Second-Order FALQON Parameter Transfer for the Max-Cut Problem on 3-Regular Graphs
Abstract
The Feedback-based Algorithm for Quantum Optimization (FALQON) offers a deterministic alternative to variational quantum algorithms by bypassing classical optimization loops. However, maintaining convergence on large problem instances often requires restricting the time step, necessitating quantum circuit depths that exceed Noisy Intermediate-Scale Quantum (NISQ) hardware capabilities. This paper investigates the parameter transferability of second-order FALQON applied to the Max-Cut problem on 3-regular graphs. Through numerical experiments evaluating quantum circuits up to 16 layers on graphs up to 24 nodes, we demonstrate a highly advantageous scaling behavior: transferring feedback parameters optimized on small instances to larger target graphs yields significantly higher approximation ratios than natively optimizing the parameters directly on the larger graphs. This performance advantage arises because parameters trained on smaller instances can safely adopt aggressively larger time steps. By offloading the expensive parameter discovery phase to small-scale instances, this transfer strategy simultaneously reduces computational overhead and enhances the approximation ratio, thereby bringing FALQON closer to practical viability on near-term quantum architectures.
Executive summary
The authors take FALQON — a deterministic, feedback-driven cousin of QAOA in which the layer parameters βk are computed online from measured commutator expectation values rather than chosen by a classical optimiser — and show that for 3-regular Max-Cut, the (Δt, βk) sequence learned on a tiny n=6 graph transfers to graphs up to n=24, where it actually beats native re-optimisation at fixed depth (l=16). The mechanism is precisely the warm-starting intuition Yuan exploits in Y1: native optimisation on a larger instance is forced to retreat to ever-smaller Δt to preserve monotone convergence, which strangles state evolution within a fixed circuit-depth budget. The transferred parameters smuggle in a larger Δt that the small-instance landscape "safely" sanctioned, giving more useful state motion per layer. For Yuan's programme, this is the closest analogue to Y1's iterative warm-start logic that has appeared on arXiv this announce cycle.
Main contribution
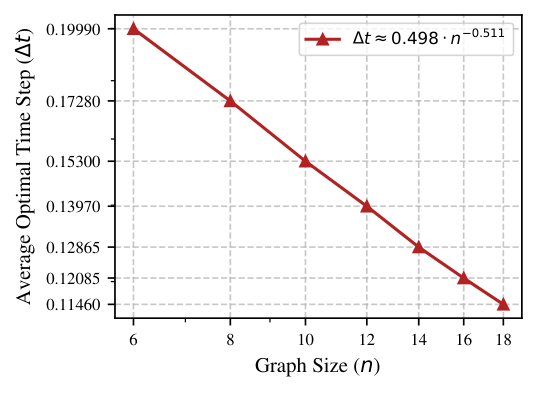
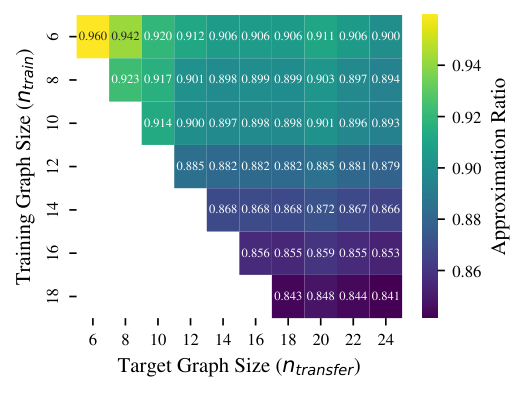
For second-order FALQON applied to Max-Cut on 3-regular graphs, the authors empirically establish (i) that the optimal time step decays as Δt ≈ 0.4984 · n−0.5110 ≈ 1/(2√n), formalising the small-step bottleneck that natively-trained 16-layer FALQON suffers as n grows; and (ii) that transferring (Δt, βk) from a small training graph (especially ntrain=6) to a larger target graph yields strictly higher approximation ratios than the native run, across all ntarget ∈ {6,…,24}, averaged over a 20×20 cross-evaluation per (ntrain, ntarget) pair. The paper reframes parameter transfer not as "good-enough re-use" but as an algorithmic improvement in its own right: it lets a depth-16 circuit access the larger-Δt regime that small instances tolerated, side-stepping the depth/Δt trade-off the second-order discretisation was designed to relax.
Key results / algorithmic ingredients
- Algorithm — second-order FALQON feedback law: at layer k, set βk = −(⟨A⟩k + Δt ⟨C⟩k) / (2 Δt ⟨B⟩k), where A = i[HM, HC], B = ½[[HM, HC], HM], C = [[HM, HC], HC]. Layer evolution: |ψk+1⟩ = e−iΔt βk HM e−iΔt HC |ψk⟩.
- Empirical scaling law (Section IV): the optimal Δt averaged over 20 random 3-regular graphs per size obeys Δt ≈ 0.4984 · n−0.5110 ≈ 1/(2√n) on the interval [0.1, 1.0] swept at resolution 0.001.
- Transfer protocol (Section IV): for each (ntrain, ntarget) with ntrain ≤ ntarget, evaluate all 20×20=400 pairs, applying (Δt, βk) from the source's optimum to the target's HC; report mean approximation ratio.
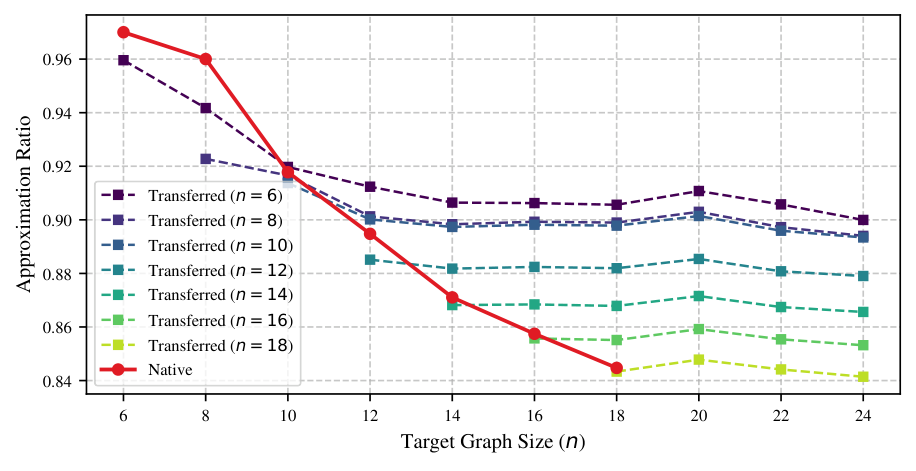
- Headline empirical result (Section V, Figure 3): transferring from ntrain=6 yields a near-flat approximation-ratio curve in ntarget, while native optimisation degrades steadily — at large ntarget, the transferred-from-6 curve is well above native.
- Mechanism (Section V): at n=6 the optimum sits near Δt≈0.20; at n=24 native picks Δt≈0.115. The larger borrowed Δt drives more state motion per layer, and the second-order feedback law's enhanced stability permits this without divergence.
Detailed walkthrough
Setup. Section II frames Max-Cut canonically as ground-state preparation of HC = −½ Σ(i,j)∈E(1 − ZiZj) with the standard transverse-field mixer HM = Σ Xi. FALQON in its original first-order form picks βk = −⟨A⟩k with A = i[HM, HC]; this guarantees a monotone decrease of ⟨HC⟩ in the small-Δt limit but at the cost of a depth that grows as 1/Δt for fixed accuracy. Second-order FALQON (Arai et al. 2025, cited as [arai_scalable_2025]) augments the feedback law with ⟨B⟩k and ⟨C⟩k nested-commutator terms, giving βk = −(⟨A⟩k + Δt ⟨C⟩k) / (2 Δt ⟨B⟩k). The point of the second-order correction is precisely to let the practitioner pick a larger stable Δt — and the transfer experiment in this paper exploits that headroom.
Numerical protocol. Section IV describes the scan: for each n ∈ {6, 8, …, 24}, generate 20 random 3-regular graphs (the standard Y1 ensemble); for the training subset ntrain ∈ {6, 8, …, 18}, sweep Δt ∈ [0.1, 1.0] at step 0.001, run 16 FALQON layers, and pick the (Δt, {βk}) that maximises the approximation ratio at layer 16. An early-stopping rule terminates the sweep when divergence is detected. Ground-truth Max-Cut energies for normalising the approximation ratio are computed by classical simulated annealing per graph instance. The averaged optimal Δt vs. n is fitted on log-log axes (Figure 1) and produces the n−0.511 power law.
Transfer evaluation. The cross-evaluation matrix in Section IV runs 400 (source-graph × target-graph) trials per (ntrain, ntarget) cell with ntrain ≤ ntarget; the cell value is the mean approximation ratio after 16 layers when the source's (Δt, βk) drive the target's HC. The full matrix is rendered as the Figure 2 heatmap; the diagonal is the natively-optimised baseline.
The non-intuitive finding. Section V is where the paper does its real work. Naïvely, one would expect transfer quality to degrade as the structural mismatch (here, just |ntrain − ntarget|) grows. Instead, transferred approximation ratios are nearly flat in ntarget, and native optimisation degrades. The authors' diagnosis: native optimisation is a victim of its own caution. As n grows, the spectral norm of HC grows, so to remain inside the second-order stability envelope the native optimiser is pushed to smaller Δt — exactly the n−1/2 law of Figure 1. With l=16 hard-capped, that means each native run buys progressively less state motion. The transferred (Δt, βk) from n=6 carries Δt ≈ 0.20 — almost twice what the native optimiser at n=24 dares pick (≈0.115) — and the target run completes more useful evolution per layer.
Section VI's framing — and a Y1 connection. The authors explicitly call this a paradigm shift: the value of the second-order discretisation was supposed to be the larger Δt it tolerates, but native re-optimisation re-tightens Δt as n grows; transfer recovers the freedom that the second-order scheme was designed to give. This is structurally close to Y1's iterative warm-starting story for QAOA — there the warm start is a measurement-induced bias on |ψ0⟩, here the warm start is a (Δt, βk) schedule from a smaller instance. Both move the expensive optimisation off the large-instance critical path and exploit local structural similarity in 3-regular Max-Cut. The honest caveat the authors flag in Section VI — that the success likely depends on uniform local structure (3-regularity) and would not generalise to high-degree-variance graphs — is exactly the limitation that Y1's parameter-concentration / iterative warm-starting story should also be sanity-checked against.
What is and isn't done. No noise simulation: pure noiseless statevector. No hardware execution. No theoretical proof of why transfer works — explicitly listed as future work, alongside (a) extending to larger n, (b) other graph classes / problems, (c) noise resilience, (d) "graph reduction" — i.e., given a large instance, how to algorithmically choose a small representative training graph. The cap at n=24 keeps the entire study in the classically-tractable regime, so the quantum-advantage question is not addressed.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (iterative warm-started QAOA, 3-regular Max-Cut): direct method-and-scope kinship. Both papers attack the same testbed (3-regular Max-Cut, n up to ~24, NISQ-budget circuit depths) and both move the expensive optimisation off the large-instance critical path — Y1 via measurement-based warm-start of |ψ0⟩, this paper via parameter transfer of (Δt, βk) from a small training graph. The core mechanism in both cases is exploiting local structural similarity in 3-regular instances. The 1/(2√n) Δt scaling reported here is a useful empirical lever Y1 could potentially absorb when comparing iterations across graph sizes.
- Y2 (quasi-binary encoding QAOA, hard mixers, portfolio): shared territory of layered ansätze for combinatorial optimisation, but the constraint structure (hard cardinality / encoding) is absent here — Max-Cut is unconstrained binary optimisation, so the mixer choice is generic.
- Y3 (QAOA DGMVP portfolio, layerwise optimisation): Y3's layerwise-optimisation finding has the same flavour — restricting parameter discovery per layer is strictly more robust than naive joint optimisation. This paper's "optimise on small, transfer to large" is a cousin: amortise the optimisation over a smaller workload. Worth cross-citing.
- Y4 (Grover + ADMM cardinality-constrained): no overlap. Different algorithmic family (Grover-search, structured feasible spaces).
- Y5 (GW SDP via Pauli-sparse Gibbs states): tangential — Y5 attacks Max-Cut's SDP relaxation rather than QAOA-style direct optimisation. The contrast with FALQON's cost/time-step trade-off is a useful framing for the Y5 narrative.
- Y6 (PBR on Heron2): no overlap.
Recommended action for Yuan
- Cite in any future Y1 follow-up. This is the cleanest contemporary appearance of "transfer/warm-start beats native at fixed depth on 3-regular Max-Cut" outside of Y1's own warm-start story; the n−1/2 Δt law and the heatmap evidence are useful supporting empirical context for Y1's positioning.
- Read deeper before claiming distinct novelty. The authors are not aware of Y1 (no citation). If Y1's iterative warm-start mechanism subsumes parameter-transfer-from-small-instance as a special case, that is worth documenting. If they are genuinely distinct (Y1's measurement-based warm-start vs. their parameter-schedule transfer), a short comparison paragraph in the next Y1 revision would establish priority cleanly.
- Consider an email to the corresponding author (Evandro Chagas Ribeiro da Rosa, UFSC / Eldorado) pointing to Y1. They appear to be unaware of the iterative warm-start literature; the connection would be welcome and may surface a useful collaboration on the "graph reduction" future-work item, which is exactly the question of how to choose a small representative instance for warm-starting.
- Adapt the n−1/2 Δt scaling as a benchmark. If Y1's iterative scheme implicitly chooses an effective Δt, plotting that against n would let Yuan pin down whether warm-starting buys exactly the "stay at the small-n Δt" headroom this paper isolates, or something stronger.