experimental protocol
- Problem family (§II): NEV EVs across T discrete time-steps, R trip requests with overlap constraints, SOC bounds En0→Enmin, grid power bounds Pmin..Pmax, charging cost ctln,t, unserved-trip penalty λ.
- Cost Hamiltonian (Eq. 13): HC = C({l→Lz, r→Rz, q→Qz}) + α Σ Ee + α Σ Ff, with equality/inequality penalties enforced via |·| and Heaviside Θ.
- QAOA ansatz (Eq. 14): U(γ,β) = ∏l=1..L e-iHX(βl) e-iγlHC, equal-superposition initial state.
- Mixer (Eq. 15): the Lx mixer plus a (Lz)2 "squeeze" term — qudit-native, gives two mixing parameters per layer (3L total parameters vs. 2L for the pure-qubit case).
- Optimizer: SciPy Powell, 200 iterations, M=256 shots per cost evaluation.
- Benchmarks: 10 random instances per problem class; (a) bi-directional d=3, NEV=3, T=2, R=2 (Hilbert dims 46656 qubit vs 11664 qudit); (b) uni-directional d=2, NEV=2, T=3, R∈{2,3,4} (dims {1024,4096,16384} vs {576,1728,5184}).
- Metrics: mean energy gap ΔEmean, min energy gap ΔEmin, feasible-sample fraction f, success probability r over Nruns=10 runs.
Detailed walkthrough
The setup (§II–III) is a clean ablation: the only thing changing between treatments is how trip assignment is represented. In the binary encoding, the algorithm must learn — through penalty terms — that two rn,i=1 entries for the same trip i (different EVs n) is forbidden; the integer encoding makes that constraint physically impossible because qi takes a single value per trip. Concretely, the equality penalty E1=Σ|Rzn,iLzn,t| present in the qubit case is replaced by Σ|δqi,nLzn,t| in the qudit case — the latter is sparser and triggers only on the single n that qi selects.
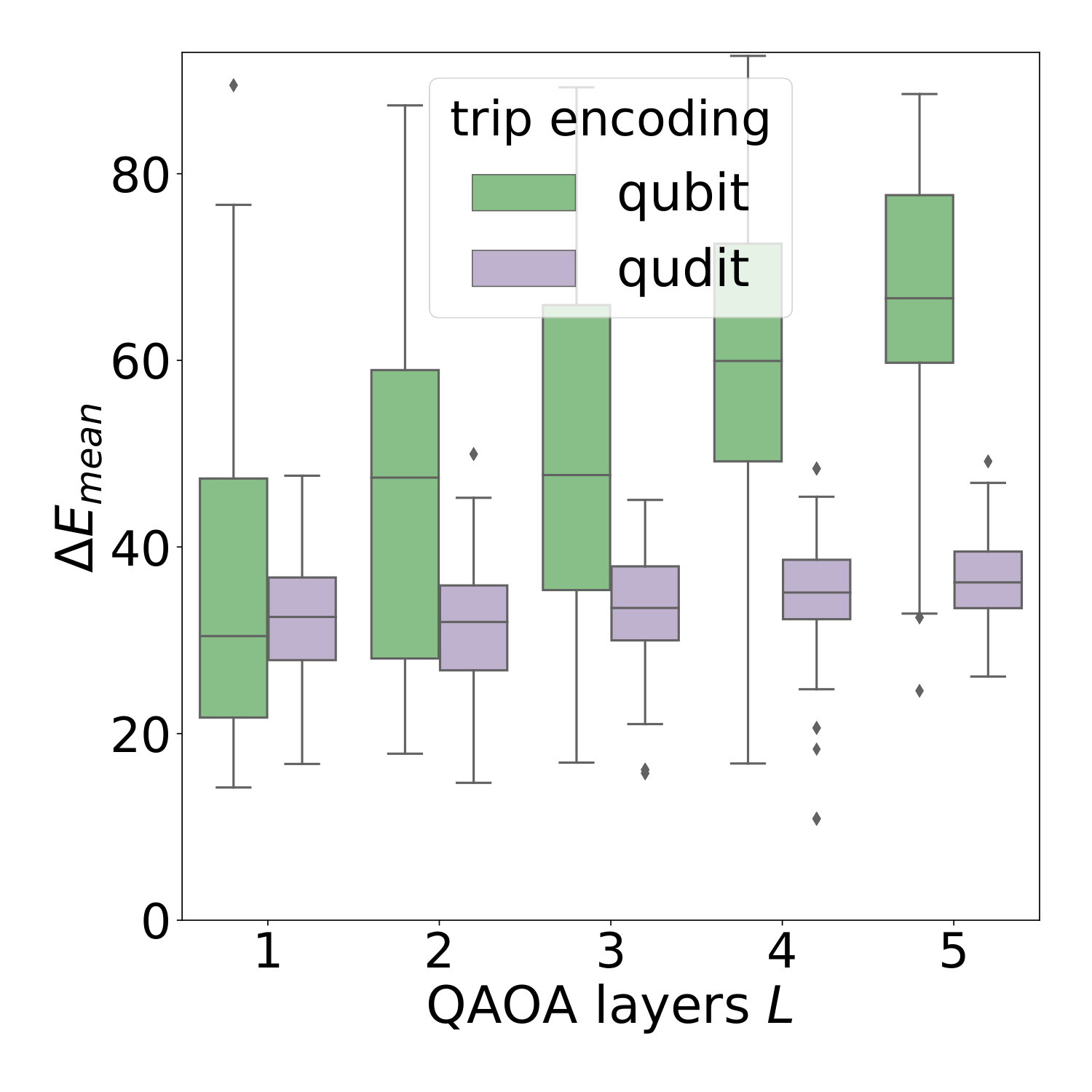
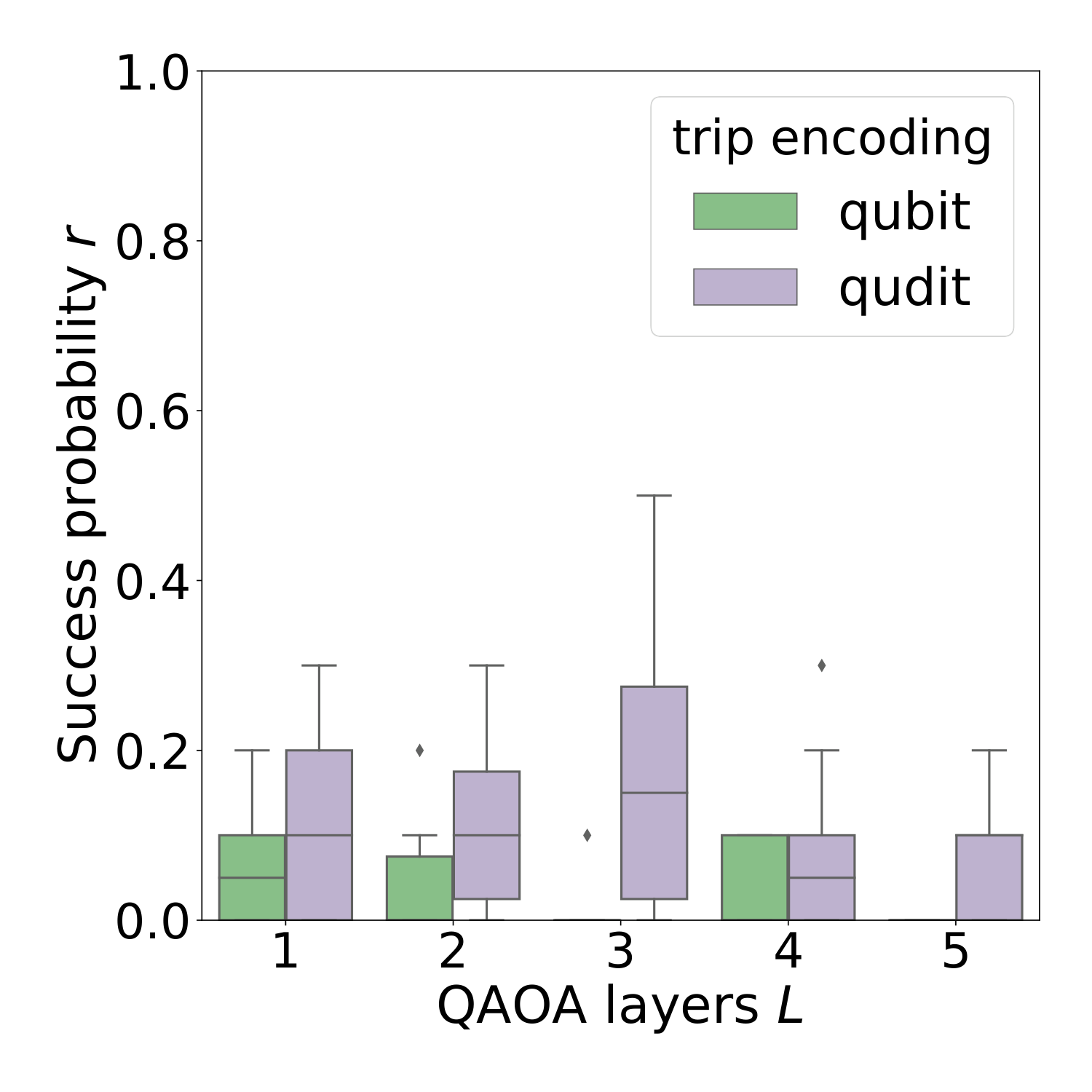
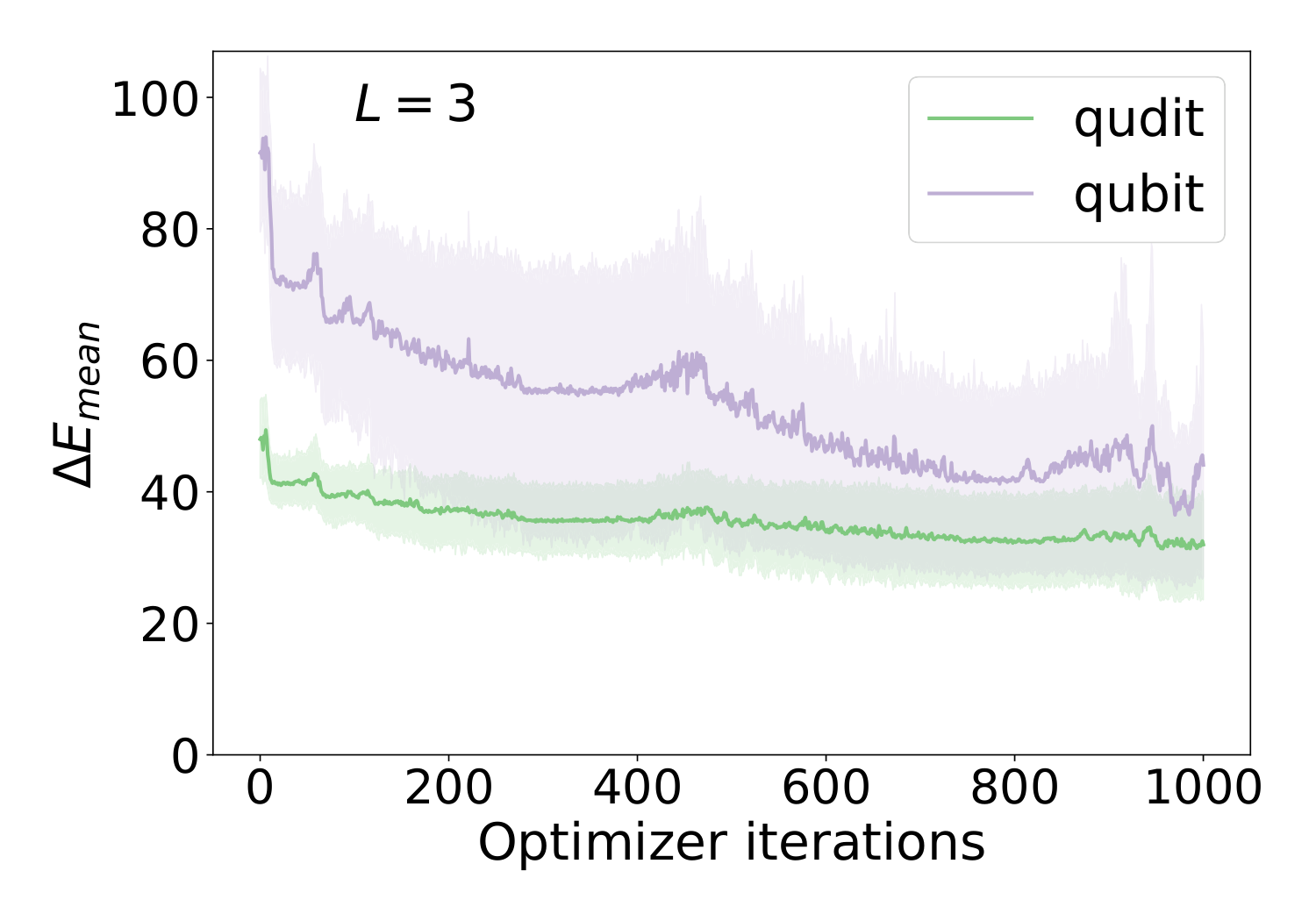
§IV.A's bi-directional results (Fig. 4) are the headline plot. Across QAOA depths L=1..10 the qudit encoding produces lower ΔEmean with substantially tighter inter-instance variance, and a higher success probability. Most strikingly, the qubit encoding's performance degrades with circuit depth, while the qudit encoding stays flat. The authors trace this to the 200-iteration Powell cap (Fig. 6): for the qubit Hilbert space (46656-dim), 200 iterations isn't enough — both encodings converge to similar limits when run for 1000 iterations, but at the 200 cap the qubit case is still mid-descent. So the "encoding advantage" here is partly an interaction with a fixed compute budget — exactly the realistic regime Y3 worried about for QAOA-DGMVP under shot/iteration limits.
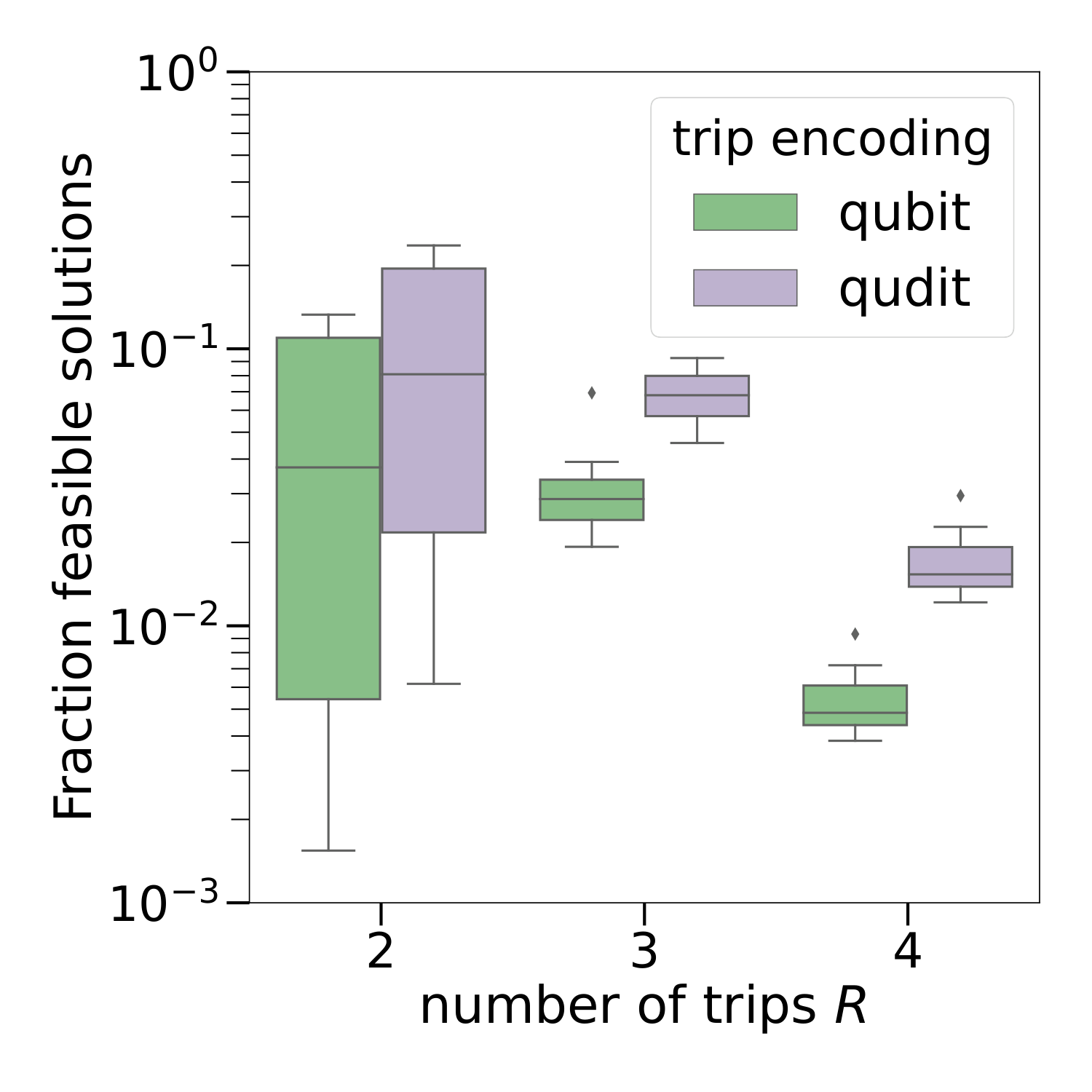
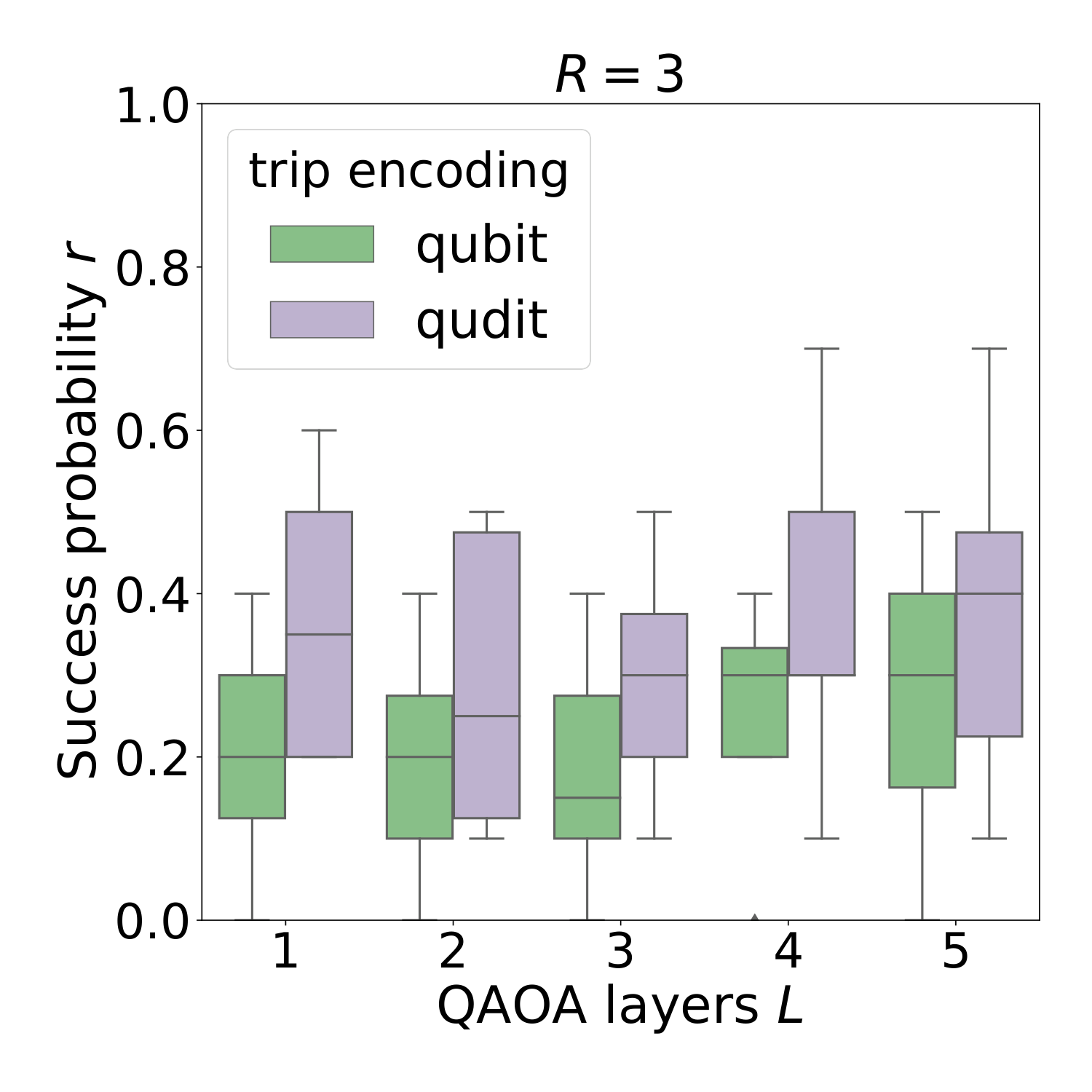
§IV.B's uni-directional sweep over R=2,3,4 (Fig. 8 for R=3) tightens the case: the qudit encoding has more variational parameters per layer (3L vs 2L, since (Lz)2 is non-trivial only for qudits with d>2), so it is structurally disadvantaged in a budgeted optimization. It still wins on success probability across all R, suggesting the dimension reduction outweighs the parameter-count penalty. As R grows the problem becomes more constrained — feasible-state fractions drop from ~20% to ~0.1% (Fig. 1) — and the qudit encoding's advantage grows accordingly: shrinking the Hilbert space matters more when feasibility is rare.
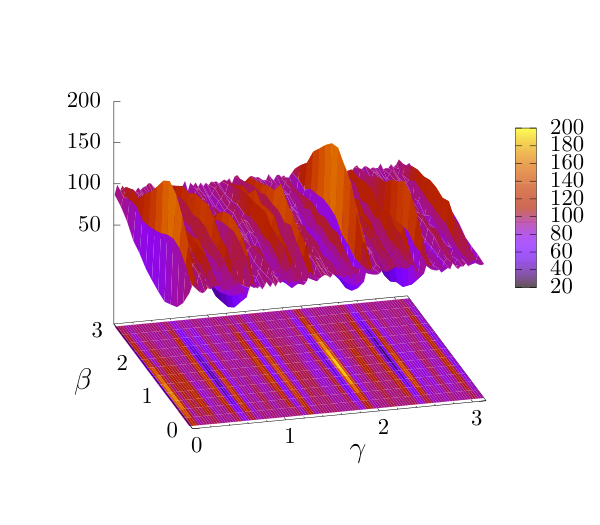
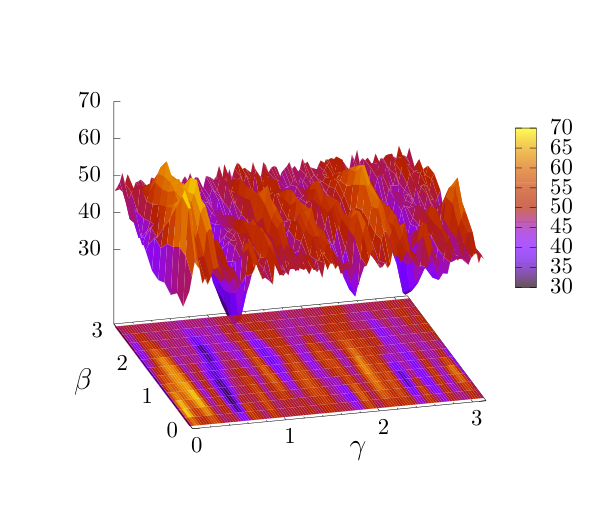
The cost-landscape visualization (Figs. 2–3) is qualitative but informative. Both landscapes are oscillatory and shot-noisy at M=256, but the qubit landscape sits at roughly 3× higher energy scale because its infeasible-configuration mass — penalized heavily — is exponentially larger. This bears directly on QAOA's signal-to-noise ratio: when most of the wavefunction sits in penalty-dominated regions, the cost gradient is dominated by infeasibility rather than by the actual objective, and Powell wastes iterations climbing out of the penalty plateau.
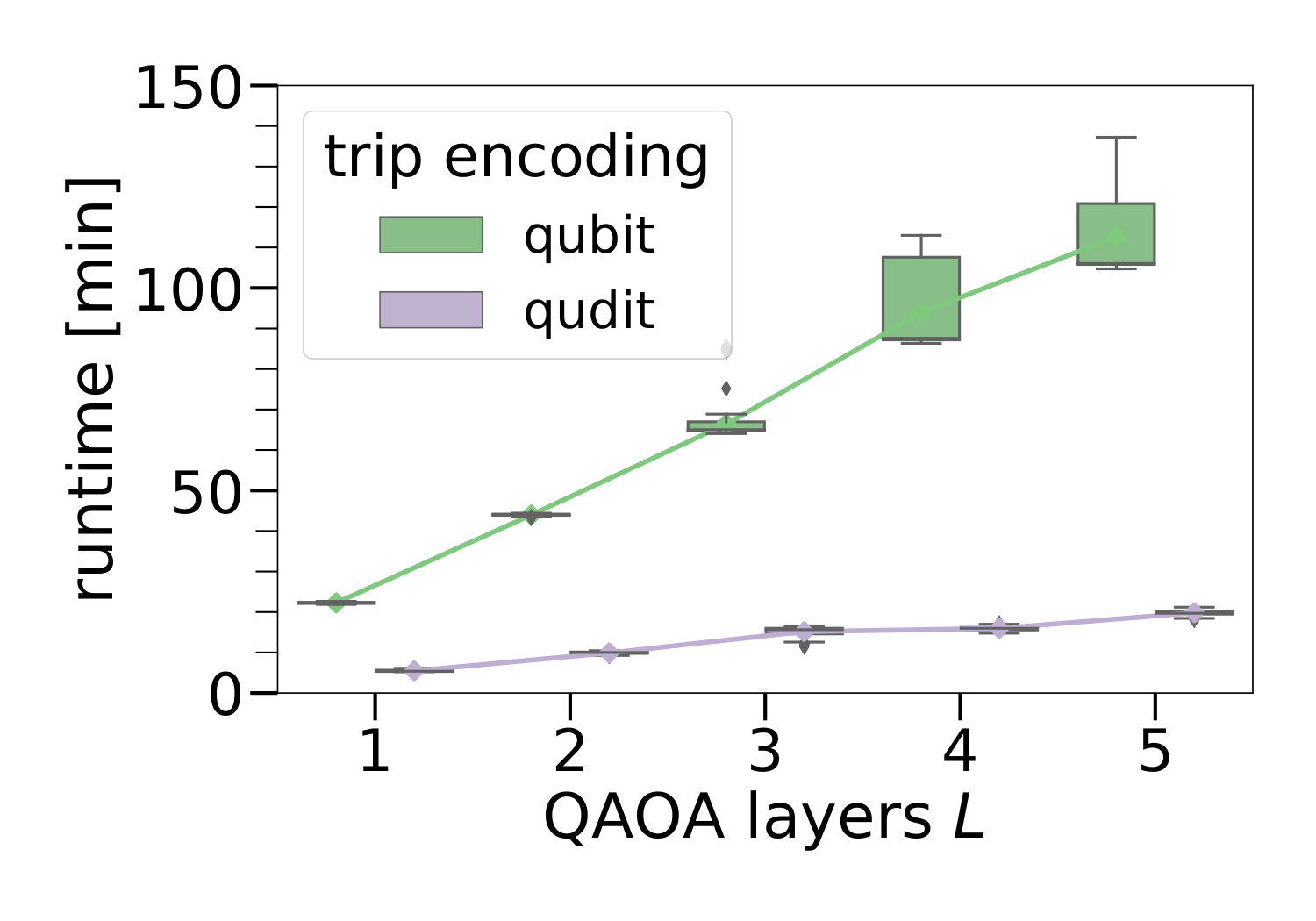
The runtime plot (Fig. 7) shows the qudit advantage in raw classical-simulation time, ~order-of-magnitude faster. The authors caveat that this doesn't directly translate to hardware gate counts — that would require explicit circuit compilation under realistic constraints (cited Bottarelli 2024 for constraint handling) — but it does serve as a representational-complexity proxy. The §V conclusion explicitly flags that scaling and hardware-realistic implementations are the natural next step.
The paper does not test against vanilla QAOA-with-XY-mixer, hard-constraint mixers (Hadfield-style), or CVaR-QAOA — all of which Y2 used or contributed to. The omission is acceptable for an isolated encoding study, but it leaves open the question of whether the qudit encoding still wins when combined with stronger constraint-preserving mixers, and conversely whether quasi-binary encoding (Y2's intermediate point between binary and qudit) would land somewhere in between.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary encoding, CVaR-QAOA, hard mixers, portfolio): the strongest alignment. Y2's quasi-binary encoding occupies ~2log2(U-L+1) qubits per variable — an intermediate point between this paper's pure binary (NEV qubits per trip) and qudit (one qudit per trip). The motivating thesis is identical: native, integer-aware encodings of constrained combinatorial variables outperform binary expansions, because they shrink the infeasible mass that QAOA otherwise has to learn to avoid via penalties. This paper extends the same idea to scheduling under SOC and grid constraints, on different hardware primitives (high-dimensional qudits) than Y2 used. A direct head-to-head — quasi-binary vs. qudit on the same EV problem, or vs. binary on a portfolio instance — would be a clean Y2 extension.
- Y3 (QAOA-DGMVP portfolio, layerwise optimization, shot-noise scaling): shared concern with realistic constrained-optimization regimes and the fact that, under fixed shot/iteration budgets, the encoding (and the resulting circuit/optimizer complexity) determines whether the algorithm converges in time. Y3 found dual annealing + layerwise to be most robust; this paper uses Powell with a fixed iteration cap. The cap-induced degradation observed here is the same phenomenon Y3 worried about for QAOA-portfolio under thermal noise.
- Y4 (Grover + ADMM for cardinality-constrained binary opt): tangential. Cardinality constraints are conceptually related to the one-EV-per-trip constraint (which the qudit encoding absorbs structurally), but the methods diverge — this paper sticks with variational QAOA rather than amplitude-amplification.
- Y1, Y5, Y6: minimal overlap.
Recommended action for Yuan
- Cite in any future Y2-extension paper. This is the cleanest 2026 statement of the encoding-matters thesis on a constrained scheduling problem; Y2's portfolio quasi-binary work and this paper's EV-fleet qudit work are sister contributions and should reference each other in the next iteration.
- Run quasi-binary on the EV problem. Since both encodings here are sub-optimal in different ways — binary has too many qubits and infeasibility; qudit needs a (Lz)2 mixer term that doubles the parameter count per layer — Y2's quasi-binary encoding (log2(NEV+1) qubits per trip) is the obvious intermediate to test. This would be a low-cost extension benchmark that strengthens Y2's positioning.
- Consider co-authoring a follow-up with the Honda/Leiden team. They have engineering-relevant constrained problems, the Bottarelli-Deller qudit mixer toolkit, and the (Lz)2 "squeeze" recipe that would slot directly into a Y2-style hard-mixer framework. The paper's §V explicitly calls for broader benchmarks against "industrially relevant constrained optimization problems with sparse feasibility" — a portfolio testbed would fit.