Constraint-Preserving XY-Mixers under Trotterized Adiabatic Evolution
Abstract
Constraint handling remains a central challenge for quantum algorithms applied to combinatorial optimization. Standard approaches based on penalty terms increase problem size, distort energy landscapes, and often degrade algorithmic performance. Constraint-preserving mixers, such as XY-mixers, provide an alternative by restricting quantum evolution to feasible subspaces, but their practical implementation on gate-based hardware requires Trotterization, introducing potentially significant approximation errors. In this work, we systematically study the interplay between constraint-preserving XY-mixers and Trotterized Adiabatic Evolution (TAE). We present a detailed theoretical analysis of the origin and scaling of Trotter errors in XY-mixers and show that the dominant contribution depends on the size and structure of individual constraints rather than on the total problem size. We validate our analysis through extensive numerical simulations on three representative optimization problems: Portfolio Optimization, the Multi-Car Paint Shop problem, and a Multi-Commodity Flow problem… Finally, we also provide a mixer Hamiltonian for the TSP-like 2-way-1-hot constraints.
Executive summary
This paper systematically maps when XY-mixers actually beat Pauli-X mixers under realistic Trotterized implementation. The headline finding inverts the conventional QAOA folklore: a single global k-hot constraint spanning all n variables (e.g. portfolio "select k of n") makes the XY-mixer Trotter error so large that the standard X-mixer with a quadratic penalty becomes more robust in practice. By contrast, when constraints decompose into disjoint local k-hot blocks (Multi-Car Paint Shop, Multi-Commodity Flow), the XY-mixer outperforms X-mixers by several orders of magnitude even under Trotterization. The paper additionally introduces a four-qubit "plaquette" mixer that simultaneously enforces both the row and column 1-hot constraints of the TSP permutation matrix. For Yuan, this is a direct method-level conversation partner with Y2 (quasi-binary portfolio QAOA): both papers attack constraint-preserving mixers for portfolio optimization, but reach opposite conclusions about the right strategy for portfolio specifically.
Main contribution
The paper combines a theoretical analysis of Trotter error in XY-mixers with statevector benchmarks on three structurally distinct problems. Theoretically, the leading-order Trotter error of e−itHXY scales as δt² Σ‖[Ha, Hb]‖, and for a fully-connected n-qubit XY-mixer the number of non-commuting term pairs grows as O(n³). When the n-variable constraint is replaced by m disjoint local k-hot blocks of size n/m, the cross-block commutators all vanish and the Trotter error scales as O(m·(n/m)³). They use Trotterized Adiabatic Evolution (TAE) — a fixed sinusoidal annealing schedule — rather than variational QAOA, sidestepping parameter-optimization noise. The TSP plaquette mixer (Sect. 5.4) commutes with the row+column projector simultaneously, avoiding the standard binary encoding's failure mode where naive XY-mixers preserve only one of the two constraints.
Key theorems and results
- Lemma 2.1 (Dicke states are XY eigenstates): |Dnk⟩ is the highest-energy eigenstate of HXYfull within the k-hot subspace, with eigenvalue 2k(n−k) (proved via Gershgorin's circle theorem).
- XY-ring-mixer non-eigenstate property (Sect. 2.3): Dicke states are not eigenstates of the ring-XY Hamiltonian — degree-counting on |D42⟩ shows non-uniform connectivity (states |1100⟩, |0110⟩ have degree 2 vs |1010⟩, |0101⟩ at degree 4). Justifies restricting to fully connected XY.
- Trotter-error scaling (Sect. 3.1.1): for a global n-variable k-hot mixer, non-commuting pair count is O(n³); for m disjoint blocks of size n/m, the count drops to m·O((n/m)³) since cross-block commutators vanish.
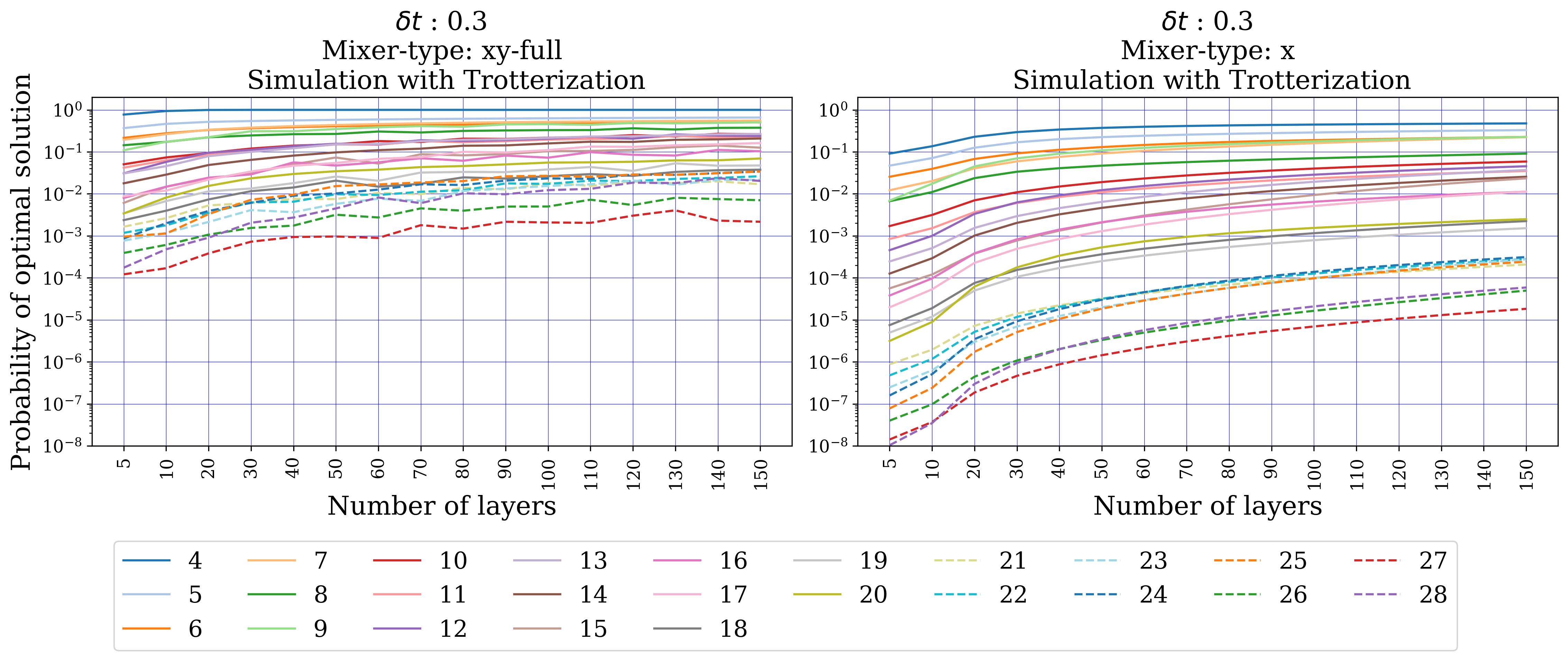
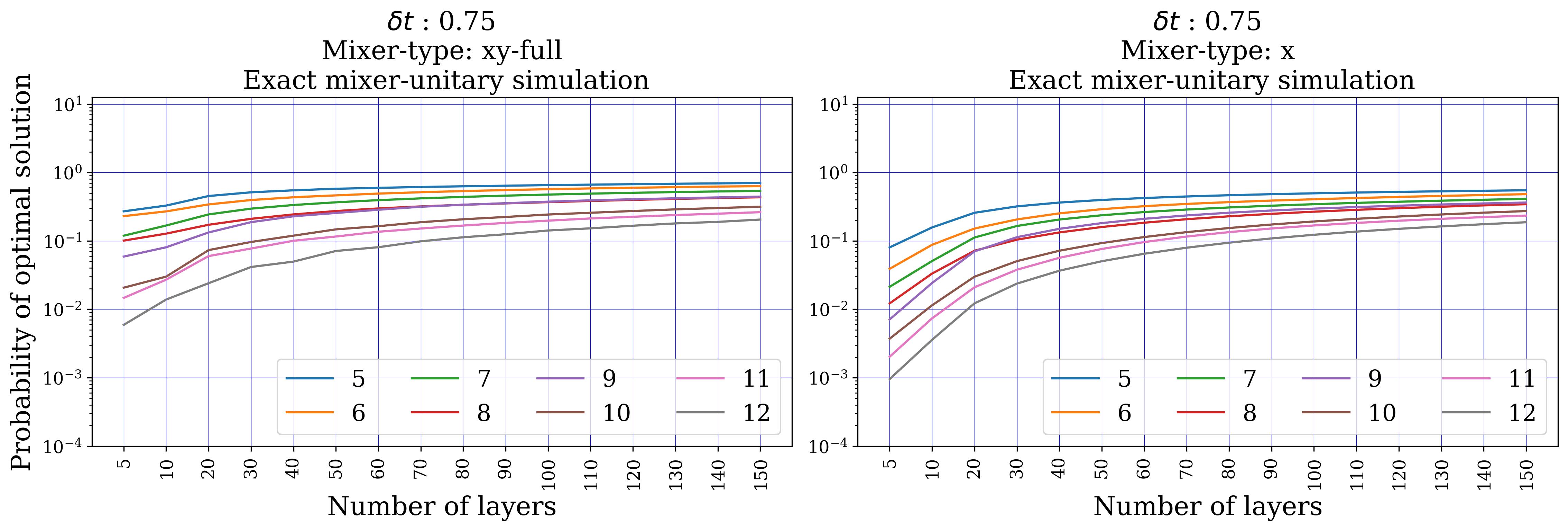
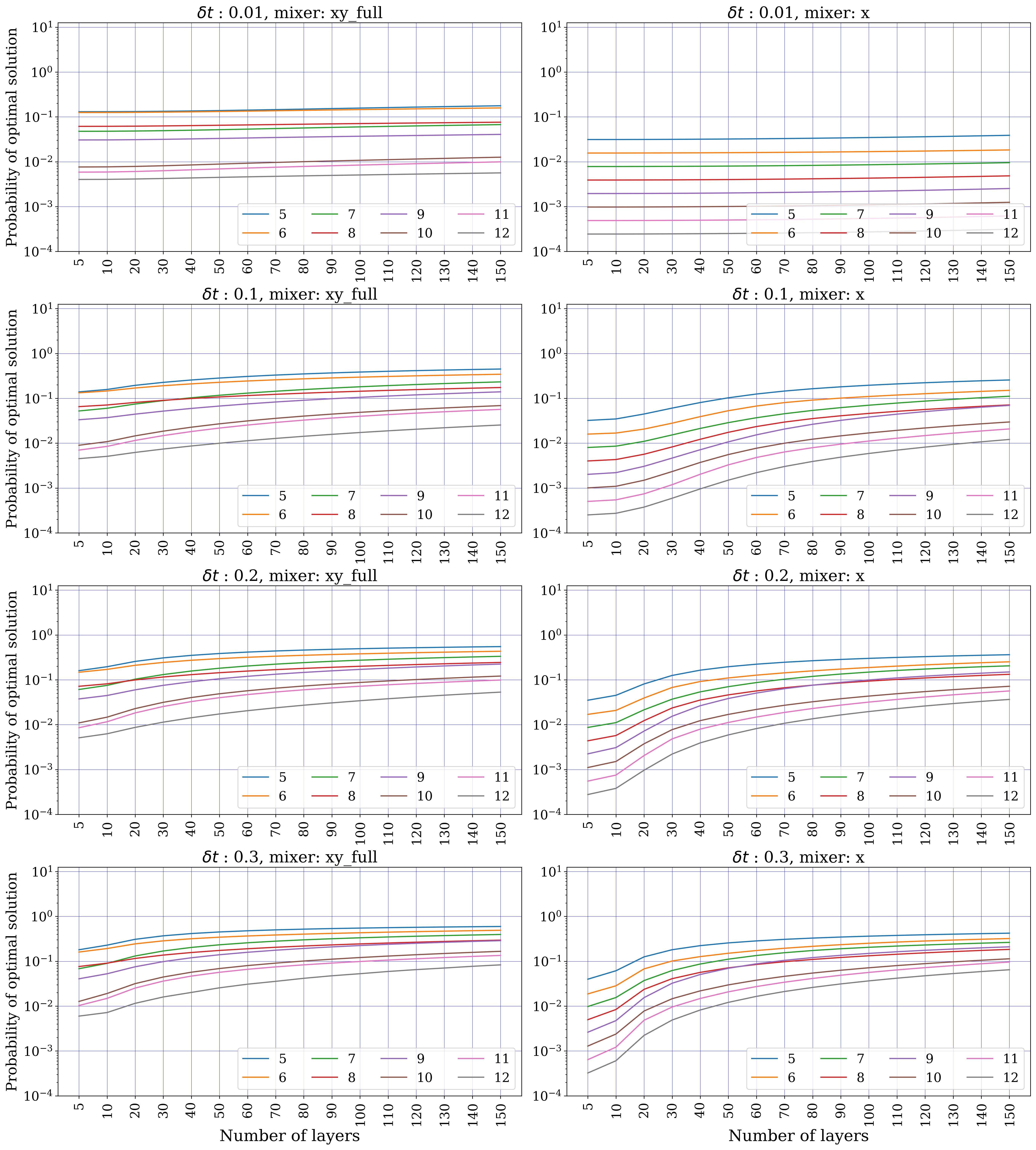
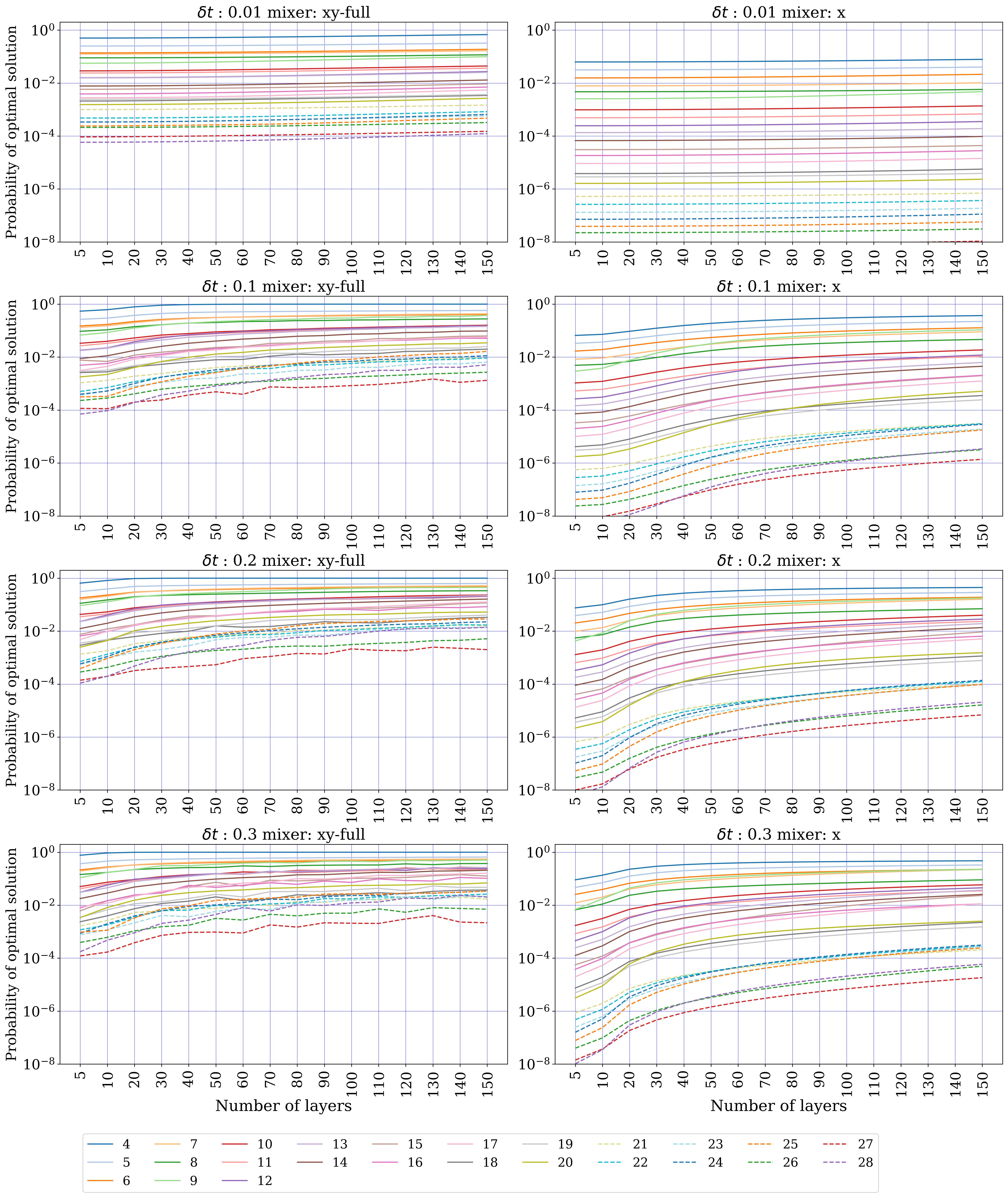
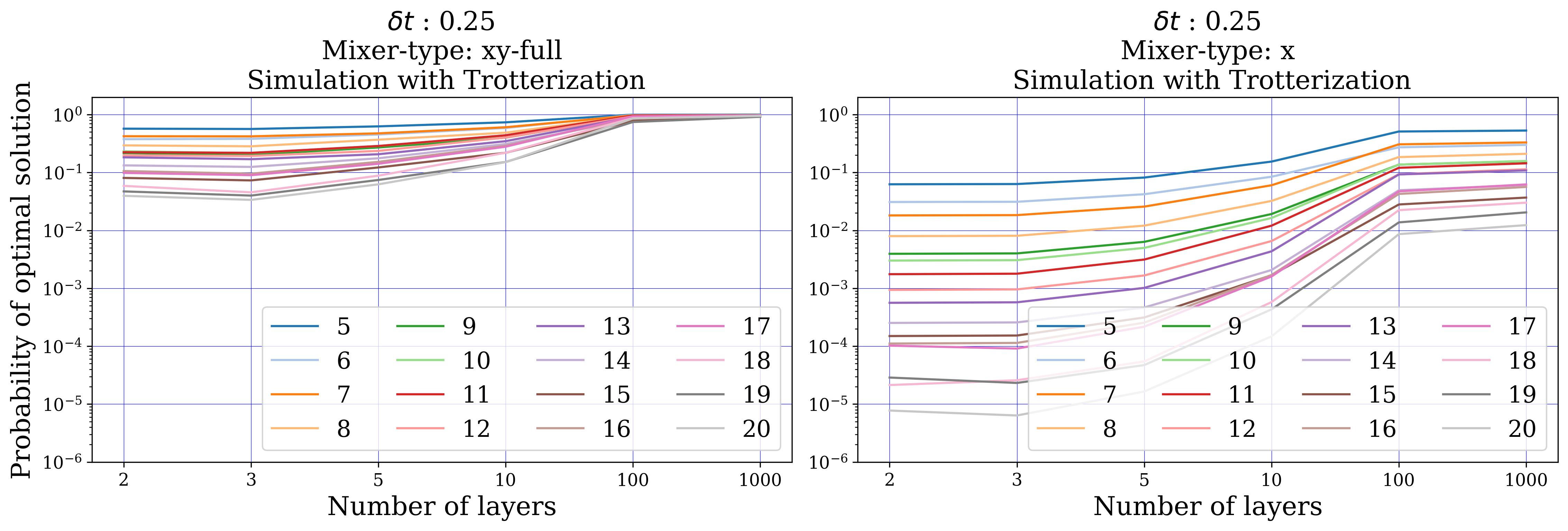
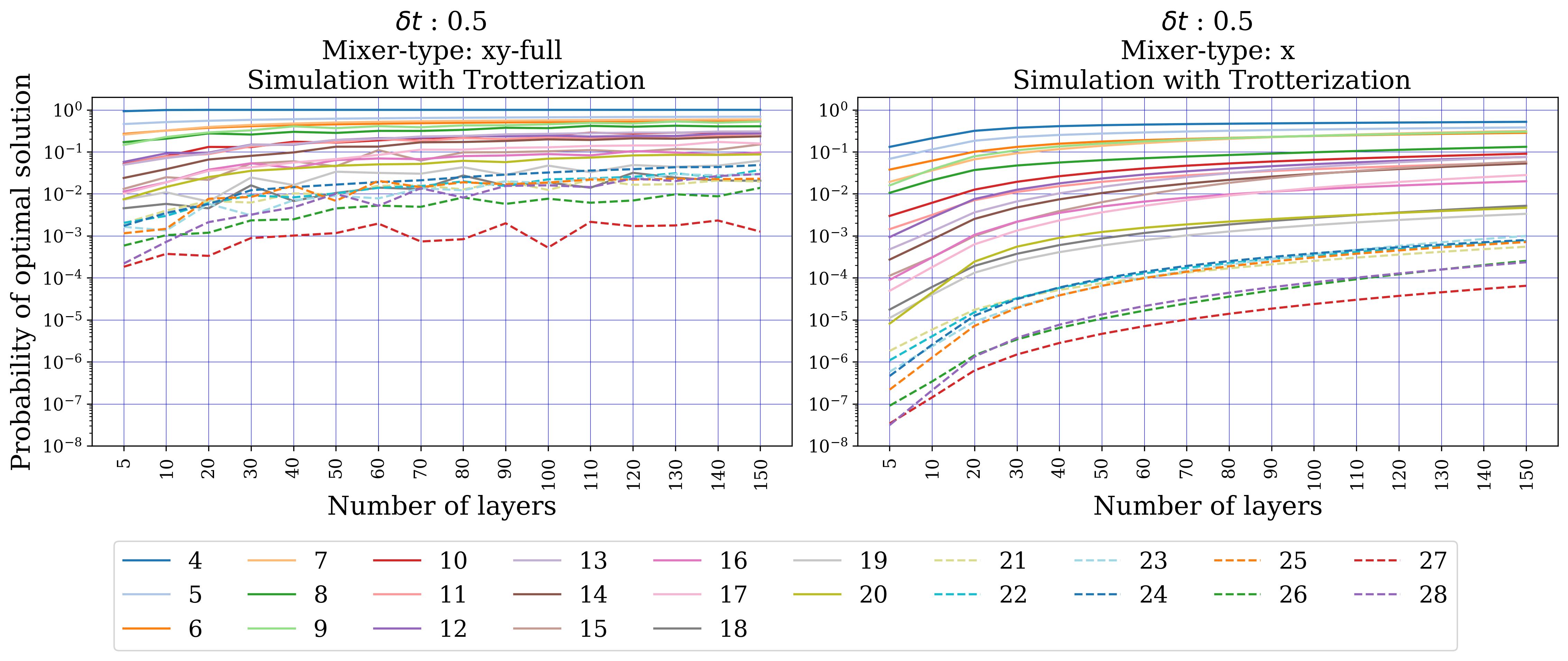
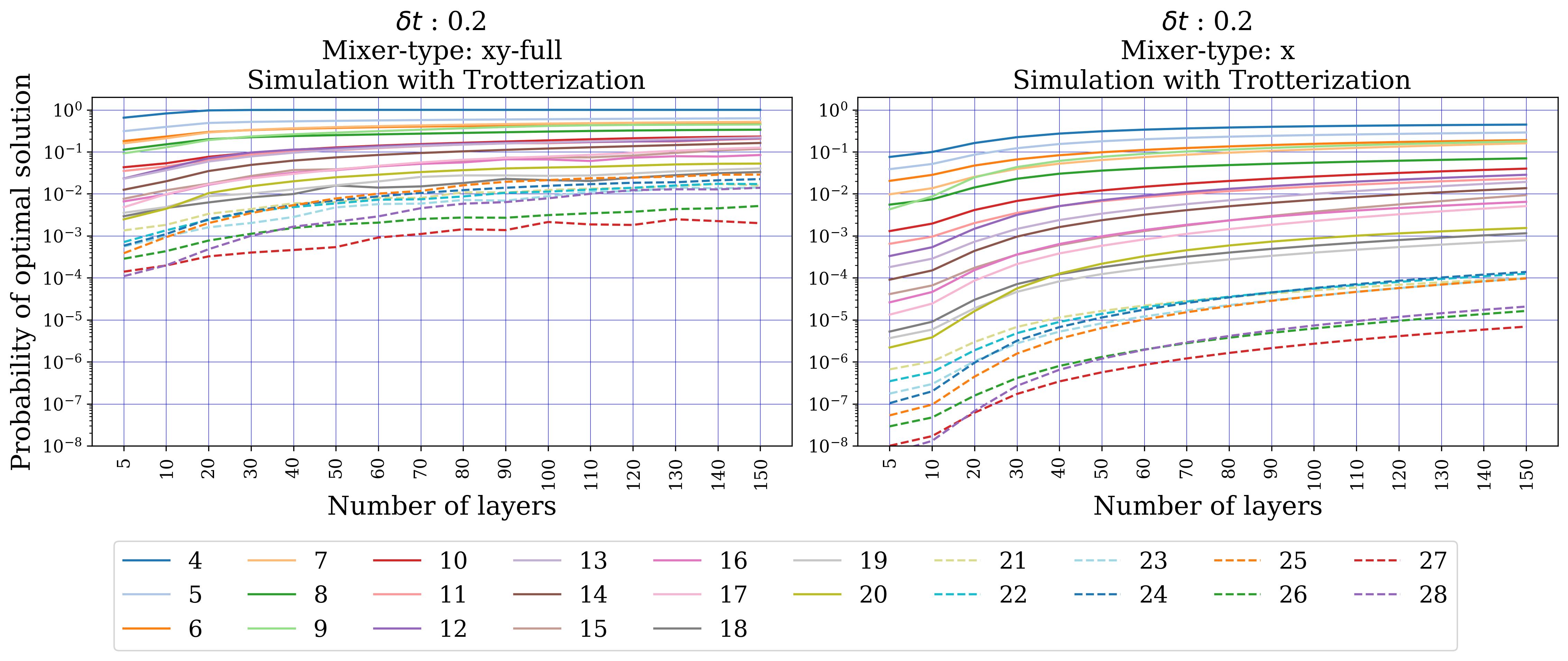
- Numerical verification (Sect. 5): portfolio (single global constraint, 5–12 assets, k ∈ {⌊n/5⌋…⌊2n/3⌋}, 10 instances each) — exact-unitary XY beats X, but Trotterized XY shows erratic behaviour and is overtaken by penalty-X. MCPS (multiple disjoint k-hot, 5–20 qubits) — Trotterized XY beats X by several orders of magnitude across all sizes/depths. MCFP (multiple disjoint 1-hot, 4–28 qubits) — XY consistently wins.
- TSP plaquette mixer (Eq. 5.4): H(u,v)t1,t2 = (Xu,t1Xv,t1 + Yu,t1Yv,t1)(Xu,t2Xv,t2 + Yu,t2Yv,t2) — a four-qubit term implementing the swap (u,t1),(v,t2) ↔ (u,t2),(v,t1), commuting with both row and column 1-hot projectors.
Detailed walkthrough
Section 2 sets up the comparison: penalty-based X-mixers blow up the energy landscape and inflate problem size with slack qubits for inequality constraints; XY-mixers replace this with subspace-confining dynamics by initializing in a Dicke state and ensuring the mixer commutes with the Hamming-weight operator. Lemma 2.1 establishes that |Dnk⟩ is the unique highest-energy eigenstate of the fully connected XY mixer in each k-hot subspace; flipping the sign gives a ground-state initial condition. The ring-XY mixer is then ruled out because Dicke states aren't eigenstates of it (the example with |D42⟩ shows the alternating-pattern states have degree 4 while adjacent-pattern states have degree 2, breaking the equal superposition).
Section 3 (TAE) replaces variational QAOA with a fixed sinusoidal schedule s(t) = sin²((π/2) sin²(πt/2T)) — eliminating the parameter-optimization variance that often confounds QAOA benchmarks. The Suzuki-Trotter-1 expansion preserves the QAOA layered structure but with γl = s(l·δt)·δt and βl = (1−s(l·δt))·δt. Section 3.1.1 then gives the Trotter-error analysis: the worst case is a single global k-hot constraint where every XiXj+YiYj term shares qubits with O(n) other terms, yielding O(n³) non-commuting pairs. With m disjoint blocks of size n/m, [H012, H345] = 0, so cross-block commutators vanish and total error scales as m·O((n/m)³).
Section 4 sets up three problems: portfolio optimization (Markowitz mean-variance, single Σx=k constraint), MCPS (paint-shop, multiple disjoint k(Cq)-hot ensembles), MCFP (multi-commodity flow, multiple disjoint 1-hot constraints plus capacity penalties; proven NP-hard via reduction from PARTITION).
Section 5.1 (portfolio) is the most interesting result. With exact unitary evolution (no Trotter), XY beats X cleanly at small δt and low layer depth — the expected hard-feasibility advantage. But once Trotterized, the XY-mixer probability of measuring the optimum becomes erratic and non-monotonic in depth, while the X-mixer (penalty P=1000) closely tracks its exact-evolution behaviour. The reason: the portfolio's single global k-hot constraint forces the XY-mixer to act on all n qubits, so the Trotter error scales as O(n³). The X-mixer's terms all commute, so it has zero Trotter error in the mixer block.
Section 5.2 (MCPS) shows the opposite regime: the constraint structure decomposes into disjoint car-ensemble k-hot blocks. The XY-mixer factorizes accordingly, cross-block commutators vanish, and Trotter error stays small. Across 5–20 qubits and Trotter depths up to ~20, XY beats X by 1–4 orders of magnitude in the optimum-measurement probability. Section 5.3 (MCFP) is intermediate — multiple disjoint 1-hot blocks per commodity, plus capacity constraints kept as penalties — and XY still consistently wins.
Section 5.4 introduces the TSP plaquette mixer for 2-way-1-hot constraints (the permutation-matrix structure). Naive XY mixers preserve either the row or column constraint but not both, so independent two-qubit mixers are insufficient. The four-qubit plaquette term encodes a "transposition" swap (u,t1),(v,t2) ↔ (u,t2),(v,t1) — exactly the move that connects two permutation matrices. Trotter error is governed by overlapping plaquette quartets rather than global interactions, so it scales mildly. (No numerics for TSP yet — left as future work.)
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary portfolio QAOA): Strongest method overlap. Both papers explicitly attack constraint-preserving mixers for portfolio optimization. Y2 uses quasi-binary encoding with a custom hard-constraint mixer that preserves feasibility without penalty terms; this paper uses XY-mixer initialized in Dicke states. Crucially, this paper's portfolio result argues that for the single-global-constraint structure characteristic of portfolio (and DGMVP), Trotterized XY-mixers lose to X-mixer-with-penalty in practice — directly tensioning Y2's claim of advantage from hard-mixer designs. Y2's quasi-binary encoding may sidestep this critique because its mixer structure differs from the standard XY full mixer, but the comparison deserves a paragraph in any Y2 follow-up.
- Y3 (QAOA DGMVP): Same problem class as the portfolio benchmark in Sect. 5.1. Y3's layerwise + dual-annealing optimization sidesteps variational instability differently than this paper's TAE schedule does. The Trotter-error analysis here is directly applicable to assessing whether DGMVP can benefit from XY-mixers at all.
- Y4 (Grover + ADMM cardinality-constrained BO): Method-adjacent. Y4's Grover-based feasible-space search achieves O(√(C(n,k)/M)) scaling on cardinality constraints — i.e., the same single-global-k-hot structure that this paper shows is the worst case for XY-mixers. Y4's Grover approach may be a better fit for that constraint structure than QAOA-style TAE.
- Y1 (warm-started iterative QAOA): Tangential method. Y1 uses measurement-based warm-starting to escape local minima in QAOA parameter optimization; this paper sidesteps parameter optimization entirely via TAE.
- Y5, Y6: No direct overlap.
Recommended action for Yuan
- Cite in the next Y2/Y3 follow-up. This is the cleanest negative result for naive XY-mixers on portfolio that has appeared in 2026. Y2's quasi-binary encoding may dodge the critique (since the mixer structure is different), but the mechanism — Trotter-error scaling with single-block size — should be addressed head-on.
- Implement the portfolio benchmark for Y2's quasi-binary mixer. Re-run the same 5–12 asset / k=⌊n/5⌋…⌊2n/3⌋ instances under both XY-mixer-with-Dicke and quasi-binary-mixer. This would either show that quasi-binary inherits the same Trotter-error pathology or that the encoding genuinely escapes it — either outcome is a paper.
- Read Sect. 3.1.1 (Trotter-error scaling) carefully — the O(n³) global-constraint vs. block-decomposed scaling argument is general and applies to any mixer with non-commuting terms, not just XY.
- Note the TSP plaquette mixer (Sect. 5.4) as a possible structural template if Y4 is ever extended to permutation-constrained problems.