Quantum Search without Global Diffusion
Abstract
Quantum search is among the most important algorithms in quantum computing, offering fundamentally new approaches to optimisation and information processing. At its core is quantum amplitude amplification, a technique that achieves a quadratic speedup over classical search by combining two global reflections: the oracle, which marks the target, and the diffusion operator, which reflects about the initial state. We show that this speedup can be preserved when the oracle is the only global operator, with all other operations acting locally on non-overlapping partitions of the search register. We present a recursive construction that, when the initial and target states both decompose as tensor products over these chosen partitions, admits an exact closed-form solution for the algorithm's dynamics. This is enabled by an intriguing degeneracy in the principal angles between successive reflections, which collapse to just two distinct values governed by a single recursively defined angle. Applied to unstructured search, a problem that naturally satisfies the tensor decomposition, the approach retains the O(√N) oracle complexity of Grover search when each partition contains at least log₂(log₂ N) qubits. On an 18-qubit search problem, partitioning into two stages reduces the non-oracle circuit depth by as much as 51%–96% relative to Grover, requiring up to 9% additional oracle calls. For larger problem sizes this oracle overhead rapidly diminishes, and valuable depth reductions persist when the oracle circuit is substantially deeper than the diffusion operator. More broadly, these results show that a global diffusion operator is not necessary to achieve the quadratic speedup in quantum search, offering a new perspective on this foundational algorithm.
Executive summary
Burke and Mc Goldrick prove that Grover's quadratic speedup survives without a global diffusion operator: when the state-preparation unitary and target state both decompose as tensor products across a partition of the register, the diffusion reflection can be replaced by a recursion built from local reflections on each partition plus the oracle as the only global operator. For unstructured search this yields O(√N) oracle calls whenever each partition contains at least log₂(log₂ N) qubits, with non-oracle circuit depth reduced by 51–96% on an 18-qubit benchmark at ≤9% extra oracle calls. For Yuan's programme, this is most directly relevant to Y4 (Grover + ADMM for cardinality-constrained binary optimisation), where the same kind of structural amplitude-amplification analysis is the algorithmic core — and the locality-of-diffusion trick may shrink the circuit depth of the Grover stage in Y4's hybrid pipeline on hardware-constrained backends.
Main contribution
The paper introduces a recursive reflection operator W_i built from local partial-diffusion operators S_ψ_i = 𝕀 − 2|ψ_i⟩⟨ψ_i| (each implementable using only A_i, A_i† and a single-register zero-state phase flip), defined by W_i = (S_ψ_i W_{i−1})^{t_i} S_ψ_i (W_{i−1} S_ψ_i)^{t_i} with W_0 = S_x. The central technical result is that despite the exponentially growing reflected subspaces at each recursion level, the principal angles between successive reflections collapse to just two values governed by a single recursively defined angle γ_i obeying sin(2γ_i) = sin(2θ_i) sin(2t_{i−1} γ_{i−1}). With t_i = 1 at every intermediate stage (proven oracle-optimal), this reduces to sin(2γ_m) = ∏_i sin(2θ_i), and the oracle cost of a single round is bounded by C_QAA / ∏ cos(θ_i), where θ_i is the local overlap angle in register i. For unstructured single-target search with equal stage size s, the total cost is bounded above by C_Grover(n) · (∏ cos(θ_i))⁻¹ · (1 − 2^{1−s/2})⁻¹, which converges to the standard √N scaling whenever s ≥ log₂(log₂ N). The non-oracle gates touch at most s qubits per call rather than the full n, dramatically reducing transpiled depth on hardware with limited connectivity.
Key theorems and algorithmic results
- Eq. (proj-prop): Within the invariant subspace defined recursively, the squared projections ‖P_{ψ_i}(S_ψ_i W_{i−1})^{t_i}|ψ_i, φ_{i−1}⟩‖² = cos²(2t_i γ_i) and the orthogonal-complement projection equals sin²(2t_i γ_i), regardless of the state in lower registers — the degeneracy that enables a scalar recursion despite exponential subspace growth.
- Closed-form success per stage (Eq. stage_succ): ‖P_{x_m}(S_ψ_m W_{m−1})^{t_m}|ψ⟩‖² = ½[1 − cos(2θ_m)/cos(2γ_m) · cos(2(2t_m+1)γ_m)] with optimal final-stage iterate t_m* = ⌊π/(4γ_m) − 1/2⌉.
- Oracle-complexity bound (Eq. complexity): Per round, C ≤ C_QAA / ∏ cos(θ_i), where the overhead is determined entirely by the local overlaps.
- Total complexity (Sec. unstructured): C_total ≤ C_Grover(n) / [∏ cos(θ_i) · (1 − 2^{1−s/2})], so for s ≥ log₂(log₂ N), both factors converge to unity and overall complexity is asymptotically O(√N).
- Optimality of intermediate t_i = 1: Doubling any intermediate iterate gives at most the same increase in γ_m as doubling t_m, so all gain should be concentrated at the final stage.
- Recursive measurement protocol: After amplifying register m, measure registers 1..m−1 (which collapses register m into a state with high target overlap), then re-initialise and repeat on the remaining qubits — the geometric series of remaining rounds is dominated by the first round.
Detailed walkthrough
The paper sits squarely in the lineage of amplitude amplification: standard Grover/QAA combines two global reflections — the oracle S_x marking the target, and the diffusion S_ψ reflecting about the prepared state. The authors observe that whenever A = ⊗_i A_i and |x⟩ = ⊗_i |x_i⟩ are tensor-product structured, the diffusion S_ψ factorises as well, and the question becomes: can a recursive combination of single-register local diffusions and the global oracle reproduce the quadratic speedup? The answer is yes, with a quantifiable overhead.
The construction (Sec. 3, "Quantum Search without Global Diffusion") proceeds register-by-register: W_0 = S_x is the oracle itself, and each subsequent W_i conjugates an additional local reflection S_ψ_i by t_i iterations of the previous level. The key analytic step (Sec. proof) shows that the operator S_ψ_i W_{i−1} is a product of two reflections whose reflected subspaces have dimension 2^{i−1}; ordinarily one would expect the action to be governed by 2^{i−1} distinct principal angles. The authors prove instead that these collapse to just two values γ_i and π/2 − γ_i, with γ_i obeying the scalar recursion sin(2γ_i) = sin(2θ_i) sin(2t_{i−1} γ_{i−1}). This is the structural surprise of the paper: a high-dimensional reflection product is, in effect, two-dimensional.
The consequence (Sec. final_complexity) is that each round of the algorithm produces a Grover-like rotation on a small subspace. With t_i = 1 for all intermediate i (shown oracle-optimal in Sec. final_complexity by comparing the marginal effect of doubling intermediate vs. final iterates), the angle simplifies to sin(2γ_m) = 2^m sin(θ) ∏ cos(θ_i), the optimal iteration count is t_m* = ⌊π/(4γ_m) − ½⌉, and the per-round cost is bounded by C_QAA / ∏ cos(θ_i). After amplifying register m, the algorithm measures the other registers, which collapses register m into a state with overlap close to |x_m⟩ on the span {|ψ_m⟩, |ψ_m^⊥⟩}; the remaining registers are re-prepared and the search recurses on the shrinking space.
The total-complexity bound for unstructured search with equal stage size s (Sec. unstructured) is C_Grover(n) · (∏ cos(θ_i))⁻¹ · (1 − 2^{1−s/2})⁻¹. The first factor reflects local-overlap overhead and converges to 1 for s ≥ log₂(log₂ N); the second is a geometric-series correction (1/(1 − 2^{1−s/2})) capturing the cost of recovering the remaining stages — at s = 4 it equals 2, at s ≥ 6 below 1.15. So the O(√N) scaling is preserved with mild constant overhead at modest stage sizes.
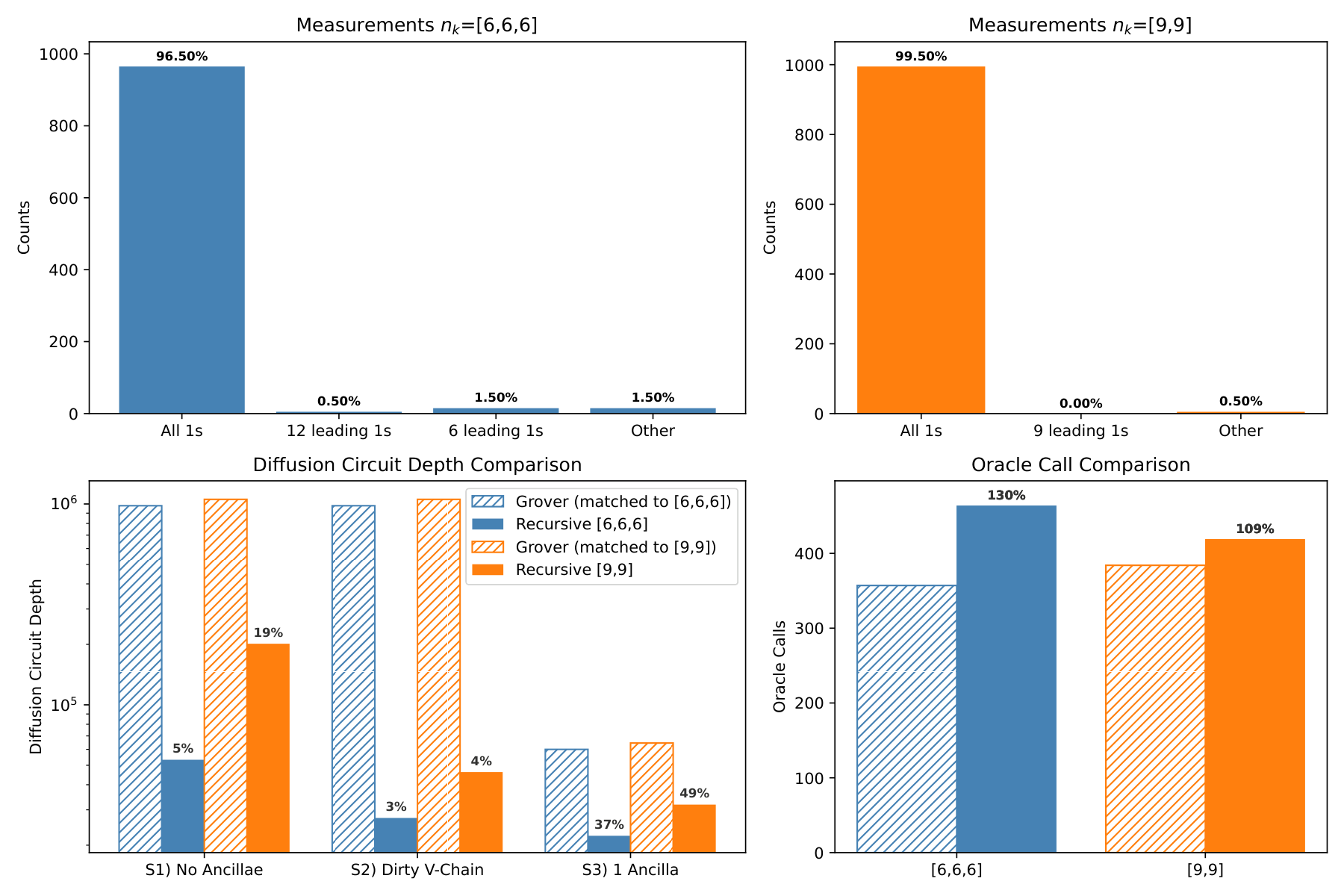
The verification (Sec. evaluation) uses noiseless Qiskit simulation on an 18-qubit search for |1⟩^⊗18. Two configurations are tested: 3-stage [6,6,6] with iterates (102, 25, 6) and 2-stage [9,9] with iterates (201, 17). Measured success matches theoretical prediction within 0.3%. The 3-stage configuration achieves 96.5% success vs. Grover's 99.99% — slightly below, but with dramatically shallower diffusion. Useful additional structure: ~57% of the failing 3-stage shots still have the correct first-stage substring, so when only a prefix of the target is needed (e.g., the "block" in partial-search settings), the effective success probability climbs. Depth comparisons (transpiled to a fully connected topology with CX) across three multi-controlled-X decomposition scenarios — S1 no ancillae, S2 dirty V-chain using idle qubits as borrowed ancillae, S3 one clean ancilla — show non-oracle depth reductions of 95% / 81% (S1), 97% / 96% (S2), and 63% / 51% (S3) for 3-stage / 2-stage respectively, at the cost of 30% / 9% extra oracle calls.
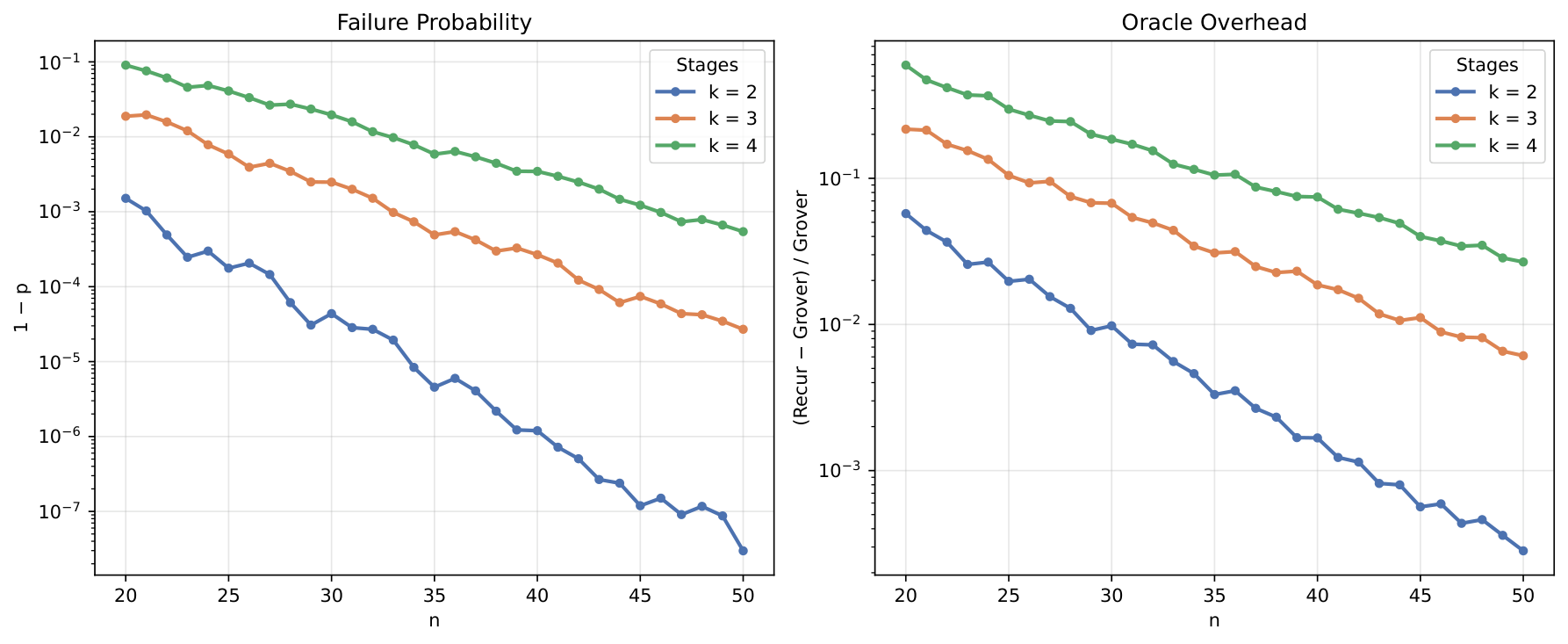
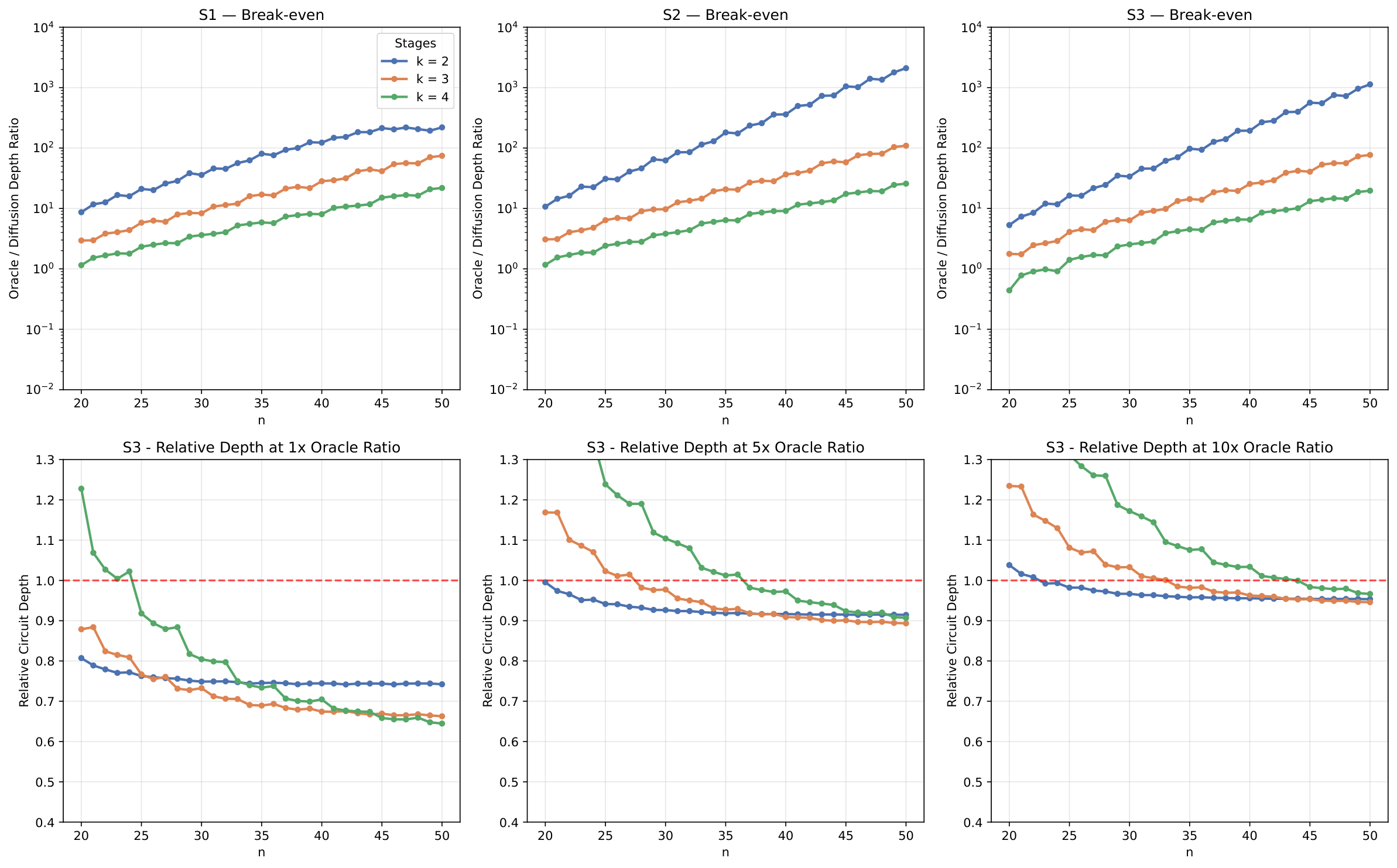
The scaling analysis (Sec. scaling) extrapolates analytically to n = 20–50 qubits with k = 2, 3, 4 stages. Failure probability and relative oracle overhead both decrease with n at fixed stage count — the 2-stage configuration's failure rate falls from 2·10⁻³ at n = 20 to below 10⁻⁷ at n = 50, with overhead dropping from 5% to 0.1%. The 4-stage configuration starts at ~10⁻¹ failure / 55% overhead and improves to below 10⁻³ / under 5%. The break-even oracle-to-diffusion depth ratio also scales favourably: at n = 50 under S2, the 2-stage scheme breaks even when the oracle is up to ~10³× as deep as the diffusion; 3-stage and 4-stage break even at ~10² and ~30 respectively. A crossover appears at large n where deeper-stage configurations become more depth-efficient — for AES-128, with an estimated 10× oracle-to-diffusion depth ratio, the recursive scheme would still yield ~5% total depth savings.
The conceptual payoff is clean: the quadratic Grover speedup is not tied to the global character of the diffusion operator. It survives as long as the diffusion factorises across a partition matching the tensor structure of the prepared and target states, with the oracle remaining the lone global operator. This re-positions the diffusion's role from "essential for the quadratic speedup" to "essential only for non-product initial/target states", and suggests new directions in oracle design that exploit local diffusions natively.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y4 (Grover + ADMM for cardinality-constrained BO): direct method-axis overlap. Y4's algorithm runs Grover over the cardinality-constrained feasible space with O(√(C(n,k)/M)) oracle rotations; the present paper offers a recipe for replacing the global diffusion in such a Grover loop with local diffusions on a partition that matches the structure of the prepared state. For Y4's feasibility-projected initial state — which is naturally a structured (e.g., Dicke-state-like) superposition — the tensor-product assumption is non-trivial but a related register-wise factorisation may apply to specific encodings. Worth checking whether the cardinality-preserving initial state in Y4 admits a partition that satisfies the decomposition condition.
- Y1 (iterative warm-started QAOA, DGMVP MaxCut): mostly distinct — Y1 is QAOA, not amplitude amplification — but the underlying theme (warm-starting from a structured initial state that overlaps the target) is conceptually parallel. The local-overlap angles θ_i in this paper play the same algebraic role as overlap angles in warm-started QAOA analyses.
- Y3 (QAOA DGMVP): tangential. Both papers concern hardware-noise-aware circuit-depth budgets, but Y3 is parameter optimisation under thermal relaxation, not amplitude amplification.
- Y2, Y5, Y6: no meaningful overlap.
Recommended action for Yuan
- Read deeper and consider citation in the Y4 follow-up. The recursive-diffusion construction is exactly the kind of NISQ-depth-saving structural result that would strengthen Y4's hardware section. The 18-qubit Qiskit verification is fresh and the depth-vs-oracle-cost trade-off is quantitatively characterised — useful as a comparator.
- Test whether Y4's cardinality-constrained initial state admits a tensor-product partition. If a Dicke-state-style preparation can be approximated by a product over qubit-block registers (e.g., via fragmentation into balanced subsets), the recursive scheme could plug into Y4's Grover loop and reduce its diffusion depth substantially. If it cannot, the Sec. 4 non-tensor-case discussion in this paper may still apply.
- No need to email authors yet. The result is self-contained and the Qiskit code is public per their "Code Availability" section.