A Quantum Approach to Stochastic Optimization in Insurance Underwriting
Abstract
The presence of stochastic elements in combinatorial optimization problems makes them particularly challenging, as such problems quickly become intractable for classical computers even at relatively small sizes. In this work, we propose a novel quantum-classical hybrid scheme for solving a class of stochastic optimization problems known as chance-constrained knapsack problems, in which item weights follow probability distributions and constraints may be violated within a specified risk tolerance. Our method employs knapsack-specific QAOA-based circuits to generate samples which, when combined with a self-consistent classical recovery scheme introduced in this work, produce high-quality solutions. Experiments carried out on IBM Heron processors, using circuits with depths up to 177 and comprising 3443 gates acting on as many as 150 qubits, yield solutions that indicate improvement over classical optimization schemes. The proposed quantum-classical scheme paves the way to tackling such problems, with the potential to outperform approaches that rely solely on classical computation.
Executive summary
This is a 150-qubit utility-scale demonstration on IBM's Heron processors of QAOA-style sampling for a constrained binary optimization problem with stochastic constraints — chance-constrained knapsack (CCKP). The pipeline combines a knapsack-specific QAOA ansatz inspired by the Lagrangian-Dual Discretized Adiabatic scheme, CVaR-based variational training, parameter transfer from small surrogate problems, and a novel self-consistent classical recovery loop. At n=150 with 5 constraints, the quantum scheme reaches 93.1% of Gurobi's best while the strongest classical heuristic only manages 55.8%; at n=100 with 20 constraints the gap is 95.7% vs 41.86%. For Yuan, this is the closest May-cycle paper to Y2/Y3/Y4: it does end-to-end portfolio-style binary optimization with constraint-handling QAOA on the same superconducting hardware family used in Y6, with hybrid quantum-classical recovery analogous to Y4's ADMM workflow.
Main contribution
The paper extends QAOA-based combinatorial optimization to stochastic constraints. Theorem 1 reformulates the probabilistic feasibility condition into a deterministic second-order cone constraint under closed-under-convolution distributions. The quantum circuit is a Trotterized LD-DAQC ansatz with both X and XX mixer terms applied along a linear chain (well-matched to IBM heavy-hex). Three innovations: (i) a CVaR upper-tail loss with quadratic feasibility penalty λ; (ii) a Hungarian-algorithm parameter-transfer scheme that aligns constraints by a 4-d feature vector (mean weight, weight density, mean σ, capacity-utilization ratio) so trained parameters from a small instance warm-start a large one; (iii) a self-consistent recovery loop with two-phase per-sample bit-flip repair (feasibility restoration via "relief" maximization, then greedy improvement) and softmax-weighted probability vector updates batched over K mini-batches.
Key theorems and algorithms
- Theorem 1 (deterministic reformulation): for weights drawn from a distribution closed under convolution with strictly increasing CDF Φ, the chance constraint P(Σ w̃ x ≤ C) ≥ 1−ε is equivalent to Σ μ x + Φ⁻¹(1−ε)·√(Σ σ² x) ≤ C (a second-order cone constraint).
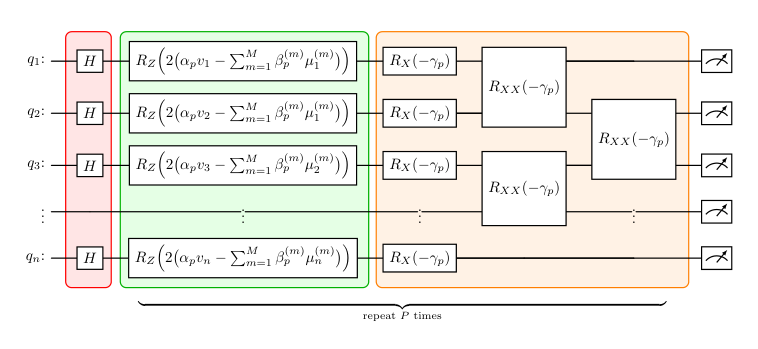
- Algorithm 1 (LD-DAQC ansatz): per-layer Hamiltonians Hproblem = Σ (αp vi − Σm βp(m) μi(m)) Zi and Hmixer = −½ Σ γp Xi − ½ Σ γp XiXi+1, with the X+XX mixer enabling Hamming-weight transitions Δk ∈ {±1, 0, ±2}.
- Two-state toy lemma (Sect. 2.3.1): on the {|10⟩, |01⟩} edge, the optimal saturation of the feasibility-throttled mixer is sin(2γ⋆) sin(δ⋆) = min(1, 2r̂/(μj−μj+1)) — three regimes: full transfer, throttled, and reversed.
- Full-chain probability bound (Eq. 16): P(T) ≈ |ωT|² (1 + 2γ Σ(j,j′)∈boundary sin(2(φj − φj′))) — the XX-chain acts as a bank of parallel reduced-cost comparators.
- Algorithm 2 (parameter transfer): Hungarian algorithm on a constraint-feature distance matrix to permute β-parameters before transfer from nsrc qubits to ntgt qubits.
- Algorithm 3 (self-consistent recovery): Phase 1 maximizes "relief"i/max(vi, δ) + η(1 − pi) to remove items from infeasible samples; Phase 2 greedily adds items in decreasing vi order while feasible. Outer loop updates a selection-probability vector p via softmax-weighted, batched empirical averages.
Detailed walkthrough
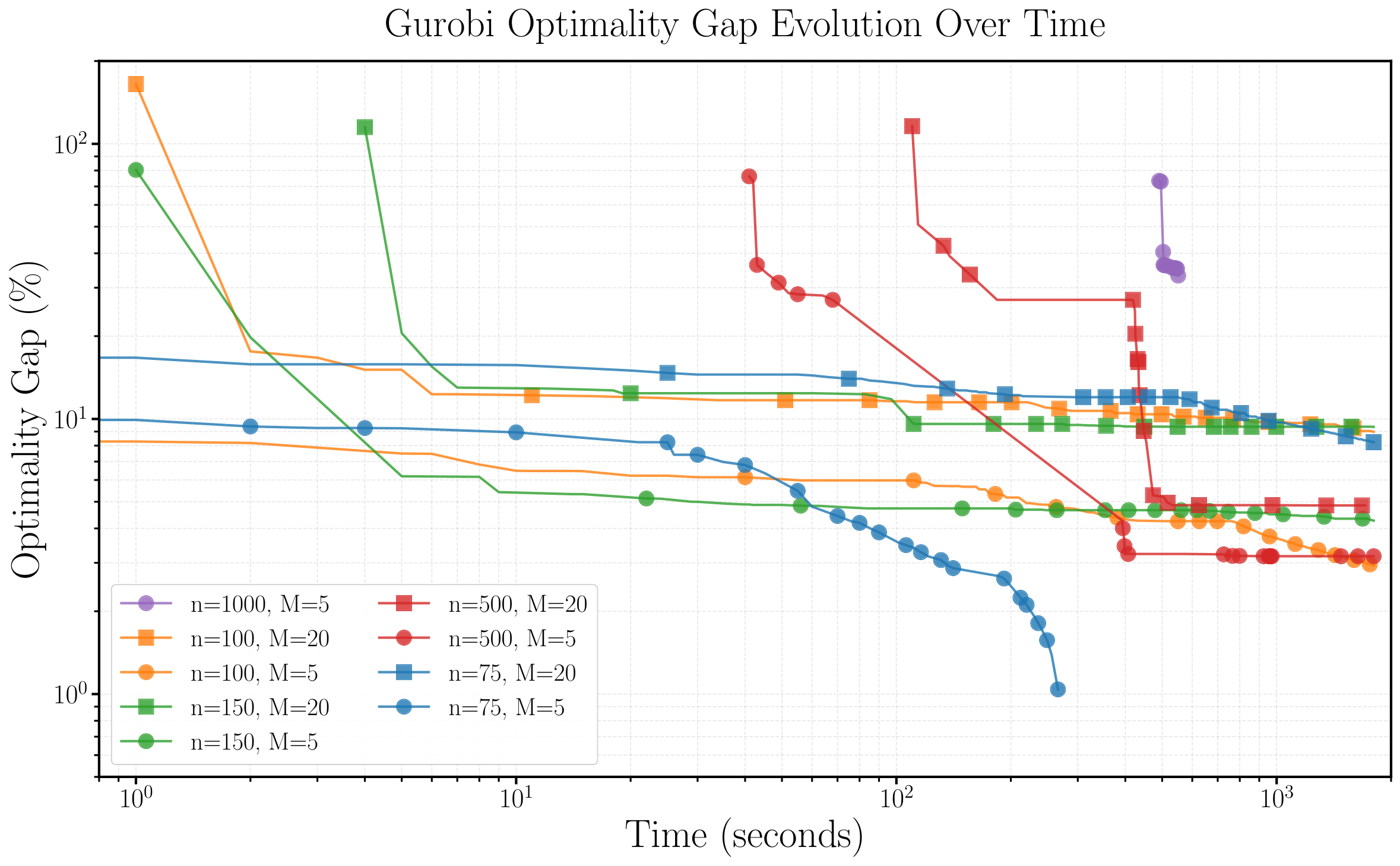
The chance-constrained knapsack maximizes Σ vi xi subject to P(Σ w̃i(m) xi ≤ C(m)) ≥ 1−ε. Theorem 1 turns this into a tractable SOCP for stable distributions (Normal, Cauchy, Lévy); the paper restricts to Normal weights. The classical benchmarking phase (Sect. 2.2) sweeps 3,900 instances over n∈{20…150}, M∈{1…100}, μmax∈{5…100}, σ²∈{0.5…3}, and constraint density / capacity ratios — fixing vmax=50, μmax=5, rC=0.25, rD=0.5 as the hardest configuration. Gurobi proves optimality within 180 s for 100% of n=20 instances but only 36% of n=150 instances; for the largest instances Gurobi runs were extended up to 30 hours to obtain the "best" reference.
The variational circuit (Sect. 2.3) lays Z-rotations weighted by αp vi − Σ βp(m) μi(m) on each qubit, followed by alternating X and XX rotations along a linear chain. The two-state toy analysis (Sect. 2.3.1) derives three operating regimes parameterized by the marginal residual r̂: when capacity is loose, the optimizer can saturate the bound at sin(2γ) sin(δ)=1; when tight, capacity throttles transfer; when violated, the optimizer is forced to reverse amplitude flow toward the lighter item. Section 2.3.2 generalizes this to the full chain and shows that |ωT|² is boosted by a sum over boundary edges of "reduced-cost" terms sin(2(φj−φj′)) — a clean mechanistic explanation of why this ansatz concentrates amplitude on near-feasible high-value subsets.
The variational training uses CVaR with the upper-tail (most adverse outcomes), λ set to Σ vi as a worst-case penalty bound, and COBYLA as the classical optimizer. To address barren plateaus (cited Larocca 2025, McClean 2018), training is restricted to small instances and parameters are warm-transferred to large instances via the Hungarian-aligned scheme. MPS simulation with bond dimension 512 covers up to n=150 before becoming prohibitive.
Hardware experiments use ibm_fez and ibm_pittsburgh (Heron processors) with 2¹⁵ shots, transpile optimization level 3, dynamical decoupling with the XX sequence. The headline circuit at n=150 has p=7 layers, total depth 177, 161 two-qubit depth, 3443 gates.
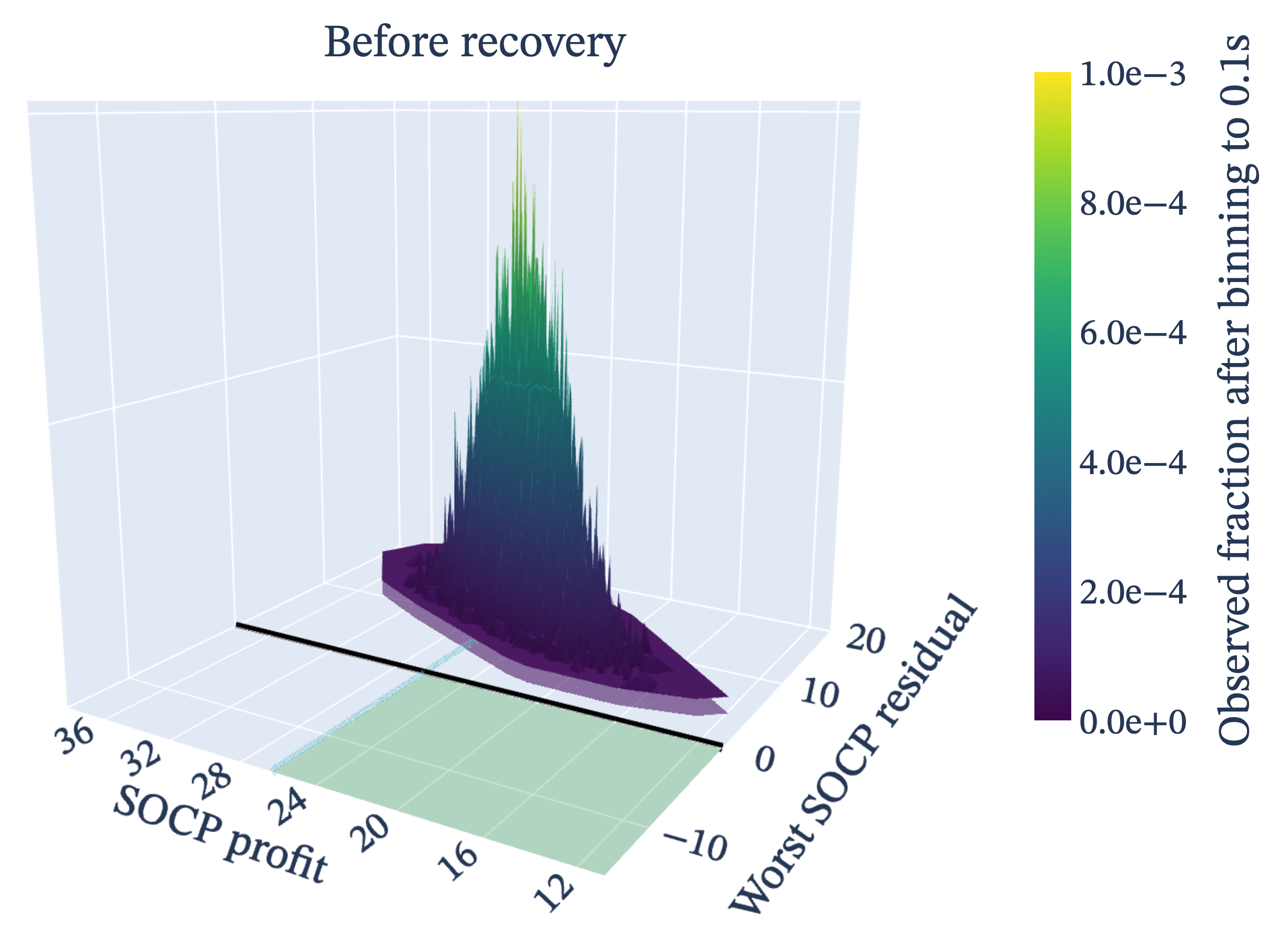
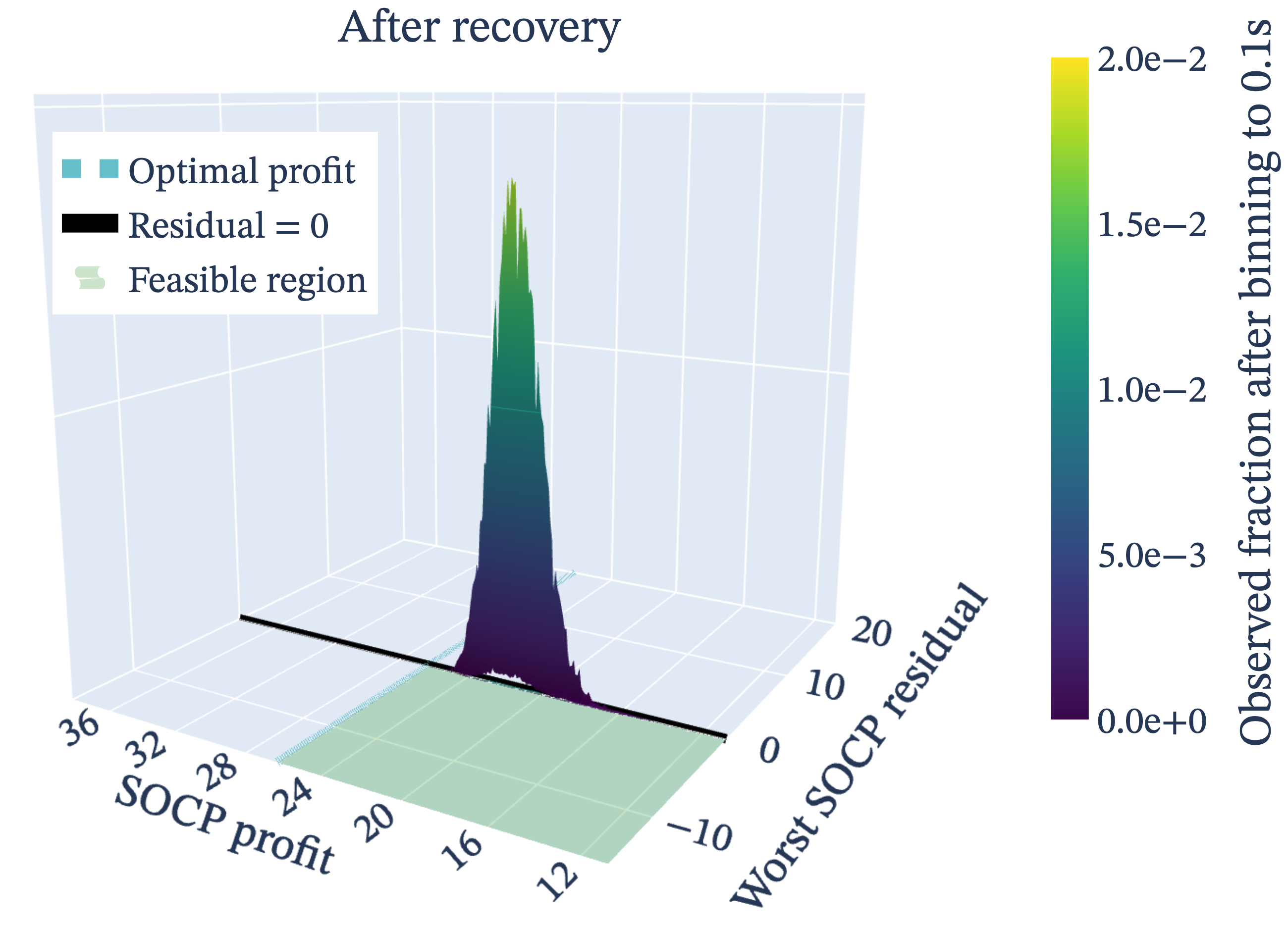
Section 2.4 introduces the recovery loop, drawing inspiration from Robledo-Moreno 2025's quantum-chemistry configuration-recovery scheme. Phase 1 removes items via a "relief" score that combines per-unit-profit relief with a low-frequency-item bonus (η weighted by 1−pi); Phase 2 greedily adds back items in decreasing vi order, checking the non-separable square-root term in the SOCP residual at each candidate. The outer loop updates pnew via softmax-weighted empirical means averaged over K random batches, terminating when ‖pnew−p‖₁/n < εconv.
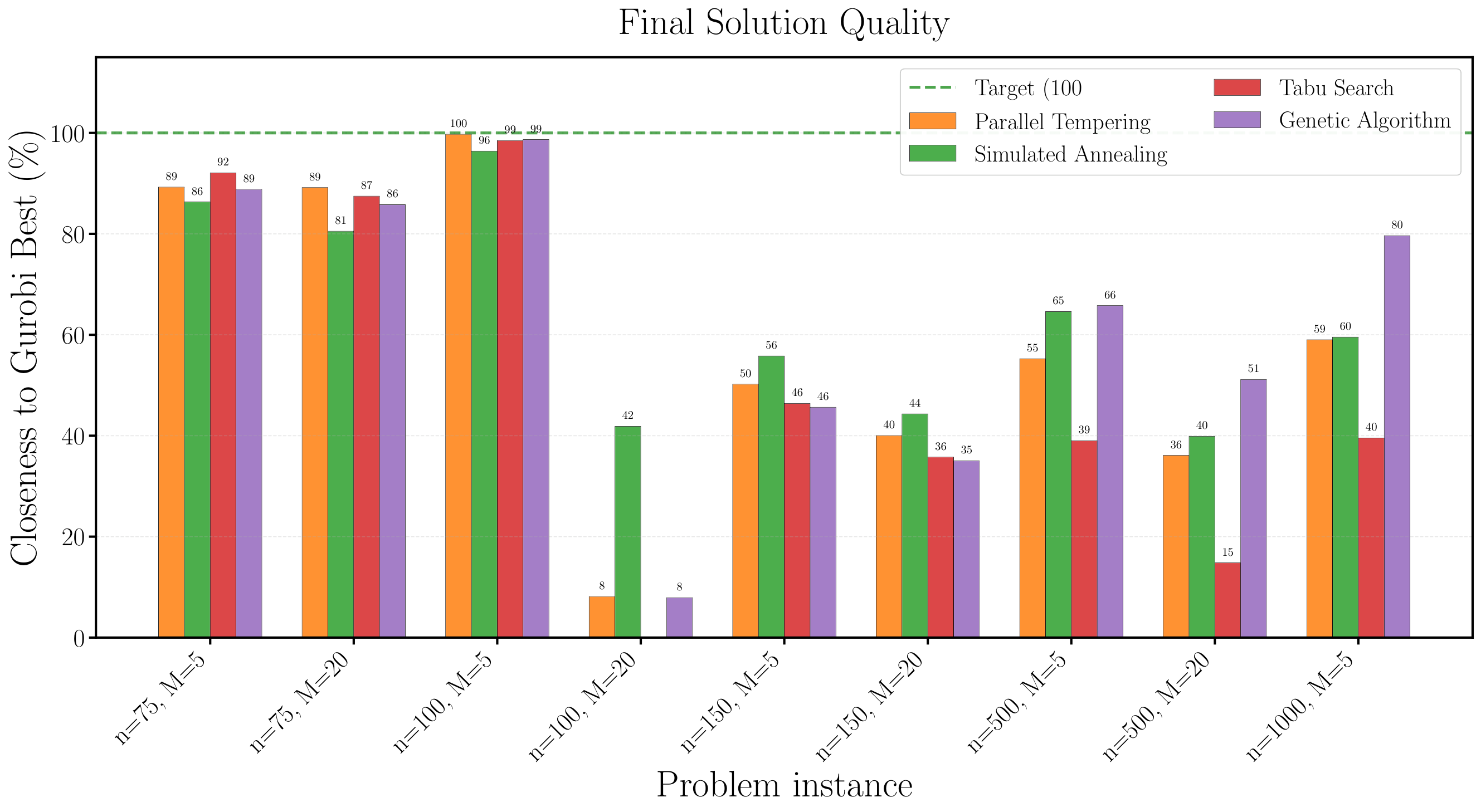
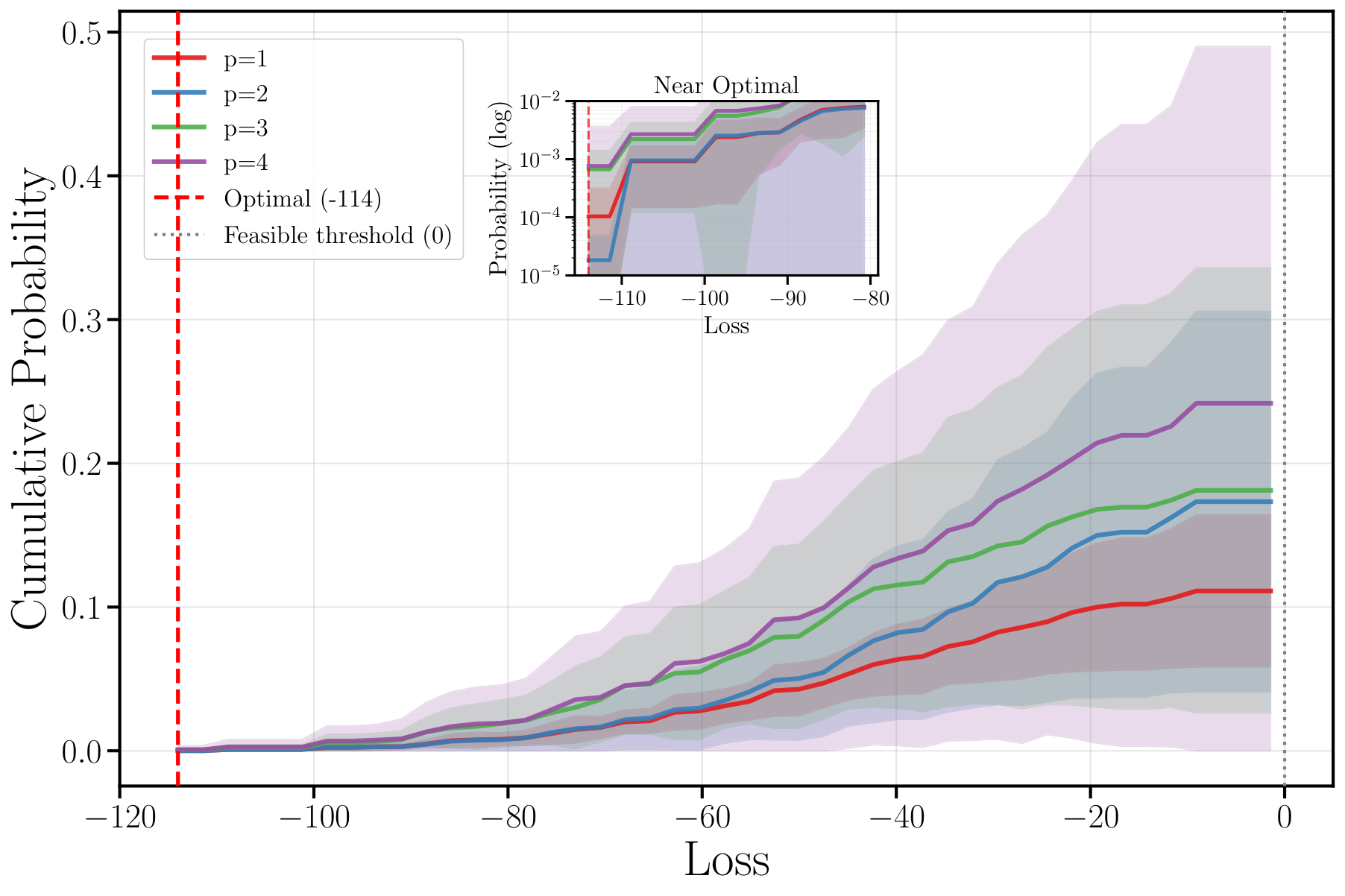
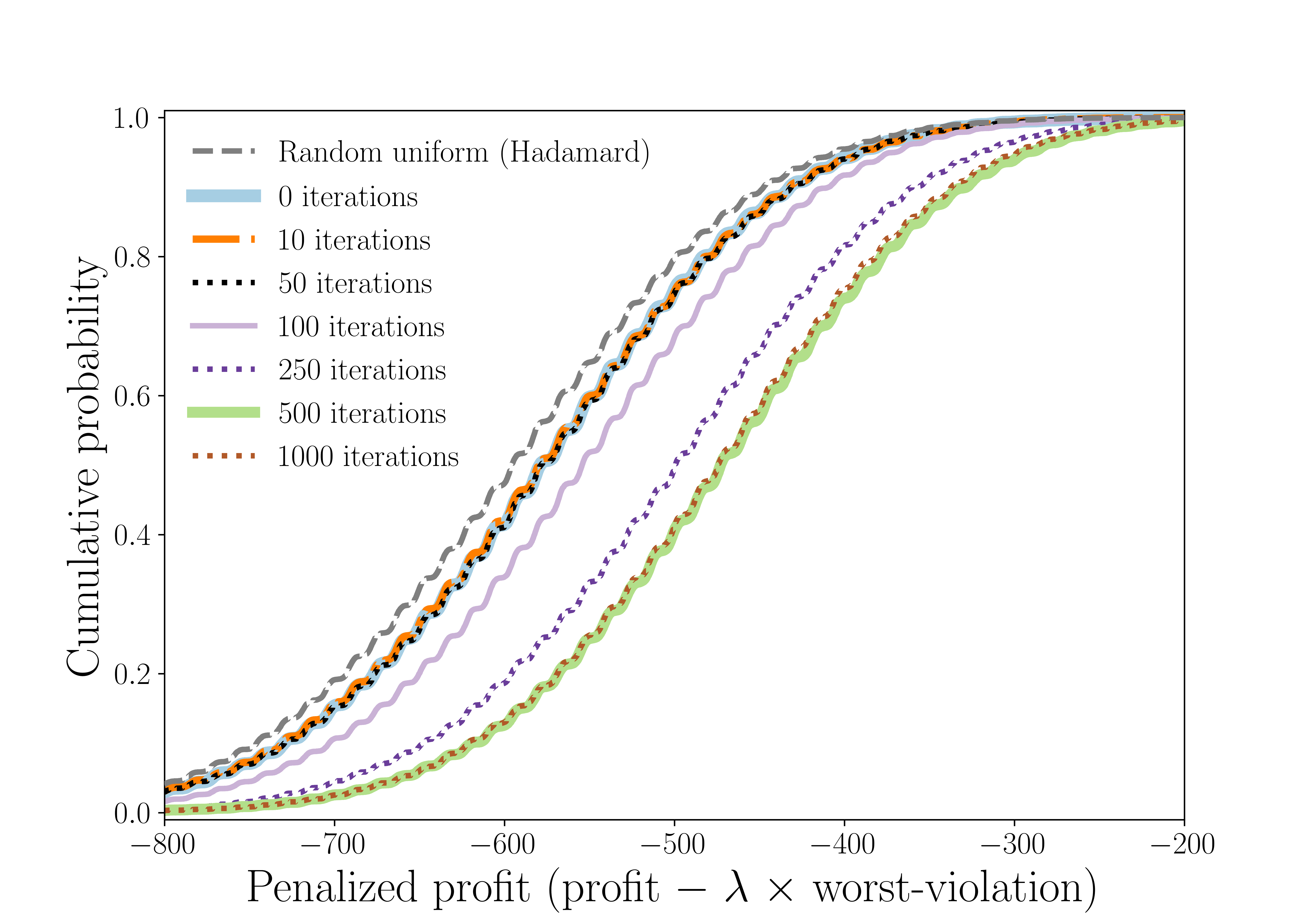
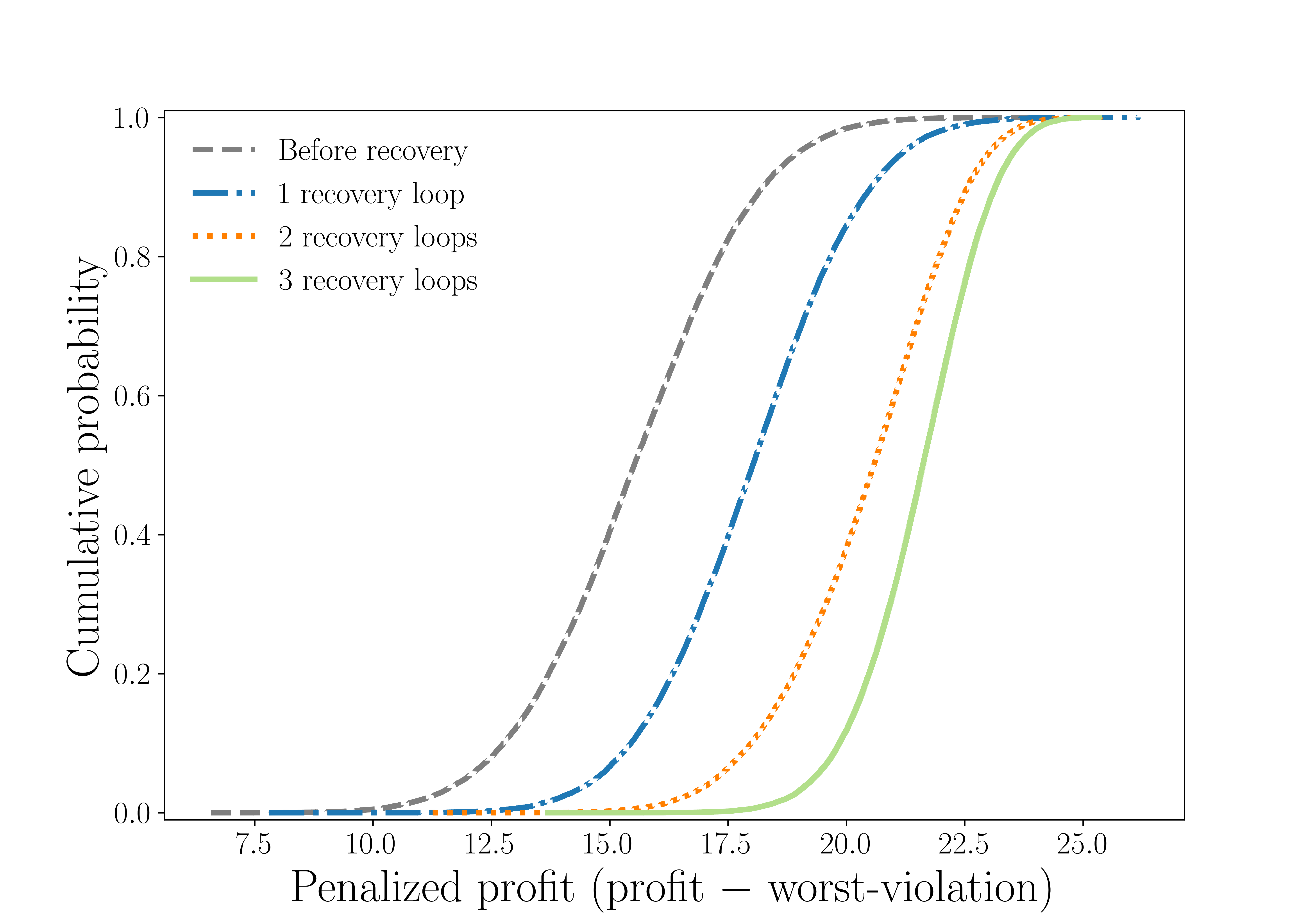
Results (Sect. 3): for n ≤ 50, both quantum and classical recover Gurobi's optimum (κ=100%). At n=75, quantum reaches 97.8% vs 92.09% (best classical heuristic, Tabu Search). The largest divergence is at n=100 with M=20: quantum 95.7%, best classical 41.86% — a 54-point gap. Only at n=100 with M=5 does Parallel Tempering edge out quantum (99.74% vs 96.4%). The CDF analysis (Fig. p_dependence) shows that increasing layer depth p from 1 to 4 raises feasible-sample probability from 11.5%±2.8% to 25.4%±13.3%, with the optimal solution itself appearing at probability ~10⁻³ at p=4. The recovery loop (Fig. cdf_recovered) does most of its work in the first iteration and reaches full SOCP-feasibility after 3 loops.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary QAOA / portfolio): Strong method overlap. Both papers attack constrained binary optimization with QAOA, both use CVaR-QAOA, both apply iterative refinement. The differences: Y2's quasi-binary encoding uses ~2log₂(U−L+1) qubits per variable with hard constraint-preserving mixers (no penalty); Bordelon et al. use a one-hot binary encoding with X+XX mixer plus a quadratic feasibility penalty in the loss — they accept some constraint violation and rely on classical recovery. Yuan's mixer is hard-feasibility, theirs is soft.
- Y3 (QAOA DGMVP portfolio): Both are end-to-end QAOA pipelines for portfolio-style discrete optimization on real hardware. Y3 found that thermal relaxation precludes quantum advantage and that the favourable scaling is in the shot-noise regime; Bordelon et al. claim quantitative outperformance vs classical heuristics at n≥75 on IBM Heron, but the comparison is against heuristic solvers rather than provably optimal Gurobi for large n. The CCKP setting is novel relative to Y3.
- Y4 (Grover + ADMM cardinality-constrained BO): Method-level parallel — both papers use a hybrid quantum-classical decomposition where the quantum subroutine generates samples and a classical post-processing step refines them. Y4 has provable ε-approximation guarantees via ADMM; Bordelon et al.'s recovery loop is heuristic (greedy bit-flip with self-consistent probability updates). The cardinality constraint in Y4 is exact; here CCKP is a probabilistic generalization of the multi-knapsack.
- Y6 (PBR test on Heron2): Same hardware family — both papers run on IBM Heron processors. Their utility-scale circuits at n=150, depth 177, 3443 gates push hardware in the same regime Y6 stresses with PBR violation tests across 156 qubits.
- Y1 (warm-started iterative QAOA): Adjacent. Both use iterative warm-starting; Y1's measurement-based warm-start improves 3-regular MaxCut while Bordelon et al. transfer optimized parameters from small instances via Hungarian-matched constraint features. Different problem class.
- Y5 (GW SDP via Gibbs / Pauli sparsity): Tangential.
Recommended action for Yuan
- Cite in next QAOA-portfolio draft. This is currently the strongest 2026 utility-scale benchmark for constrained QAOA; it directly invites comparison with Y2's hard-mixer / quasi-binary approach. Worth a bench paragraph in any Y2/Y3 follow-up.
- Read Sect. 2.3.1–2.3.2 carefully. The two-state and full-chain analyses give a clean mechanistic picture of how an X+XX mixer redistributes amplitude under feasibility constraints; that machinery may transfer to Y2's quasi-binary mixer analysis where similar Hamming-weight redistribution arguments apply.
- Compare quantitatively against Y3's DGMVP scaling. Bordelon et al. claim 95.7% closeness at n=100 with M=20 — running the same instance set through Y3's QAOA-DGMVP pipeline (or Y2's quasi-binary CVaR-QAOA) would provide a direct head-to-head and could be a quick-turnaround benchmark study.
- Possibly contact the IBM Quantum co-authors (Kumar, Mijares Vilarino, Maldonado Romo). If the source code is released as promised, integrating Yuan's hard-mixer baseline into their CCKP pipeline would be a natural collaboration.