A Resource-Efficient Variational Quantum Framework for the Traveling Salesman Problem
Abstract
The Traveling Salesman Problem (TSP) is a prototypical combinatorial optimization problem, but its quantum implementation is limited by the O(n²)-qubit overhead of standard one-hot encodings. Here, we propose a resource-efficient variational quantum framework based on compact binary-register encoding, a permutation-preserving problem-inspired ansatz, and a complementary divide-and-conquer execution strategy. The compact encoding reduces the data-qubit requirement to O(n log n), while the divide-and-conquer formulation lowers the number of qubits required in each local hardware execution to the size of the largest subsystem. Numerical simulations on TSP instances with 4, 5, and 6 cities achieve best average success rates of 100%, 100%, and 95.5%, respectively. A local two-qubit implementation of the divide-and-conquer approximation is further evaluated for a 5-city TSP instance on SpinQ Gemini Pro and SpinQ Triangulum II NMR quantum computers.
Executive summary
This paper attacks the same resource-bottleneck Yuan tackled with quasi-binary encoding in Y2: standard one-hot QAOA encodings of permutation-style problems waste qubits. Lin et al. propose a near-linear M⌈log₂ M⌉ + 1-qubit binary-register encoding for TSP after cyclic-symmetry reduction, paired with a permutation-preserving ansatz built from ancilla-controlled register-SWAPs that cannot leave the feasible permutation subspace — eliminating penalty terms entirely, exactly the design goal of Y2's hard-constraint mixer. They additionally introduce a divide-and-conquer execution that exploits the diagonal-in-Z structure of the Hamiltonian to factorize energy estimation across subsystems, demonstrating it on a 2-qubit NMR processor (SpinQ Gemini Pro / Triangulum II) for a 5-city instance. For Yuan, this is a direct methodological echo of Y2 — different problem (TSP vs portfolio), same combinatorial-encoding philosophy.
Main contribution
Three combined ingredients: (i) a binary-register Hamiltonian for TSP that reduces the data-qubit count from O(n²) to O(n log n) after cyclic-symmetry reduction (M = n−1, k = ⌈log₂ M⌉ qubits per register); (ii) a permutation-preserving ansatz layer built as an ordered product of parameterized controlled register-SWAPs Uswap(i,i+1)(θ) = Ry(aux)(2θ)·Si,i+1(aux), where adjacent transpositions generate the symmetric group so any feasible permutation is reachable; (iii) a divide-and-conquer reformulation that factorizes the global energy E(θ) = Σt ct ∏i ⟨ψi(θi)|Õt,i|ψi(θi)⟩ into per-subsystem expectation values — enabling execution on 2-qubit hardware at the cost of dropping inter-subsystem entanglement. Resource scaling drops from M² qubits / ½M(M−1) parameters in the prior one-hot feasible-subspace ansatz of Matsuo et al. to M⌈log₂ M⌉+1 qubits / (M−1)L parameters here.
Key algorithmic ingredients
- Binary-register Hamiltonian (Sec. 2.2, Eq. (binary_hamiltonian)): H = Hdist + λHrep + μHinv, with projectors Pi(a) = ∏b(1+(−1)abZi,b)/2 onto each binary city code.
- Parameterized controlled register-SWAP block (Eq. parameterized_register_swap): single-parameter primitive coherently controlled by an ancilla Ry rotation; reused across the circuit.
- Permutation-preserving full ansatz (Eq. permutation_ansatz_state): |Ψ(θ)⟩ = ∏ℓ Ulayer(θ(ℓ))(|0⟩aux⊗|π0⟩) — feasibility preserved by construction, so penalty terms can be dropped from the objective: E(θ) = ⟨Ψ(θ)|(Iaux⊗Hdist)|Ψ(θ)⟩.
- Divide-and-conquer factorization (Sec. 2.4): exploits H = Σtct⊗iÕt,i with Õt,i∈{I,Z}⊗q being mutually-commuting Z-strings; energy is reconstructed classically from per-subsystem measurements.
- Hardware-efficient 2-qubit local block (Fig. hardware_ansatz): Ry(θ1)–Ry(θ2) on q0,q1, controlled-Z, then Ry(θ3)–Ry(θ4) — used for each 2-qubit subsystem in the divide-and-conquer execution.
- Optimization protocol: Adam in simulation; SPSA on hardware (120 iterations, 1024 shots) with three measurement-error-mitigation modes compared (raw, IBU, matrix inversion).
Detailed walkthrough
Encoding (Sec. 2.1–2.2). The standard one-hot QUBO for TSP with n cities introduces an n² binary variable xv,j=1 iff city v is visited at position j. The authors first apply cyclic-symmetry reduction by fixing one starting city — leaving M = n−1 ordered positions — and then encode each position with k = ⌈log₂ M⌉ qubits as a binary integer label. The Hamiltonian comprises three parts: a distance term Hdist assembled from quadratic projector products Pi(a)Pi+1(b) weighted by D̃ab; a repetition penalty Hrep over (i,j,a) triples that flags visiting city a in two distinct positions; and an invalid-code penalty Hinv over codes a∈{M,…,2k−1} that fall outside the valid label range. The total qubit count after reduction is M⌈log₂ M⌉, e.g. n=6 ⇒ M=5, k=3 ⇒ 15 data qubits + 1 ancilla = 16. This is the same scaling philosophy as Yuan's Y2 quasi-binary encoding (~2log₂(U−L+1) qubits per integer variable), but specialized to permutation labels.
Ansatz (Sec. 2.3). The really nice idea is making the mixer feasibility-preserving by construction. Each layer applies CSWAP-based register-swap blocks between neighbouring registers (i, i+1), parameterized through a single auxiliary Ry(2θ). Because adjacent transpositions generate SM, repeated application can reach any feasible permutation; because each block either swaps two whole binary labels or leaves them untouched, the data registers never wander into repeated-city or invalid-code configurations. The Hrep and Hinv terms vanish in expectation and can be dropped from the objective, leaving only Hdist. This is the clean analog of Y2's hard mixer that obviated the need for cardinality-penalty Lagrangians in portfolio QAOA — the same gains (no penalty-strength tuning, smaller parameter landscape) translate directly.
Divide-and-conquer (Sec. 2.4). When even the compact encoding overshoots the device (e.g. their NMR processors hold 2 qubits), they fall back to a separable product-state ansatz |ψ(θ)⟩ = ⊗i|ψi(θi)⟩. Because the Hamiltonian is diagonal in Z (so a sum of mutually-commuting Z-strings), each Hamiltonian-term expectation factorizes: ⟨Ht⟩ = ∏i⟨ψi|Õt,i|ψi⟩. The global energy E(θ) is then assembled classically from per-subsystem measurements, allowing arbitrarily small physical hardware at the cost of dropping inter-subsystem entanglement — and hence requiring the penalty terms back, since global feasibility is no longer enforced by state preparation. The 5-city symmetry-reduced problem is partitioned into four 2-qubit subsystems for the NMR run.
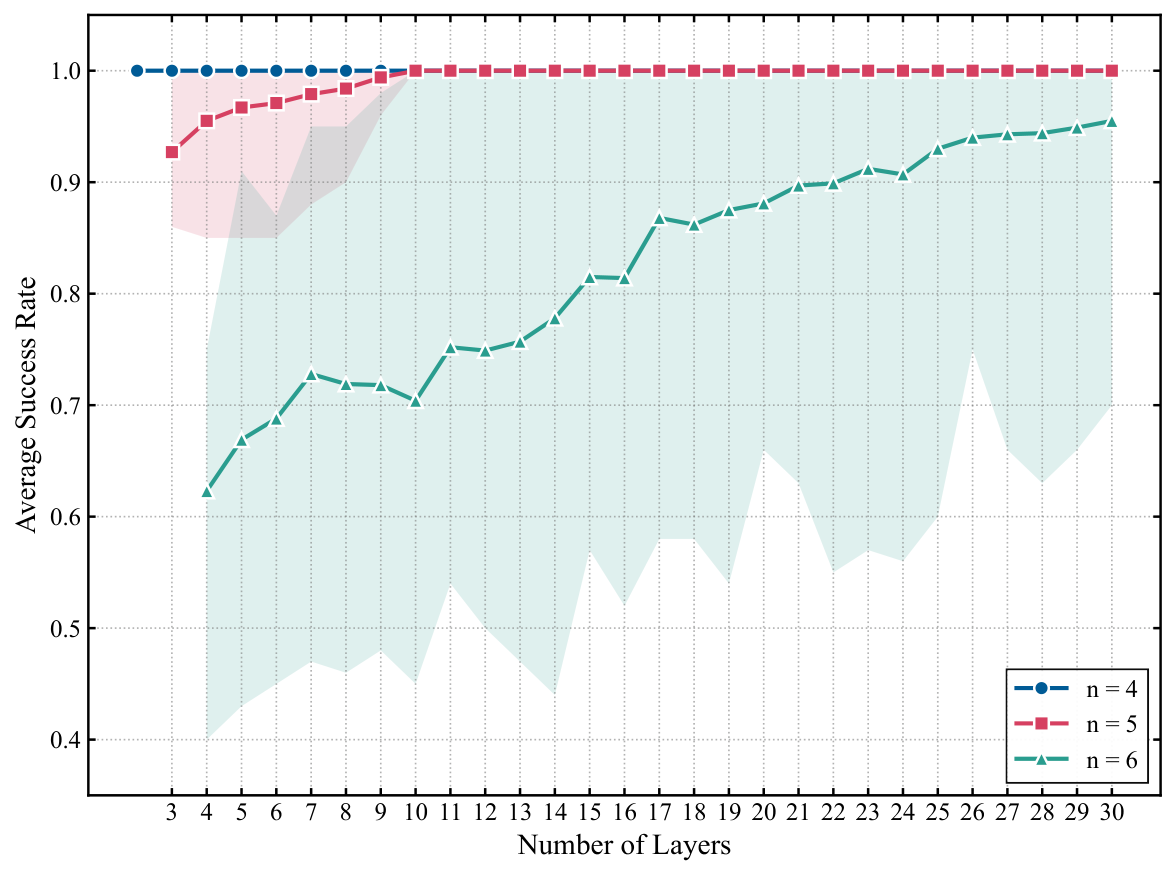
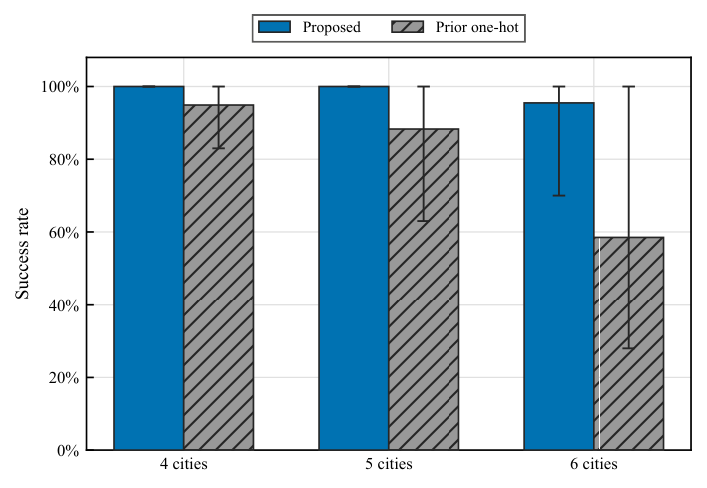
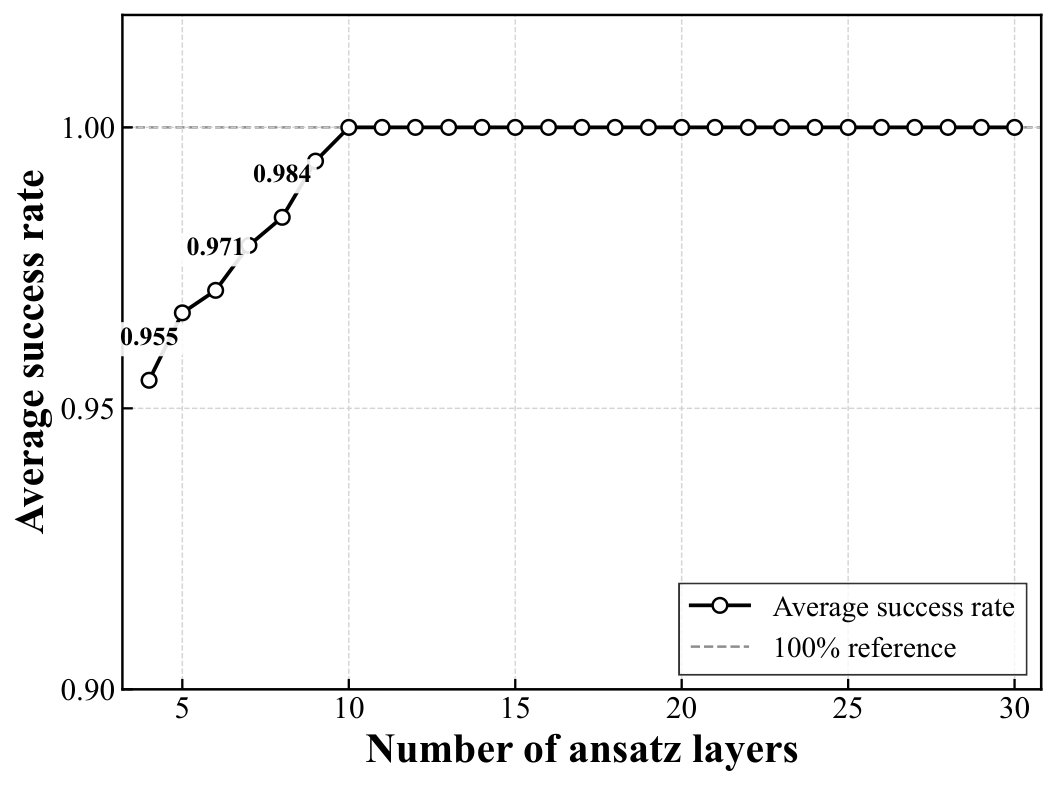
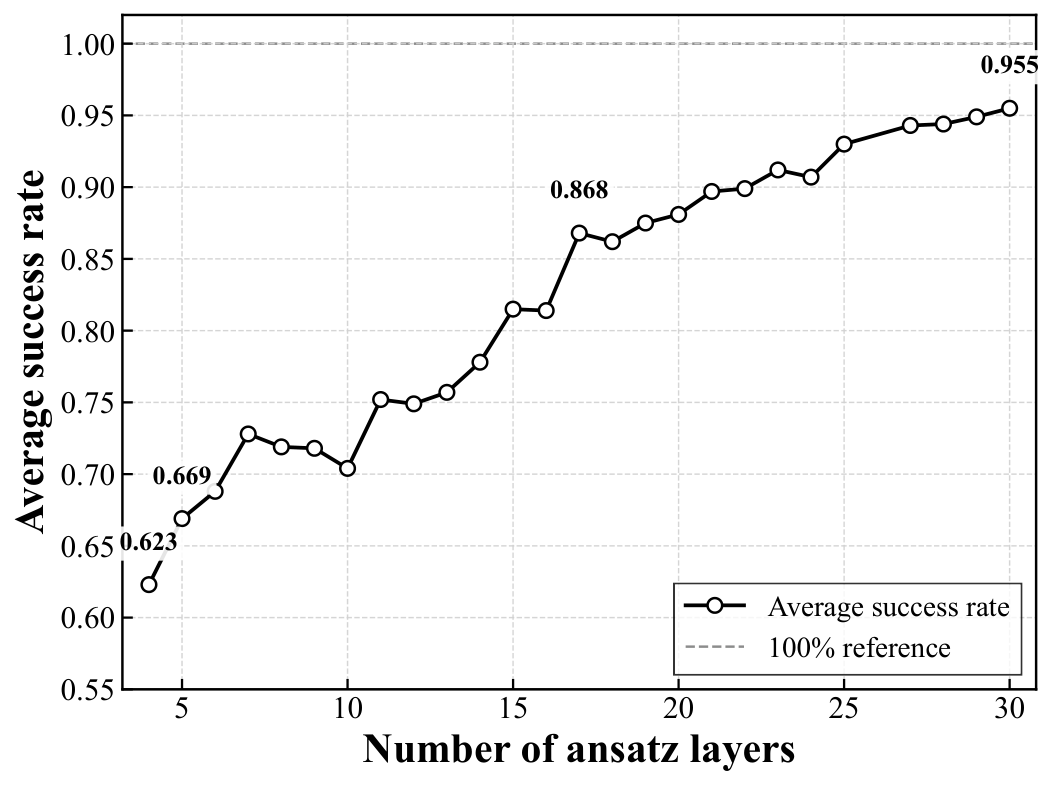
Simulation results (Sec. 3.2–3.3). Best-average success rates: 100% (n=4, all depths), 100% (n=5, L≥10, up from 92.7% at L=n−1=4), and 95.5% (n=6, L=30, up from 62.3%). The depth-vs-success curves (Fig. fig:success_rate_vs_layers) show a clear depth–performance trade-off — the analog of the layer-count sweep Yuan ran in Y3 for QAOA on DGMVP. Comparison against the prior one-hot feasible-subspace ansatz of Matsuo et al. shows a 37 percentage-point gap at n=6 (95.5% vs 58.5% best-average), with the qubit count reduced from M² = 25 to M⌈log₂ M⌉+1 = 16. Resource Table 1 quantifies the asymptotic differences in qubits, parameters, one- and two-qubit gates, and CSWAP counts.
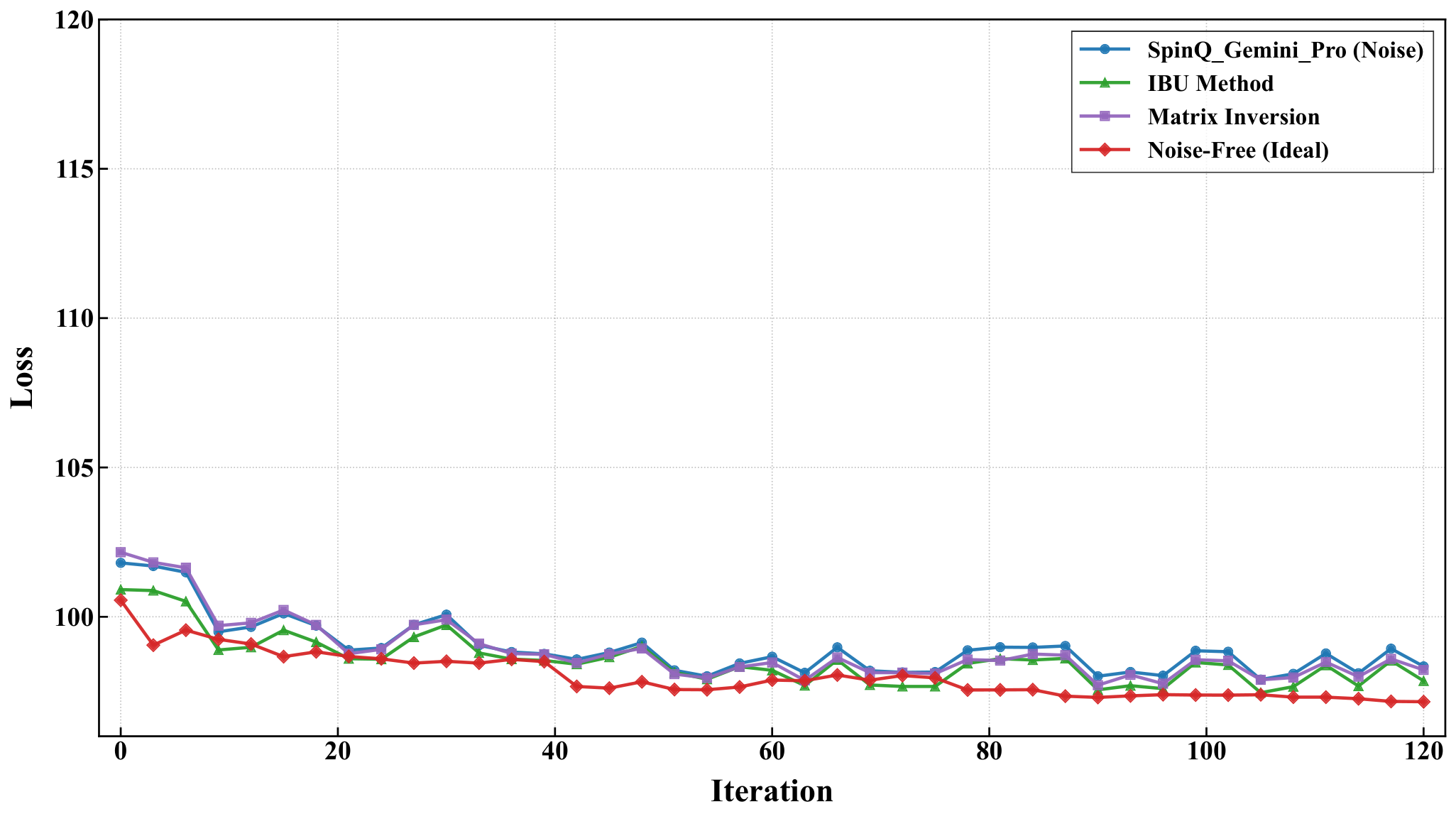
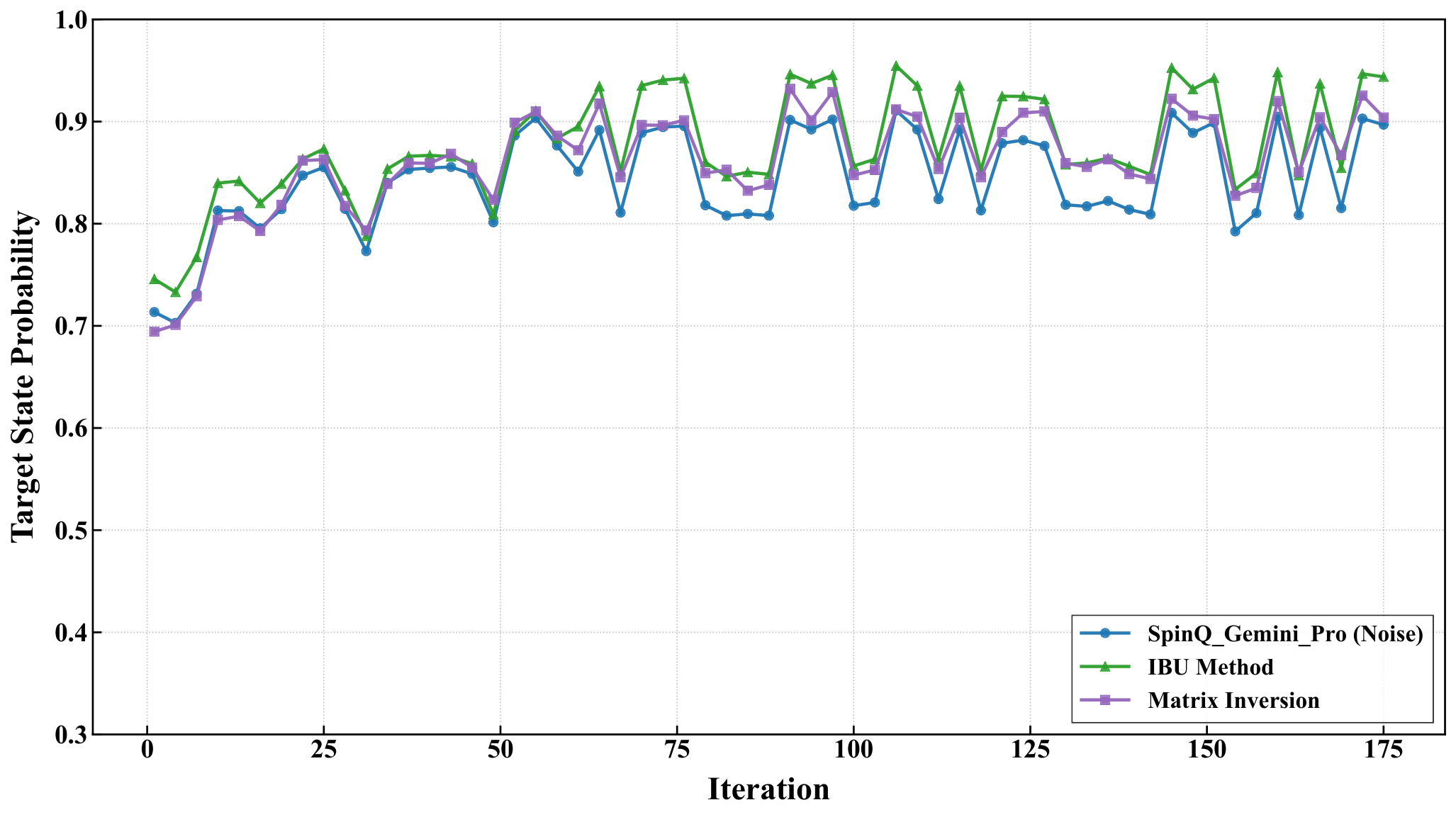
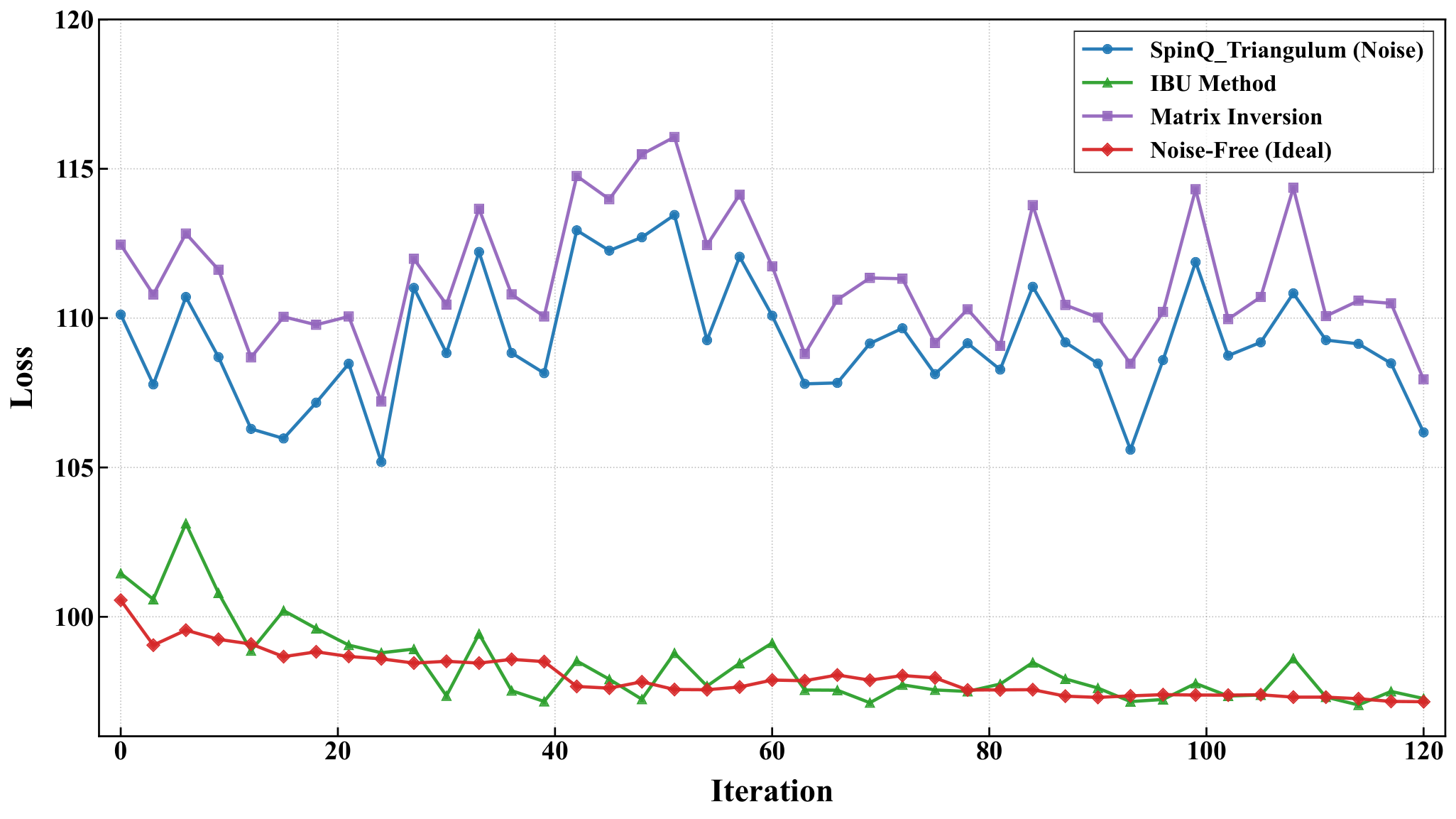
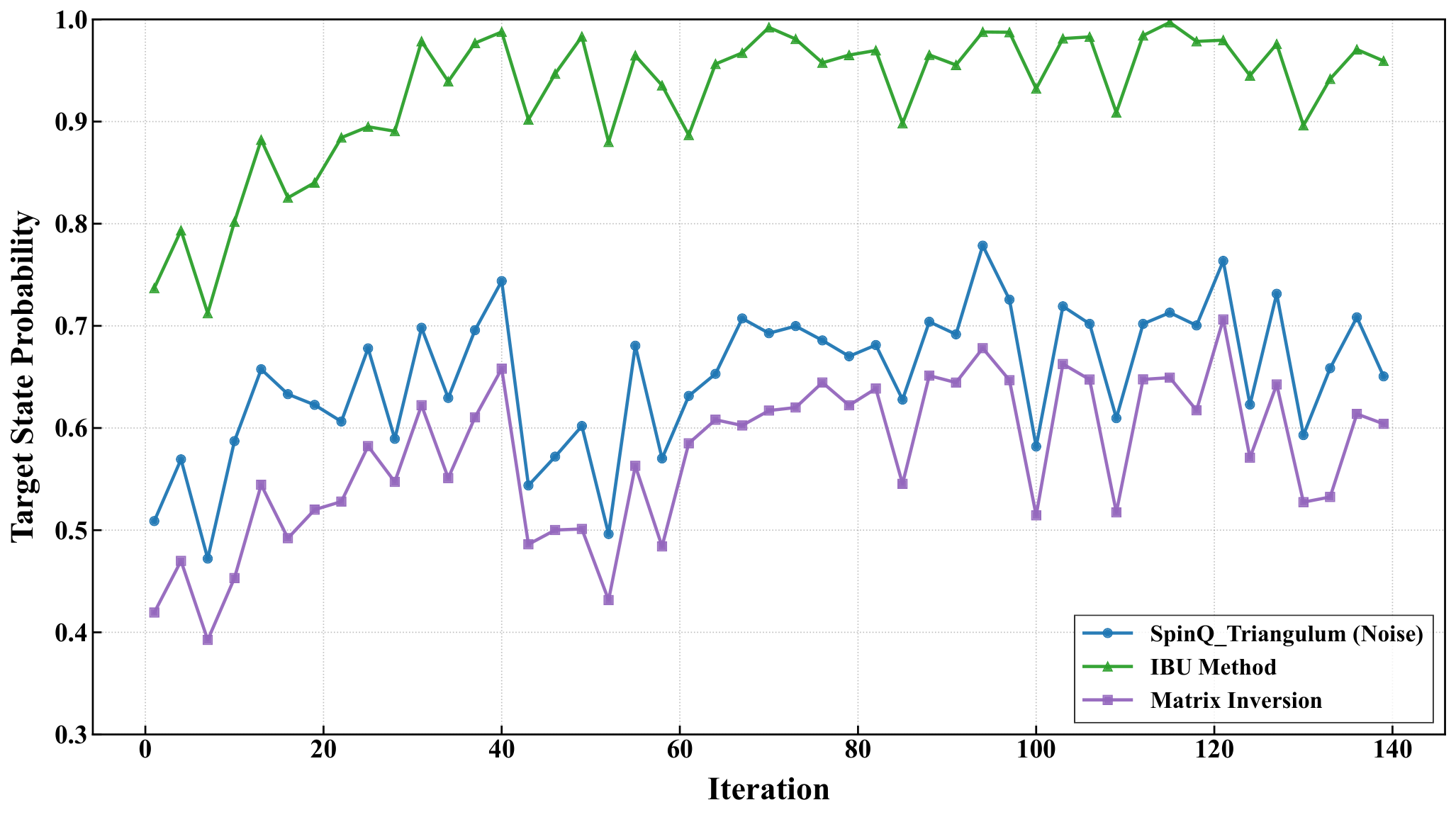
Hardware experiments (Sec. 3.4). The 5-city instance partitioned into four 2-qubit blocks ran on SpinQ Gemini Pro and Triangulum II NMR processors using SPSA. Comparing raw, IBU-mitigated, matrix-inversion-mitigated, and noise-free trajectories: on Gemini Pro the raw target-state probability rises from 0.714 to 0.829 over 120 iterations; IBU pushes the final to 0.868. On the noisier Triangulum II the raw final probability is only 0.651, but IBU recovers 0.959 (vs 0.604 from matrix inversion). The authors attribute the IBU stability advantage to its iterative preservation of probability constraints, contrasted with matrix inversion's amplification of statistical and calibration noise — a measurement-mitigation comparison that complements the shot-noise vs thermal-noise discussion in Y3.
Caveats acknowledged (Sec. 4). All instances are small (n≤6); the authors flag barren-plateau concerns for the permutation-preserving ansatz at scale and note that divide-and-conquer drops inter-subsystem entanglement, potentially limiting accuracy on strongly-correlated landscapes. The classical-quantum hybrid feel is reminiscent of Y4's ADMM hybrid, though the technical mechanism is different.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary portfolio QAOA) — strongest overlap. Both papers replace one-hot encodings with compact binary registers (~log₂) and rely on a constraint-preserving mixer to drop penalty Lagrangians. Y2's mixer preserves cardinality on portfolio integer variables; this paper's mixer preserves permutation feasibility on TSP city labels. Different problem class, identical design strategy.
- Y1 (warm-started QAOA). Method overlap on layered variational ansatz with depth-vs-quality sweeps; this paper does not warm-start (uses random init + canonical |π0⟩) so the connection is structural only.
- Y3 (QAOA portfolio + noise crossover). Both run end-to-end optimization (sim + hardware) and explicitly compare noise mitigation. The Lin et al. NMR + SPSA + IBU choice is a different noise regime than the IBM/superconducting setup of Y3, but the methodological scaffolding (raw vs mitigated trajectory comparison) parallels Y3's shot-noise vs thermal-noise analysis.
- Y4 (Grover + ADMM cardinality-constrained). The divide-and-conquer split into smaller subproblems with classical aggregation is a quantum-classical hybrid in spirit, although mechanically very different from ADMM's primal-dual scheme.
- Y5 (GW + Gibbs + Pauli sparsity). Tangential — both exploit Z-string Pauli structure, but for different ends.
- Y6 (PBR/Heron). No meaningful overlap.
Recommended action for Yuan
- Cite in next QAOA-encoding paper. Strong methodological parallel with Y2 — this is exactly the kind of contemporary work that should be in the related-work section the next time you discuss compact encodings + hard mixers. The TSP example is also a useful counter-application showing the encoding strategy generalizes beyond portfolio.
- Read carefully if planning a "constraint-preserving mixers — survey/comparison" follow-up. The CSWAP-based register-swap primitive is a genuinely different mechanism from your QAOA mixer Hamiltonians and worth understanding for any methods comparison.
- Possible reciprocal-cite ask. The authors do not currently cite any of Y1–Y6, but the Y2 method overlap is direct enough that a brief email to Cong Guo (cguo@spinq.cn) flagging Y2 as related work for any v2 revision would be reasonable, if you want to seed the connection.