Quantum Resource Estimation for Minimising Energy Grid Losses
Abstract
Distribution network reconfiguration (DNR) can minimise power losses by identifying the optimal topology of the electricity grid. Determining the minimum loss configuration is NP-hard, and classical optimisation methods struggle to scale to real-world distribution grids. This paper explores the use of gate-based quantum computing to solve DNR for power loss reduction. We formulate DNR as a higher-order unconstrained binary optimisation (HUBO) problem, avoiding the need for auxiliary variables, thereby reducing the required number of qubits. This is applied to a real medium voltage (MV) network operated by Alliander, a Dutch distribution system operator (DSO). For each biconnected component in the network graph, we construct the corresponding HUBO, derive the cost and mixer operators, and determine the number of required logical qubits and rotation gates. These are then mapped to physical qubits and execution time estimates using quantum resource estimation (QRE). The results suggest that the quantum resource requirements depend not only on component size but also on structural characteristics such as connectivity and cyclicity. Overall, the novelty of this work lies in directly framing the optimisation problem as a HUBO, applying it to real-world MV networks, and performing a QRE to assess future feasibility.
Executive summary
The authors take a real medium-voltage distribution grid (Alliander's Arnhem network) and frame the loss-minimising reconfiguration problem directly as a higher-order unconstrained binary optimisation (HUBO), then count the cost-operator and mixer-operator resources needed to run a single QAOA-style optimisation layer on a fault-tolerant gate-based quantum computer. Their main message is sobering: even after biconnected-component decomposition and topological-minor reduction, the largest Arnhem subproblem produces >4×108 HUBO interaction terms, ≈61k logical qubits, and runtime estimates of order 107–109 s per layer under Microsoft's Quantum Resource Estimator. For Yuan, the relevance is twofold: (i) it is a clean, end-to-end resource-estimation pipeline for a different real-world combinatorial application, in the same template Y3 used for portfolio DGMVP; (ii) the explicit "no auxiliary variables" HUBO design is a direct intellectual cousin of Y2's quasi-binary encoding, applied to a different constraint structure (radiality, vertex/edge/cycle/path).
Main contribution
Earlier quantum work on DNR (Silva et al., IEEE TPS 2023; Sci. Rep. 2023) used D-Wave's QUBO formulation, where higher-order constraints are reduced to quadratic form by injecting auxiliary variables. This paper argues that for gate-based devices the auxiliary variables are gratuitous: the QAOA cost layer only requires that the cost function be a polynomial in Z operators, regardless of polynomial degree, so one can keep the formulation as a HUBO and pay only for the additional multi-qubit Pauli-Z rotations. The authors explicitly model four families of constraints — vertex (linear-sum), edge (interaction), cycle (interaction), path (implies) — as polynomial penalties. They then construct a cost operator UHUBO = exp(-iγΣi ci⊗Zj), count Pauli-Z rotation gates, and feed the logical counts into Microsoft's azure-quantum-resource-estimator following Beverland et al. (arXiv:2211.07629).
Key algorithmic primitives
- HUBO penalty toolkit: linear-sum penalty
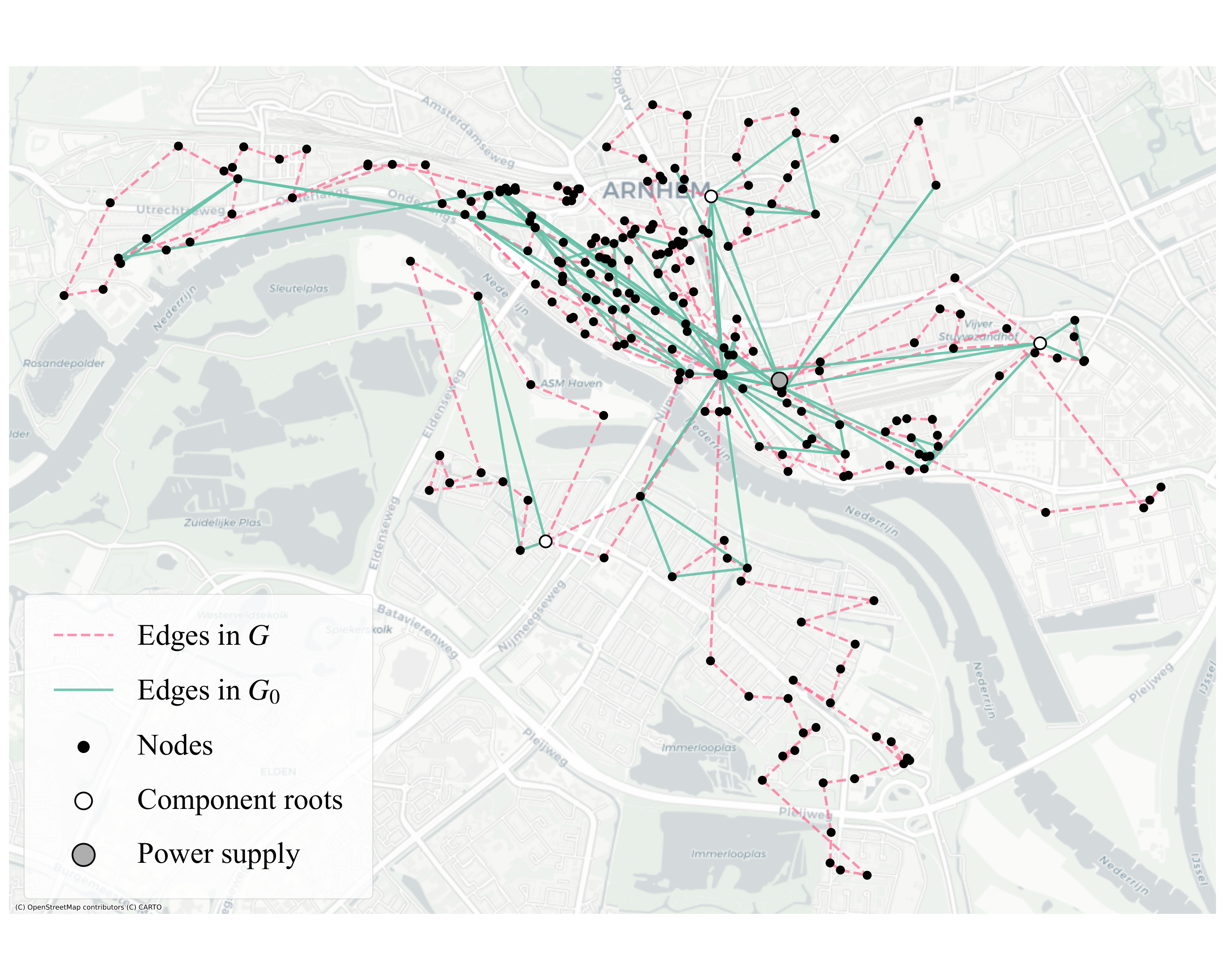
(Σxi-1)2, interaction penaltyΠxi, implies penaltiesxi-xixjandxixj. The four constraint classes (vertex / edge / cycle / path) are each shown to fit one of these primitives. - Graph reduction: the input grid is decomposed into biconnected components (each cycle-containing block is a separable subproblem because the upstream configuration past a cut vertex does not affect downstream load); each component is further reduced to its topological minor by edge lifting on degree-2 vertices, preserving cycle/path structure.
- HUBO → cost operator: standard
x = (1-z)/2spin map, thenUHUBO = Πi exp(-iγci⊗j∈SiZj)using commutativity of Z-strings. No actual circuit synthesis is performed — resource counting is by enumeration of HUBO terms. - Mixer: two single-qubit rotation gates per qubit per layer (standard transverse-field X-mixer).
- Algorithmic targets: the cited downstream algorithms are vanilla QAOA (Farhi et al., 1411.4028) and bias-field digitised counterdiabatic optimisation (Romero et al., Comm. Phys. 2025).
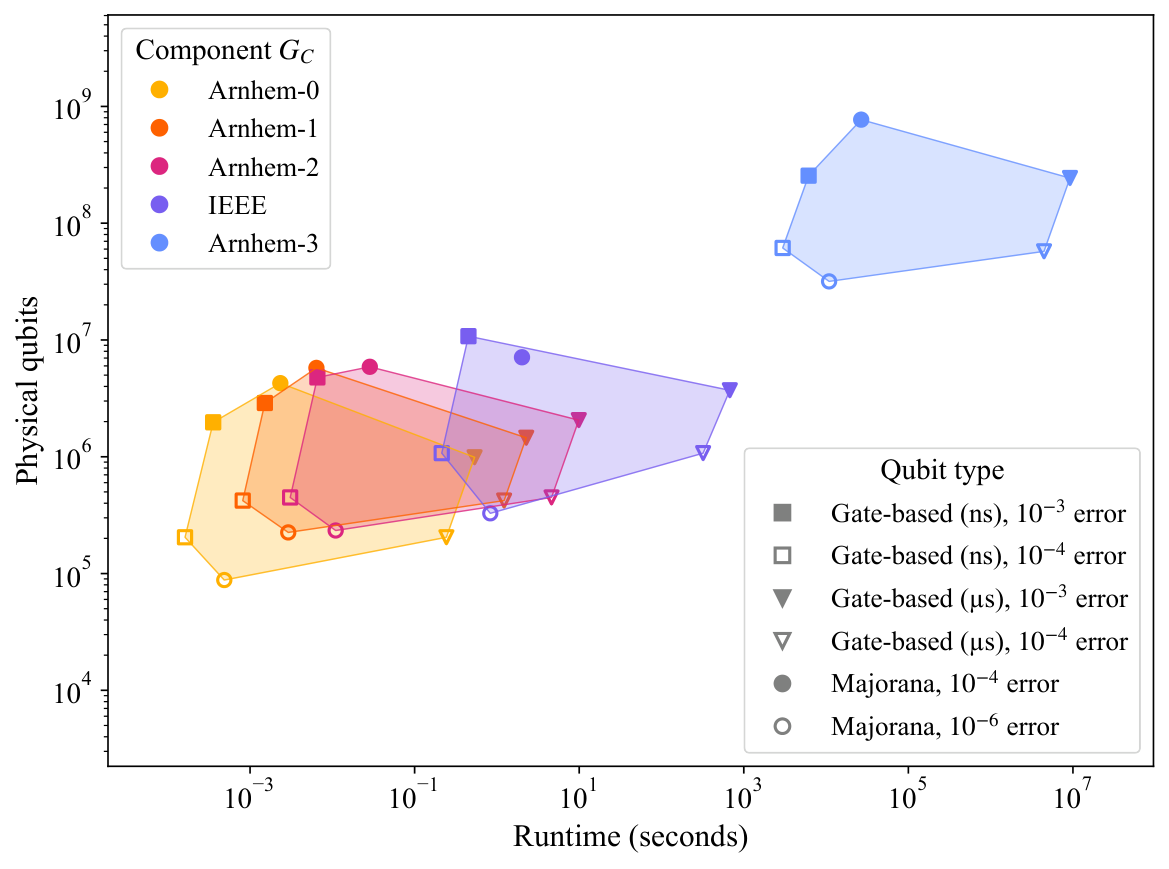
- QRE backend: Microsoft Quantum Resource Estimator (Beverland et al. 2022); six hardware archetypes (four superconducting/ion-trap gate qubits + two Majorana variants); surface-code distance auto-selected from logical depth.
Detailed walkthrough
The paper is short (8 pages) and structured around a single end-to-end pipeline. Section 2 (Methodology) sets up the optimisation: the grid is a directed graph G=(V,E) with switchable edges and node currents ILn; load on edge (u,v) in spanning tree T is Lu,v(T)=|Iu,v(T)|2Ru,v; the optimisation searches over spanning trees T∈ST(G) (radiality is enforced) for the minimum total load. Equation (1) is the canonical objective; equation (2) defines edge currents as sums of downstream node currents.
The size-reduction trick in Section 2 is to decompose G into biconnected components GCi — each is solved independently because cutting the network at a component root does not couple downstream load to the upstream configuration. Trivial components (dyads, trees) are dropped. Each non-trivial GC is then replaced by its topological minor G0 via edge lifting: degree-2 vertices are spliced out, replacing two adjacent edges by a single edge between the two outer neighbours when no edge already exists there. This preserves cycles and paths, so spanning trees of G0 lift to spanning trees of GC.
Section 2.1 (HUBO formulation) is where the paper differs from Silva et al. The four constraint classes are each translated to polynomial penalty terms in {0,1} variables: vertex constraints become (Σixi-1)2 (exactly one incident active edge per non-root); edge consistency becomes a 2-body interaction penalty (at most one direction active per undirected edge); cycle constraints are higher-order interaction penalties built from a cycle basis with virtual edges; path constraints use implies-style penalties to forbid disconnected sub-configurations that satisfy cycle constraints but violate global radiality. The total HUBO is a weighted sum (eqns C.1–C.5 + O.1) of the five constraint classes plus the loss objective; the authors deliberately do not pick λ values, since they only count term cardinality.
Section 2.2 (QRE) does the standard x→z map and emits a Pauli-Z Hamiltonian; one optimisation layer is one cost-operator UHUBO plus one transverse-field mixer Umix. The two reported logical metrics are the qubit count (= number of binary variables in the formulation) and the rotation-gate count (= number of HUBO interaction terms for the cost layer + 2N for the mixer). The authors then push these numbers through the Microsoft QRE under six hardware archetypes spanning gate-time and error-rate combinations; surface-code distance is auto-selected.
Section 3 (Results) reports the headline numbers in the paper's Table 1. The IEEE-33 benchmark (32 nodes, 36 edges; 32-node biconnected component) produces 33,616 interaction terms, 667 logical qubits, 59,296 logical rotation gates — modest by surface-code standards. The Arnhem MV network produces three non-trivial biconnected components: Arnhem-0 (7/3 nodes; 42 terms; 14 logical qubits; 94 gates) and Arnhem-1 (13/3 nodes; 150 terms; 17 qubits; 272 gates) sit comfortably in any future fault-tolerant device; Arnhem-2 (14/4 nodes) jumps to 607 terms, 53 qubits, 1,110 gates; Arnhem-3 (309/65 nodes) explodes to 4.08×108 interaction terms, 61,172 logical qubits, and 4.94×108 logical rotation gates. The QRE figure (their Figure 2) shows worst-case runtime per single optimisation layer of order 107 s — the authors note that a complete QAOA-style schedule would push this to 108–109 s.
The discussion is candid about scope: (i) the HUBO was not solved — only counted; (ii) electrical parameters were omitted because they do not affect QRE; (iii) the comparison HUBO-vs-QUBO in resource terms is left as future work. The most important methodological point for Yuan is on the last page: the authors flag that "more refined estimates could also incorporate more refined techniques, such as advanced quantum error correction or NISQ-based approaches", and a "direct comparison between HUBO and QUBO formulations" — both are precisely the directions that Y2 (quasi-binary, hard-mixer constraint preservation) and Y3 (NISQ thermal-noise crossover) explore in greater depth. The Romero bf-DCQO citation also signals the authors' interest in counterdiabatic warm-starts, the same intellectual lineage as Y1's measurement-based warm-starting.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary portfolio QAOA, arXiv:2304.06915) — method overlap. Y2's central trick is to use ~2log2(U-L+1) qubits per integer variable plus a hard mixer that preserves the constraint manifold without penalty terms. The DNR HUBO paper goes the opposite way on penalties (everything is a penalty term in x∈{0,1}), but shares the same goal of qubit-count reduction by avoiding auxiliary variables. A natural follow-up would be applying a Y2-style hard mixer (instead of the trivial transverse-field X-mixer) to the spanning-tree manifold, which would in principle drop all the >108 cycle/path penalty terms.
- Y3 (QAOA-portfolio DGMVP + QRE, arXiv:2410.16265) — scope overlap. Y3 is the canonical example of end-to-end QRE for a real combinatorial finance problem; this paper is the same template applied to a power-grid problem at a Dutch DSO. Both papers conclude that thermal/runtime budgets dominate. Y3's identification of dual-annealing + layerwise optimisation as the most robust classical-loop combination is directly transplantable here, given Romero bf-DCQO is already on the authors' radar.
- Y4 (Grover + ADMM for cardinality-constrained BO, arXiv:2603.14744) — method/scope overlap. Y4's structured-feasible-space Grover does not strictly apply to spanning trees, but the spirit (use combinatorial structure to suppress search space) is the same as the biconnected-component + topological-minor reduction the DNR paper relies on. The HUBO/cardinality structure differs in form, but a hybrid where Y4-style ADMM handles the loss objective and a Grover oracle enforces radiality is a sensible extension.
- Y1 (warm-started QAOA, arXiv:2502.09704) — method-adjacent. The bf-DCQO citation in this paper is essentially a counterdiabatic warm-start, which is the closest thing in the QAOA-warm-start literature to Y1's measurement-based warm-starting. The same idea (use a tractable approximation as the QAOA initial state) is well posed for DNR and entirely absent from this paper.
- Y5 (GW + Pauli sparsity, arXiv:2510.08292) — weak. The DNR HUBO is highly Pauli-sparse in absolute terms (multi-body Z-strings only) but the authors don't use sparsity as a complexity lever. A Y5-style classical Gibbs-relaxation pre-solver could in principle deliver a near-optimal radial topology that warm-starts the QAOA layer.
- Y6 (PBR/Heron2) — no overlap (foundations vs. optimisation).
Recommended action for Yuan
- Cite this paper as a counterpoint in any future Y3 follow-up. It is the cleanest "QRE for a real-world combinatorial application on Dutch industrial data" reference one can find, and the >108-rotation-gate result is a quotable order-of-magnitude calibration.
- Adapt-method experiment. The Arnhem-2/Arnhem-3 instances are a natural test bed for a hard-mixer (Y2-style) treatment of spanning-tree constraints — if the constraint penalties are absorbed into the mixer, the HUBO collapses to just the loss objective, which is much smaller. Worth a side calculation to estimate the qubit-count saving on Arnhem-2 (53 logical qubits with penalty terms; what does it become with a tree-preserving mixer?).
- Email the authors. The first author Camille de Valk (Alliander/Capgemini/Leiden) is a junior researcher at Leiden Applied Quantum Algorithms; flagging Y2 (quasi-binary) and Y3 (DGMVP QRE) as related work could be welcomed, especially since the paper is preprint-only (CIRED 2026 Brussels). Could be a low-cost reciprocal cite in a v2 revision.