Optimal FALQON for Quantum Approximate Optimization via Layer-wise Parameter Tuning
Abstract
Feedback-based adaptive quantum optimization (FALQON) is a promising approach for solving combinatorial problems on noisy intermediate-scale quantum (NISQ) devices, requiring only single circuit evaluations per layer. However, standard FALQON relies on fixed hyperparameters that severely limit convergence speed, requiring hundreds to thousands of layers for acceptable solutions. This paper proposes Optimal FALQON, an optimization-based formulation that treats the per-layer time step (δk) and scaling factor (Mk) as decision variables optimized via classical methods. We present a comprehensive empirical study on all 94 non-isomorphic 3-regular graphs with 12 vertices, comparing Optimal FALQON with standard FALQON and multiple QAOA variants. Results demonstrate statistically significant improvements in success probability, evaluation efficiency, and depth-normalized cost across the evaluated benchmarks. Furthermore, initializing QAOA with parameters from Optimal FALQON yields superior warm-start performance compared to fixed initialization.
Executive summary
Mancini and Sodagari turn FALQON's fixed-hyperparameter feedback rule into a per-layer two-dimensional optimization over the time step δk and a scaling factor Mk, fitted with the Powell gradient-free optimizer. On the entire ensemble of 94 non-isomorphic 3-regular graphs with N=12 vertices — the same problem family as Y1's MaxCut benchmark — this single change moves median success probability from ~0.004 to ~0.22 (a 50× gain) at depths L=1–10. The bigger story for Yuan is the warm-start coupling: using Optimal FALQON's converged parameters to initialize QAOA and QAOA-MA pushes median Psucc to ~0.28, beating both fixed init and warm-starts from standard FALQON, validated by Wilcoxon/Holm with α=0.05. This is exactly the warm-started-QAOA pipeline Y1 advocated, instantiated from a feedback-control seed rather than from an intermediate measurement-based bias.
Main contribution
Standard FALQON (Magann et al. 2022) uses Lyapunov-style feedback to set γk, βk at each layer in closed form from commutator expectations Ak, Bk, Ck, but the rule is parameterized by a fixed step δ and gain w, requiring hundreds–thousands of layers to converge. The paper retains FALQON's analytical structure — γk=δk, and βk a first- or second-order function of Ak-1, Bk-1, Ck-1 — but treats (δk, Mk) as decision variables solved per layer via Powell minimization of <Hp>. The same parameter schedule can then be used directly as a depth-L QAOA warm start, with downstream gradient-descent or Powell refinement.
Key algorithms / experimental protocol
- Per-layer update (Eq. 7–8 of §III): γk = δk; βk = −MkAk-1δk (FO) or βk = −Mk|(Ak-1+Ck-1δk)/(2Bk-1δk)|·δk (SO; falls back to FO when |Bk-1|<10−12).
- Per-layer Powell minimization: (δk*, Mk*) = argmin <ψk(δk, Mk)|Hp|ψk(δk, Mk)> with init δk=0.5, Mk=1, max-iter 20, 8192 shots.
- Benchmark ensemble: all 94 non-isomorphic 3-regular graphs on N=12 vertices, MaxCut Ising Hp=Σ(i,j)∈E ZiZj, exhaustive 212-bitstring optimum, depths L=1..10.
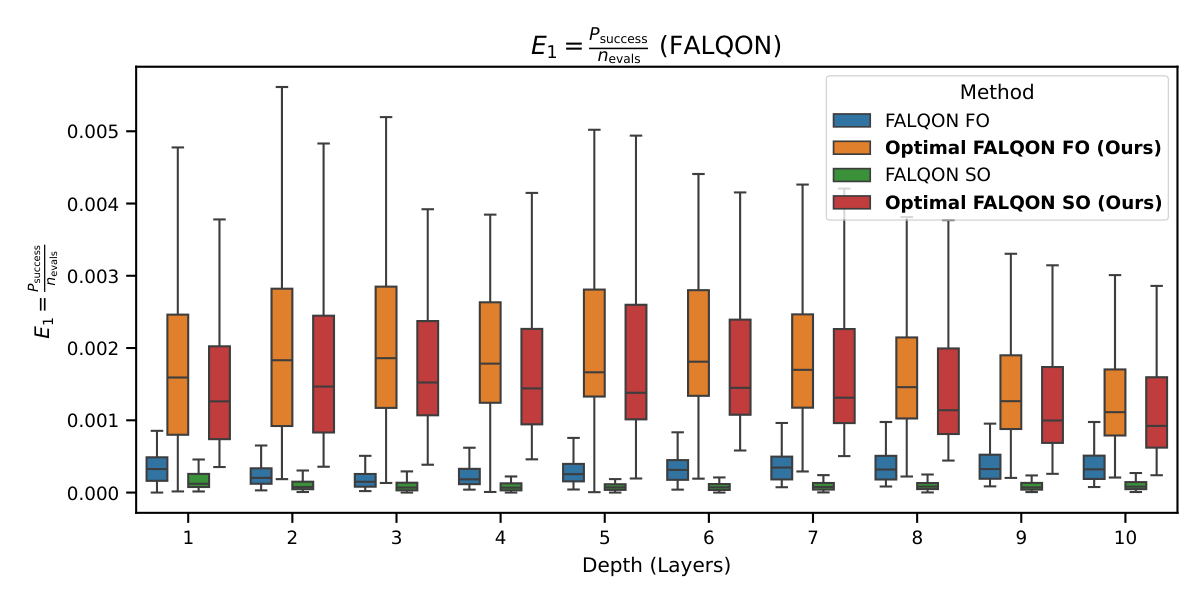
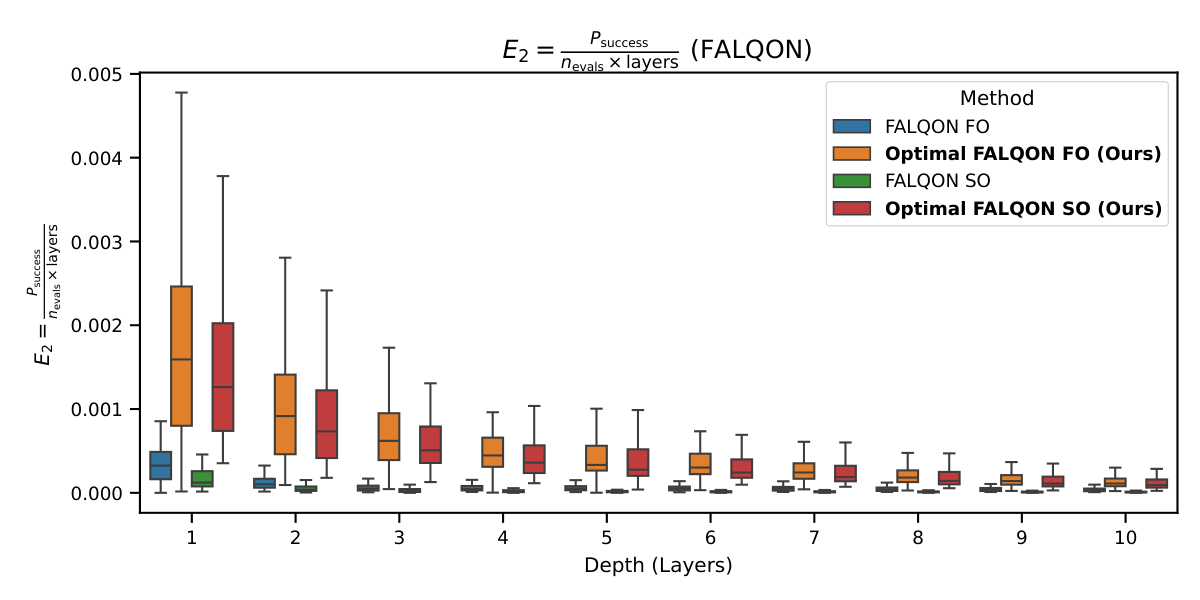
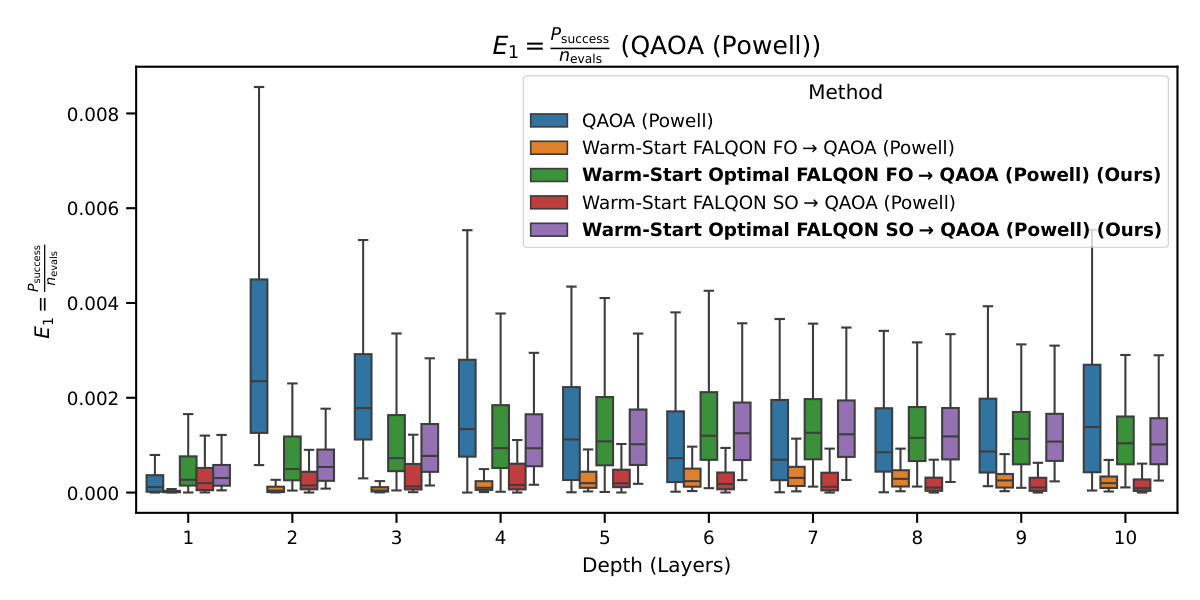
- Metrics: Psucc, evaluation efficiency E1=Psucc/nevals, depth-aware efficiency E2=Psucc/(nevals·L).
- Statistics: paired Wilcoxon signed-rank tests with Holm step-down correction at α=0.05.
Detailed walkthrough
The technical core is §III. The authors observe that recent FALQON refinements (TR-FALQON of Rattighieri 2025; robust gain regularization of Legnini 2025) can all be reinterpreted as introducing per-layer modifications to the step and gain terms, so they unify these via the (δk, Mk) parameterization and let a classical optimizer fit them rather than prescribing them analytically. The cost evaluated at each Powell step is the expectation <Hp> under the current state ψk(δk, Mk). Powell is chosen over Nelder-Mead/COBYLA on the basis of Alam et al. 2021's reliability comparison for noisy quantum optimization landscapes; the fallback condition |Bk-1|<10−12 prevents division-by-zero in SO.
Section IV's benchmarking is deliberately exhaustive within its scope. The 94-graph ensemble is the same combinatorial neighbourhood as Y1's 3-regular MaxCut warm-start experiments — but instead of MBQC-style iterative warm-starting, the seed comes from FALQON's converged control schedule. The shot budget of 8192 per circuit evaluation is sufficient for the small (n=12) problem and a fair comparison vs. fixed-init QAOA-MA, whose multi-angle parameter vector blows up to Np+Nd degrees of freedom per layer.
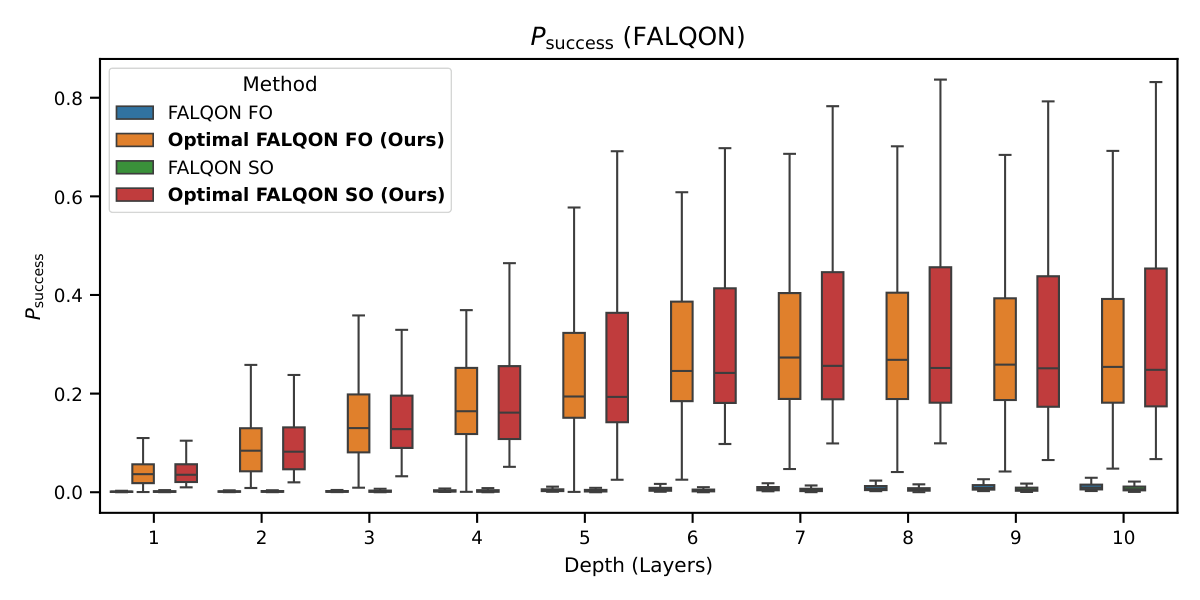
The headline FALQON-family result (Fig. 1, §IV.A) is the 50× Psucc shift from fixed FALQON (~0.004) to Optimal FALQON (~0.22), holding across all depths. Standard FALQON's failure isn't a discovery — its slow convergence has been documented — but the side-by-side at matched depth crystallizes how much is left on the table by fixed (δ, w). The E1 (Fig. 2) and E2 (Fig. 3) plots confirm that the win isn't bought by extra circuit evaluations: even after dividing by nevals·L, Optimal FALQON dominates by 5–24×.
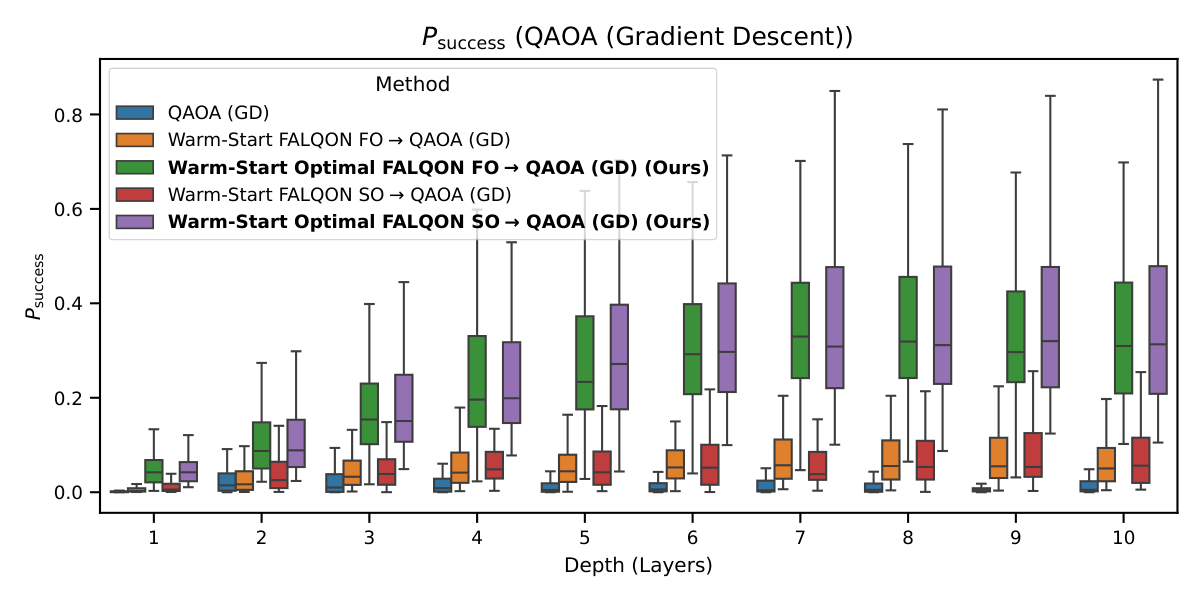
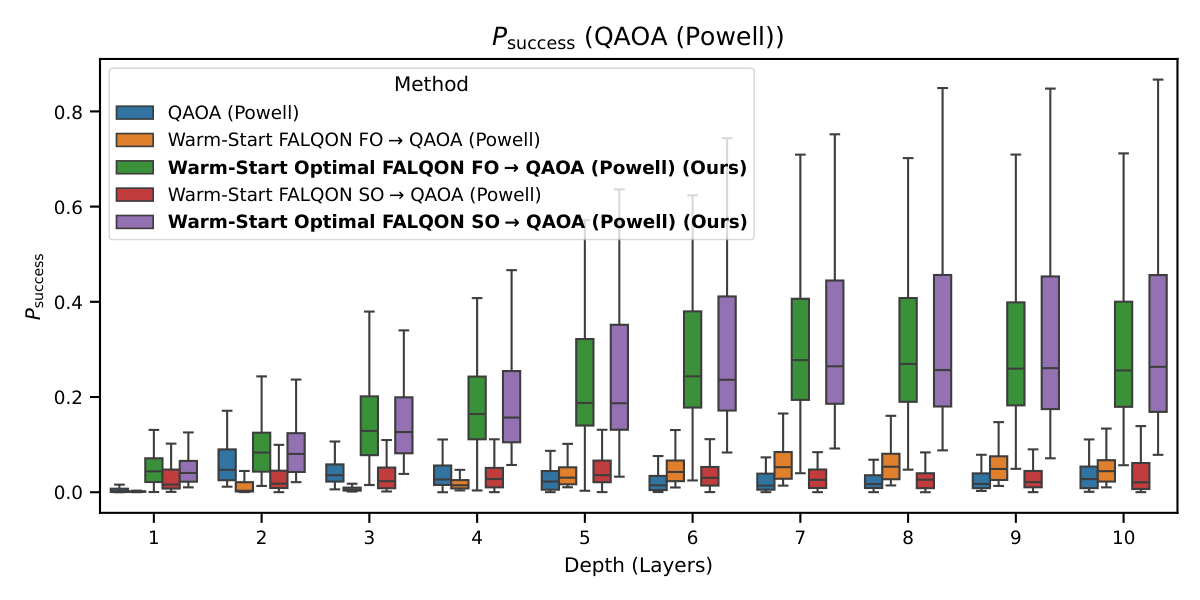
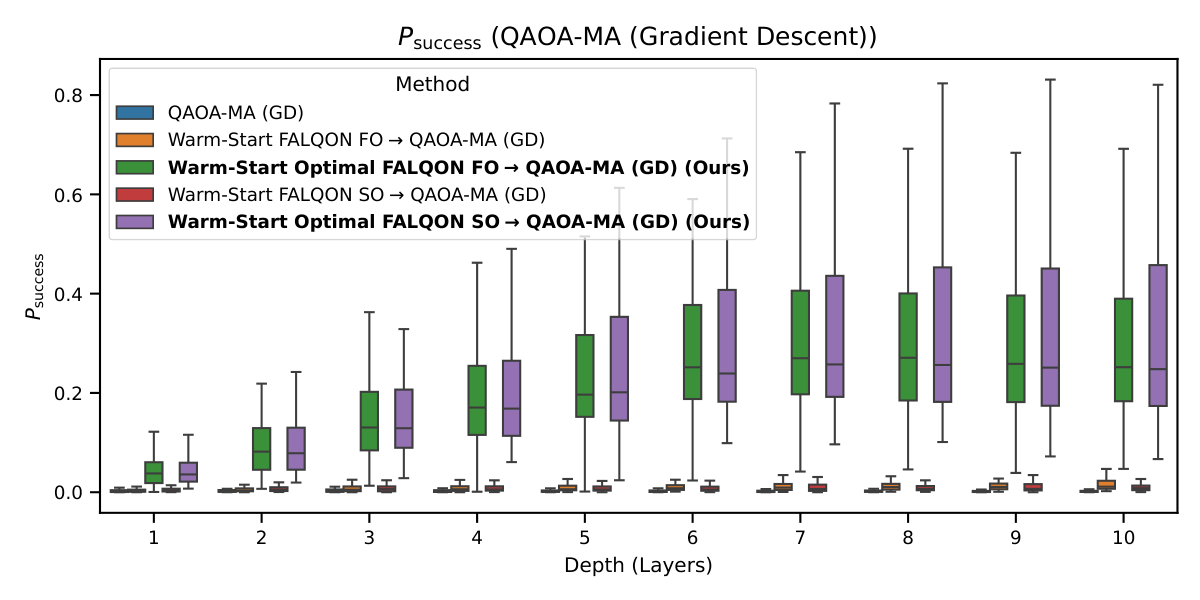
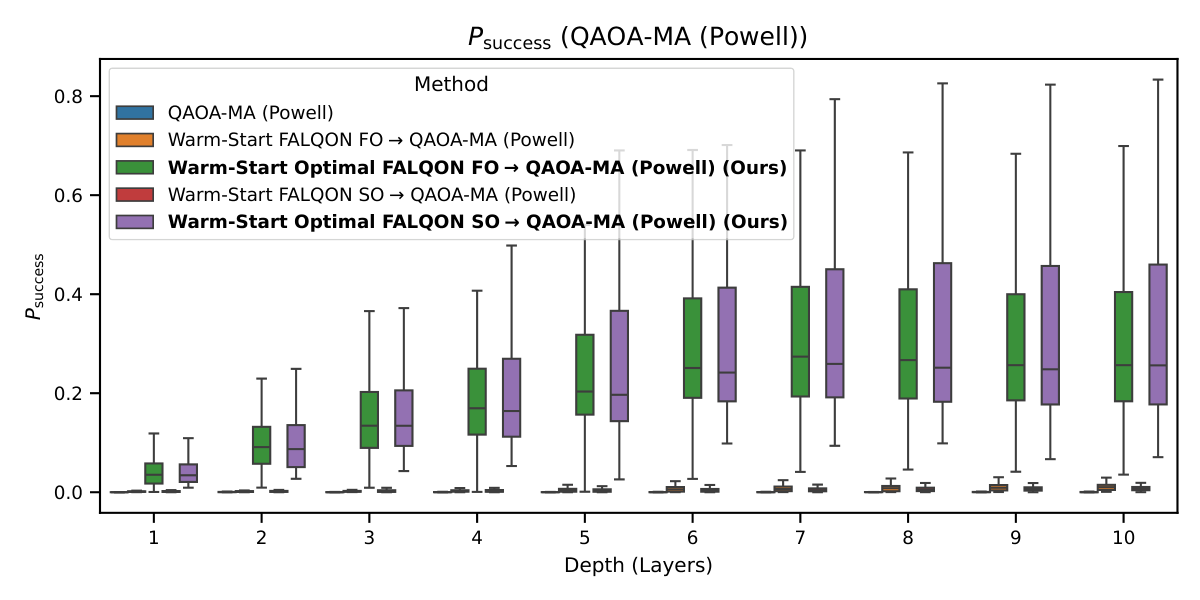
The downstream-QAOA results (§IV.B–E, Figs. 4–7) are where the paper crosses into Y1 territory. Three initialization regimes are compared: fixed (γ=0.5, β=0.5), warm-start from standard FALQON, and warm-start from Optimal FALQON. Both QAOA and QAOA-MA, optimized by gradient descent or Powell, are evaluated. The medians (Table II of §IV.F) tell a consistent story:
- QAOA-GD: 0.005 → 0.045 → 0.263–0.284 (fixed / standard-warm / Optimal-warm).
- QAOA-MA-GD: 0.002 → 0.007 → ~0.22.
- QAOA-MA-Powell: 0.0001 → 0.003 → ~0.27.
The Wilcoxon/Holm tests confirm warm-start-from-Optimal-FALQON is statistically distinguishable from all baselines at α=0.05, across most depths. A subtler observation (§V) is that fixed QAOA (Powell) achieves competitive results at L=2 and L=10, suggesting that warm-start value is depth-dependent. There is no detailed analysis of why these particular depths are special — that's a gap worth probing if Yuan wants to position Y1's iterative warm-start as the "next generation" beyond this paper's classical warm-start hand-off.
Other notable details: the FO vs. SO comparison within Optimal FALQON shows no statistically significant advantage for SO (padj>0.05 in most depths) — the extra Bk, Ck commutator measurements don't pay off; the authors recommend FO. Practitioners are reminded of the dollar economics: at $10/evaluation on commercial NISQ services, the E1 gain translates roughly 1:1 into reduced cost-per-solution.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (warm-started QAOA for 3-regular MaxCut): direct parallel. Both papers focus on warm-starting QAOA on 3-regular graphs and on improving the approximation ratio / success probability via better initial parameters. Y1's seed is a measurement-derived bias on the initial state; this paper's seed is a feedback-control parameter schedule. Y1 reports improved approximation ratio and DGMVP-like scaling; this paper reports a 50× Psucc jump. Methodologically distinct but conceptually aligned — and complementary, since one could imagine combining Y1's MBQC bias state with Optimal FALQON's per-layer schedule.
- Y3 (layerwise optimization most robust for QAOA-DGMVP): direct method overlap. Both papers find that layerwise / per-layer parameter tuning outperforms global optimization. Y3 used dual annealing + layerwise for portfolio DGMVP; this paper uses Powell + per-layer for MaxCut. The mechanism — collapse the high-dimensional landscape into per-layer two-parameter problems — is the same idea on different problems.
- Y2 (quasi-binary encoding, CVaR, iterative refinement): partial alignment. Both Y2 and this paper iteratively refine QAOA parameter schedules layer-by-layer. The encoding axis is unrelated (this paper uses native qubit MaxCut).
- Y4/Y5/Y6: minimal overlap. The paper neither uses Grover/SDP nor performs hardware foundations tests.
Recommended action for Yuan
- Cite in next QAOA-warm-start paper. Mancini & Sodagari occupy the same niche as Y1 (warm-start QAOA on 3-regular MaxCut) but via a completely different seed mechanism — they belong in the related-work section, and the comparison framing (their feedback-control seed vs. Y1's MBQC-measurement seed) sharpens Y1's contribution.
- Re-benchmark. The 94-graph N=12 ensemble is small enough that running Y1's iterative MBQC warm-start on the same set, and comparing Psucc at matched depth L=1..10, is a low-cost, high-signal experiment. If Y1 beats Optimal FALQON warm-start on the same ensemble, that is a strong result; if it ties, the paper still becomes a complementary direction (combine them).
- Probe the L=2, L=10 fixed-QAOA anomalies. The paper flags that fixed-init QAOA matches warm-started variants at specific depths but doesn't explain why. Y1's framework (which thinks about MaxCut approximation ratio in terms of measurement-driven warm-start) might offer an explanation rooted in the graph spectrum at those depths.