A Resource-Efficient Variational Quantum Framework for the Traveling Salesman Problem
Abstract
The Traveling Salesman Problem (TSP) is a prototypical combinatorial optimization problem, but its quantum implementation is limited by the O(n2)-qubit overhead of standard one-hot encodings. Here, we propose a resource-efficient variational quantum framework based on compact binary-register encoding, a permutation-preserving problem-inspired ansatz, and a complementary divide-and-conquer execution strategy. The compact encoding reduces the data-qubit requirement to O(n log n), while the divide-and-conquer formulation lowers the number of qubits required in each local hardware execution to the size of the largest subsystem. Numerical simulations on TSP instances with 4, 5, and 6 cities achieve best average success rates of 100%, 100%, and 95.5%, respectively. A local two-qubit implementation of the divide-and-conquer approximation is further evaluated for a 5-city TSP instance on SpinQ Gemini Pro and SpinQ Triangulum II NMR quantum computers. Taken together, the results indicate how compact encoding and divide-and-conquer execution with classical post-processing can be used to study small combinatorial optimization instances on resource-constrained quantum hardware.
Executive summary
The authors attack the same qubit-overhead bottleneck that motivated Yuan's quasi-binary encoding for portfolio optimization (Y2): instead of one binary variable per city/position pair (n2 qubits), each tour position is held in a ⌈log2(n−1)⌉-qubit register, giving an M⌈log2 M⌉ data-qubit budget after fixing one starting city. They pair this compact encoding with a feasibility-preserving "permutation ansatz" built from ancilla-controlled register-wise SWAPs — the binary-register analogue of a hard-constraint mixer. On 4–6 city benchmarks (10 random graphs, 100 random inits each) the ansatz hits 100%, 100%, 95.5% best-average success. A second contribution is a "divide-and-conquer" execution strategy that exploits the diagonality of the cost Hamiltonian in the computational basis to factorize global expectation values into per-subsystem local measurements, used here to actually run a 5-city instance on a 2-qubit NMR processor. The paper does not cite any of Y1–Y6, but it is the closest methodological analogue this announce cycle to Yuan's compact-encoding + hard-mixer line of work and is worth tracking as a parallel implementation of the same ideas in a different (TSP / NMR) setting.
Main contribution
The central object is a cyclic-symmetry-reduced binary-register Hamiltonian for the TSP whose ground state is an optimal Hamiltonian cycle. Fixing the starting city kills the n-fold cyclic redundancy and leaves M = n−1 positions; each position is a k = ⌈log2 M⌉-qubit register holding a binary city label. A projector Pi(a) onto code a in register i is built as ∏b(1+(−1)abZi,b)/2, and three terms — repetition penalty, invalid-code penalty, and a tour-length term that adds a tilde{D}abPi(a)Pi+1(b) for every adjacent register pair — assemble the full diagonal Ising Hamiltonian (Eqs. 7–10 of the paper). Atop this Hamiltonian sit two complementary engines: (i) a permutation-preserving ansatz that mixes amplitude only inside the feasible permutation subspace via parameterized controlled register swaps, eliminating the need for repetition / invalid-code penalty terms during optimization; and (ii) a divide-and-conquer execution that drops inter-subsystem entanglement so that the diagonal Hamiltonian factorizes over local two-qubit measurements. The first targets compact-but-still-multi-qubit hardware; the second targets the most extreme NISQ regime (the 2-qubit NMR machines used here).
Key algorithms / constructions
- Compact encoding (Eqs. 6–10): M⌈log2 M⌉ data qubits for an n-city TSP after fixing one starting city, vs. (n−1)2 = M2 qubits for the standard one-hot reduced encoding. For M=5 this is 15 vs 25; for M=10 it is 40 vs 100.
- Parameterized controlled register-swap (Eq. 12): Uswap(i,i+1)(θ) = Ry(aux)(2θ)·∏b CSWAP(qaux, ib, (i+1)b). One auxiliary qubit, reused across the circuit, coherently fractionalizes adjacent transpositions; adjacent transpositions generate the symmetric group, so any feasible permutation is reachable with sufficient depth.
- Permutation-preserving ansatz (Eqs. 13–14): L layers of register-wise neighbour swaps; (M−1)L = (n−2)L parameters; total qubits M⌈log2 M⌉ + 1; CSWAP gate count ⌈log2 M⌉(M−1)L.
- Divide-and-conquer factorization (Eqs. 16–18): uses the fact that H is diagonal (only I, Z) so for any product state |ψ⟩ = ⊗i|ψi⟩, ⟨H⟩ = Σt ct ∏i⟨ψi|Õt,i|ψi⟩. Inter-subsystem entanglement is sacrificed; local subsystems still allow intra-subsystem entanglement.
- Hardware ansatz (Fig. 1 of paper): a 2-qubit hardware-efficient block — Ry(θ1) and Ry(θ2) on q0, q1; a controlled-Z; then Ry(θ3), Ry(θ4) — used as the per-subsystem ansatz in the divide-and-conquer NMR experiments.
- Optimization protocol: Adam for the simulator runs (1000 inits per (n,L) with L swept n−1 to 30), SPSA for the hardware runs (120 iterations, 1024 shots per circuit).
- Measurement-error mitigation: a 2-qubit readout calibration matrix is acquired before each hardware run, then either matrix inversion or iterative Bayesian unfolding (IBU) is applied to the raw counts.
Detailed walkthrough
The paper opens with the standard one-hot QUBO (Eqs. 1–3): n2 binary variables xi,u with row- and column-sum equality constraints, a distance term Σ Duv xi,u xi+1,v, and two penalty terms enforcing each-city-once and each-position-once. The pain point — n2 qubits and constraint-violating energies that reshape the cost landscape — is the same one Y2 attacks for portfolio optimization with quasi-binary encoding plus a hard XY-mixer that never leaves the feasible cardinality slice. Section 2.2 of the present paper rebuilds the Hamiltonian on top of binary city-label registers with cyclic-symmetry reduction (M = n−1), giving the M⌈log2 M⌉-qubit count. They are explicit that this is conceptually the same move as Ramezani et al. (2024) but composed with the symmetry reduction.
Section 2.3 is the methodologically interesting half. Rather than QAOA's alternating cost-mixer schedule, they construct a single problem-inspired ansatz that intrinsically lives inside the feasible permutation subspace. The trick is a controlled register swap: an auxiliary qubit prepared in |0⟩ is rotated by Ry(2θ) and then conditionally swaps two adjacent k-qubit registers (k CSWAPs in parallel). Because adjacent transpositions generate SM, an L-layer chain of such blocks can in principle reach any feasible tour. Final tour probabilities are obtained from the marginal over the auxiliary qubit. This is the binary-register analogue of Y2's hard XY-mixer: the "feasibility" is built into the gate primitive rather than enforced via penalty terms in the cost. Because penalties are dropped, the variational objective is just ⟨Hdist⟩, which simplifies the optimization landscape — the same logical motivation that drives Y2's mixer choice.
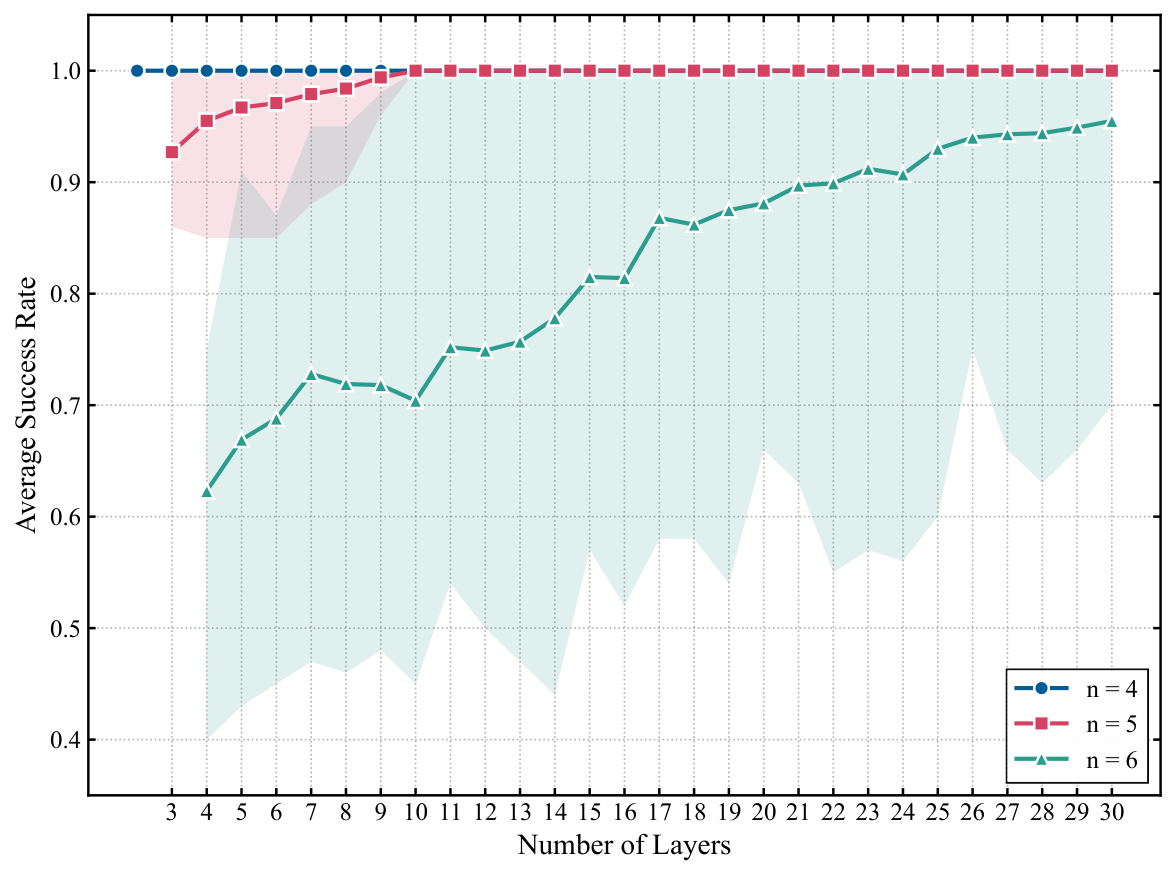
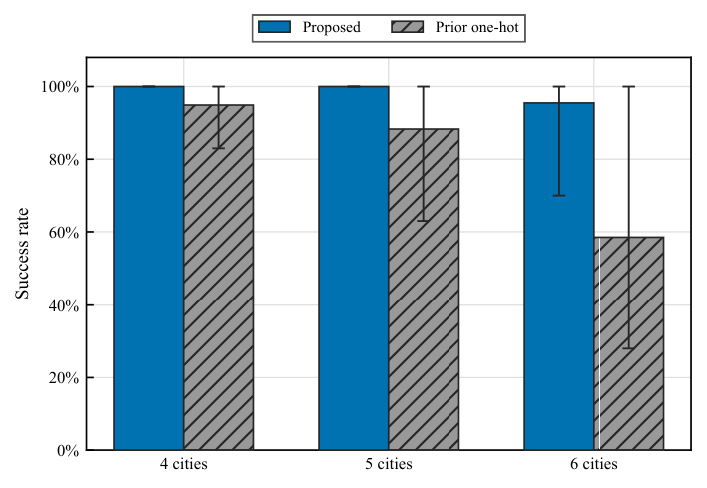
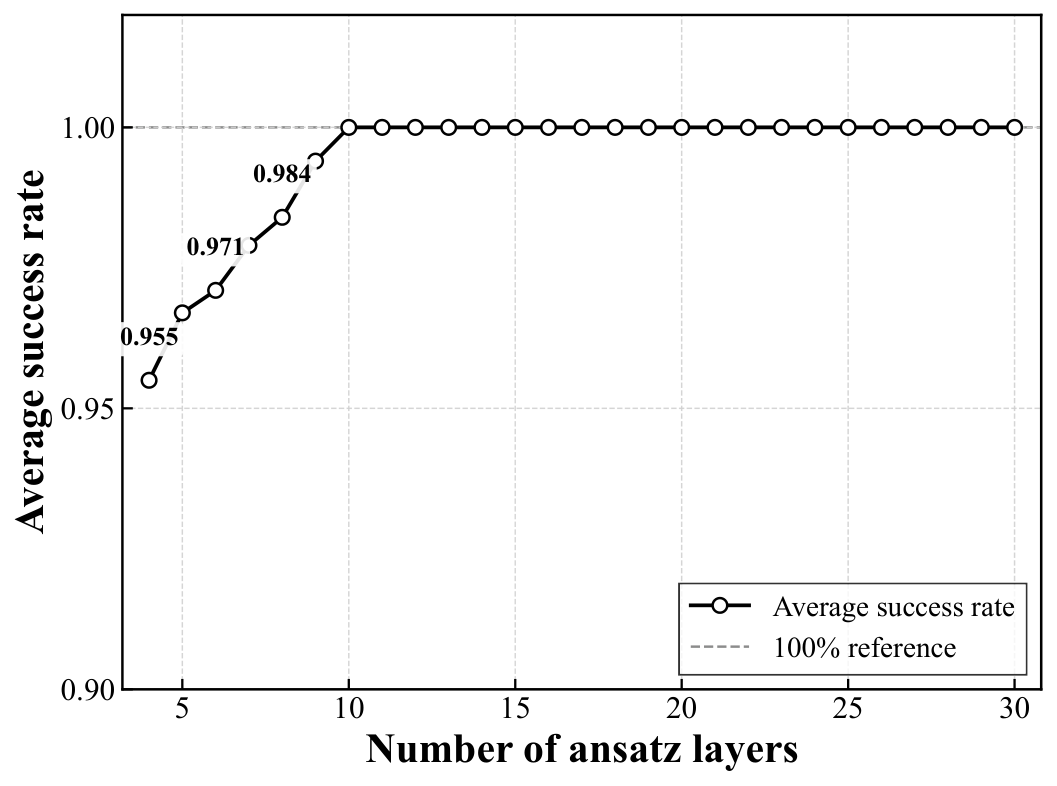
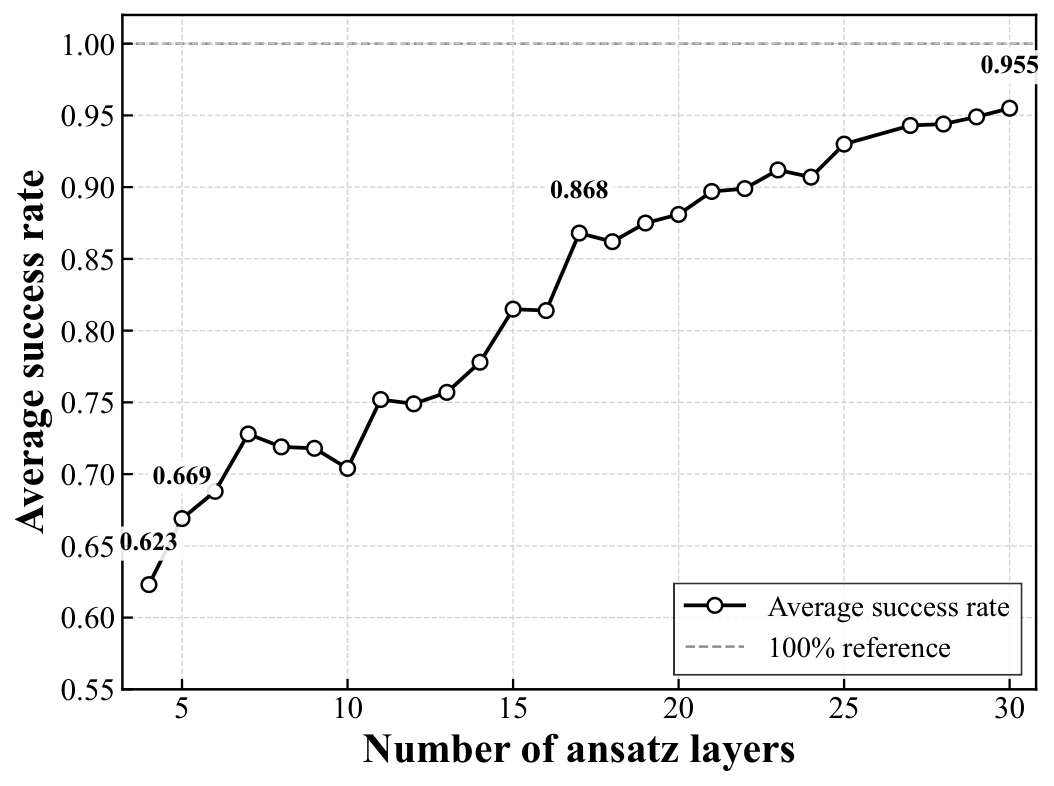
The simulator results (Fig. 2 / Section 3.2) sweep depth L from n−1 to 30 over 10 random graphs × 100 random inits. The 4-city instance trivially saturates 100%; the 5-city case rises from 92.7% at minimum L to 100% from L=10 onward; the 6-city case shows the most depth dependence, climbing from 62.3% to 95.5% at the largest tested depth and never quite reaching 100% on average. The shaded bands narrow with depth, suggesting better instance-to-instance robustness as depth increases — a pattern that mirrors what Y3 found for QAOA layerwise optimization on DGMVP portfolios. Section 3.3 then benchmarks against Matsuo et al. (2023)'s one-hot feasible-subspace ansatz on the same 4/5/6-city set: 100% / 100% / 95.5% (this work) vs. 94.9% / 88.3% / 58.5% (Matsuo). The 6-city gap is the dominant evidence — 37 percentage points absolute, with the minimum-success-rate floor lifting from 28% to 70% — though the authors are careful to flag this as "not a fully gate-budget-matched benchmark" because the encodings differ.
Table 2 of the paper makes the resource scaling concrete: the proposed circuit needs M⌈log2 M⌉+1 qubits and (M−1)L parameters, with ⌈log2 M⌉(M−1)L CSWAPs; the prior one-hot subspace ansatz needs M2 qubits, M2−M+2 two-qubit gates, and a cubic ⅓M3−½M2+⅙M−1 CSWAPs. The CSWAP-decomposition cost on hardware-native gate sets is acknowledged as a confound that motivates further matched-budget benchmarks.
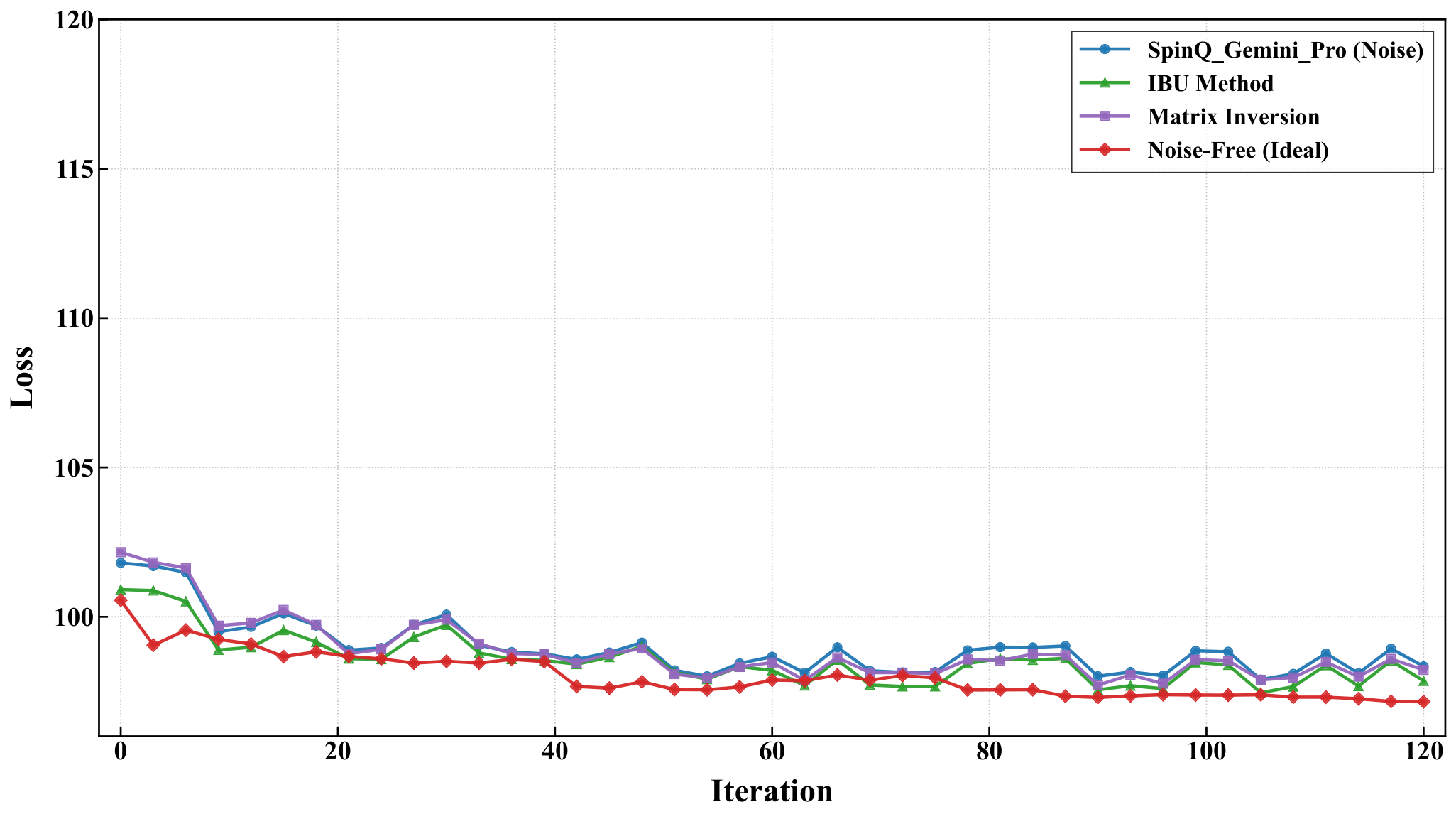
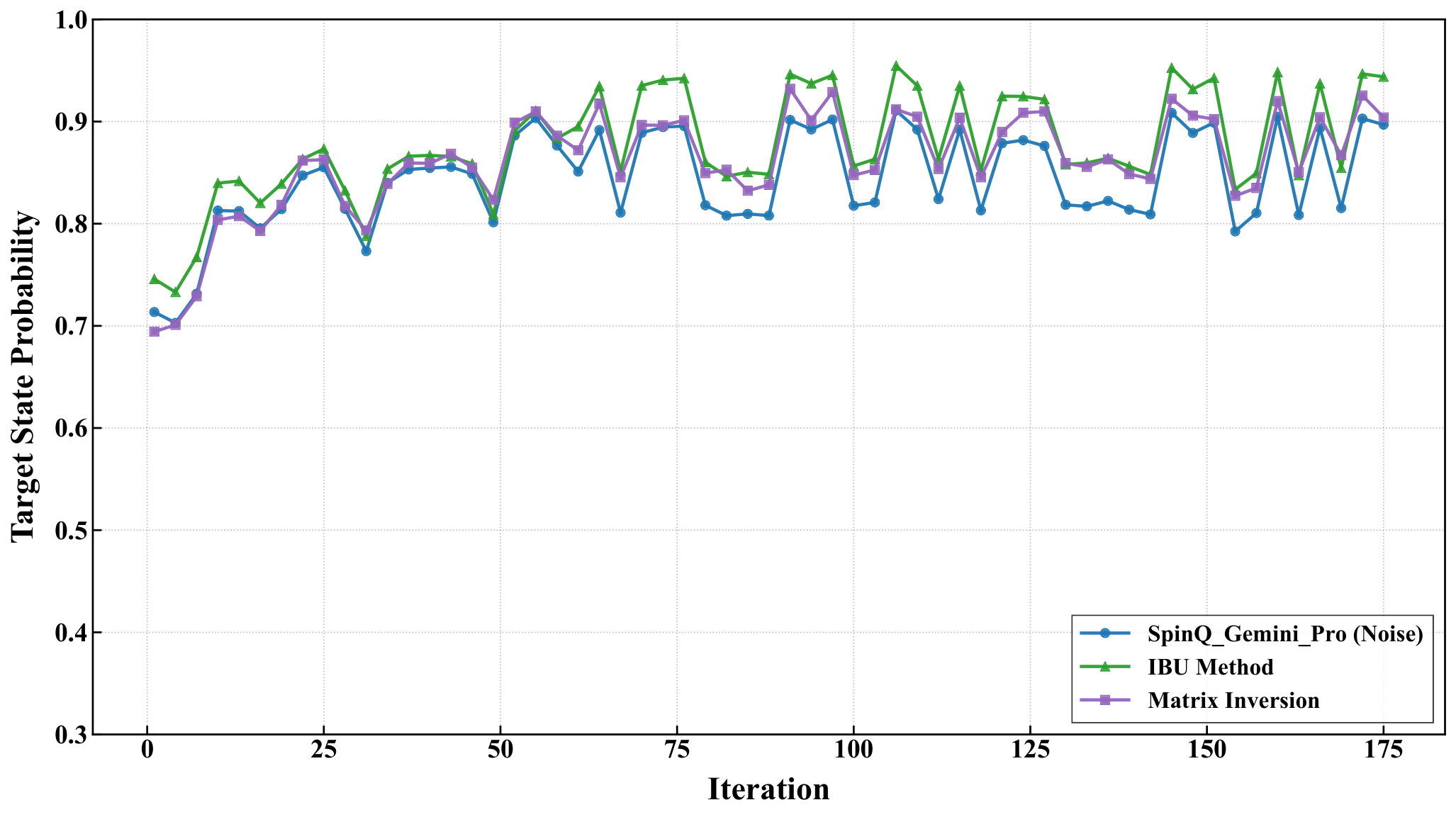
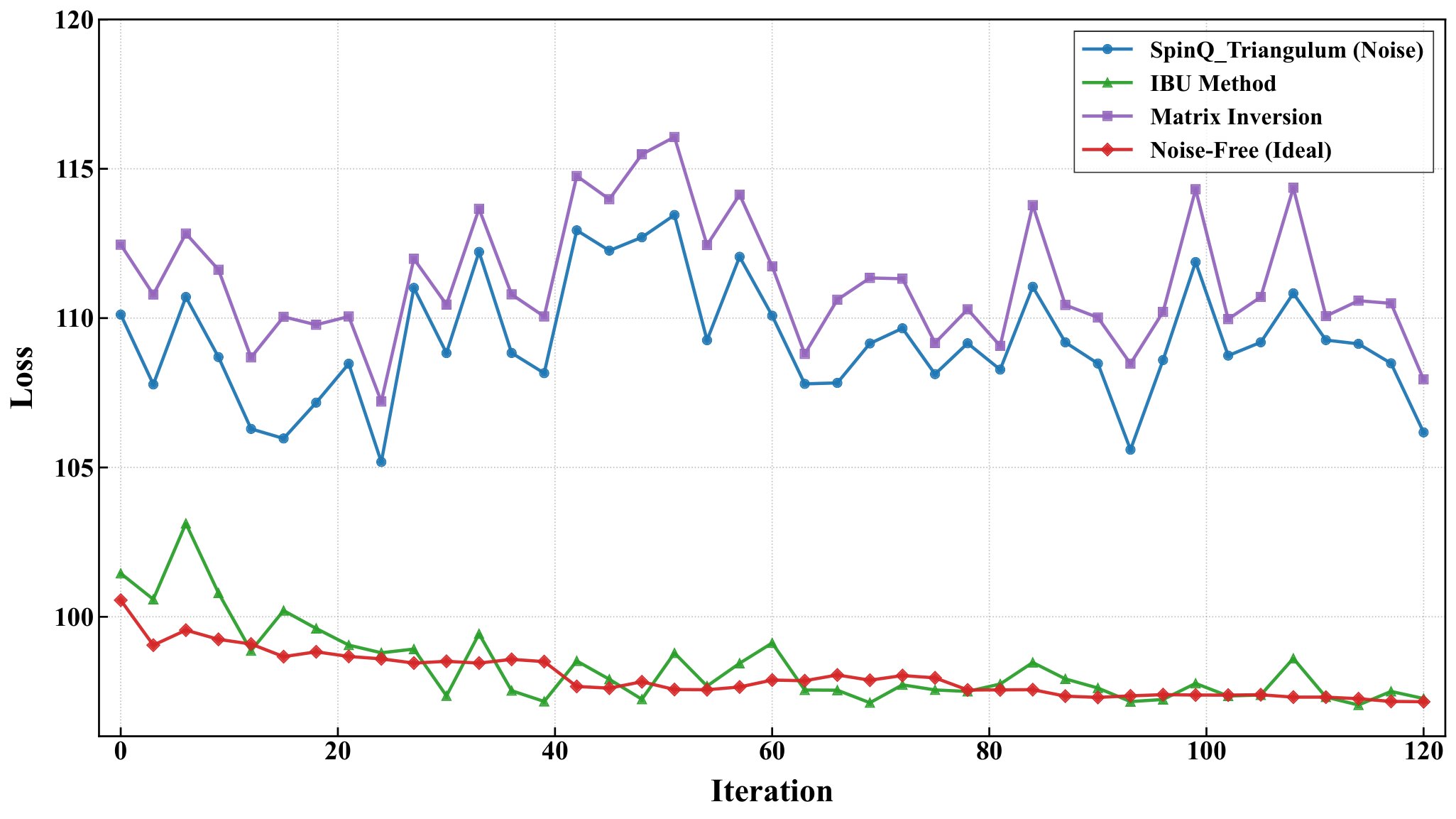
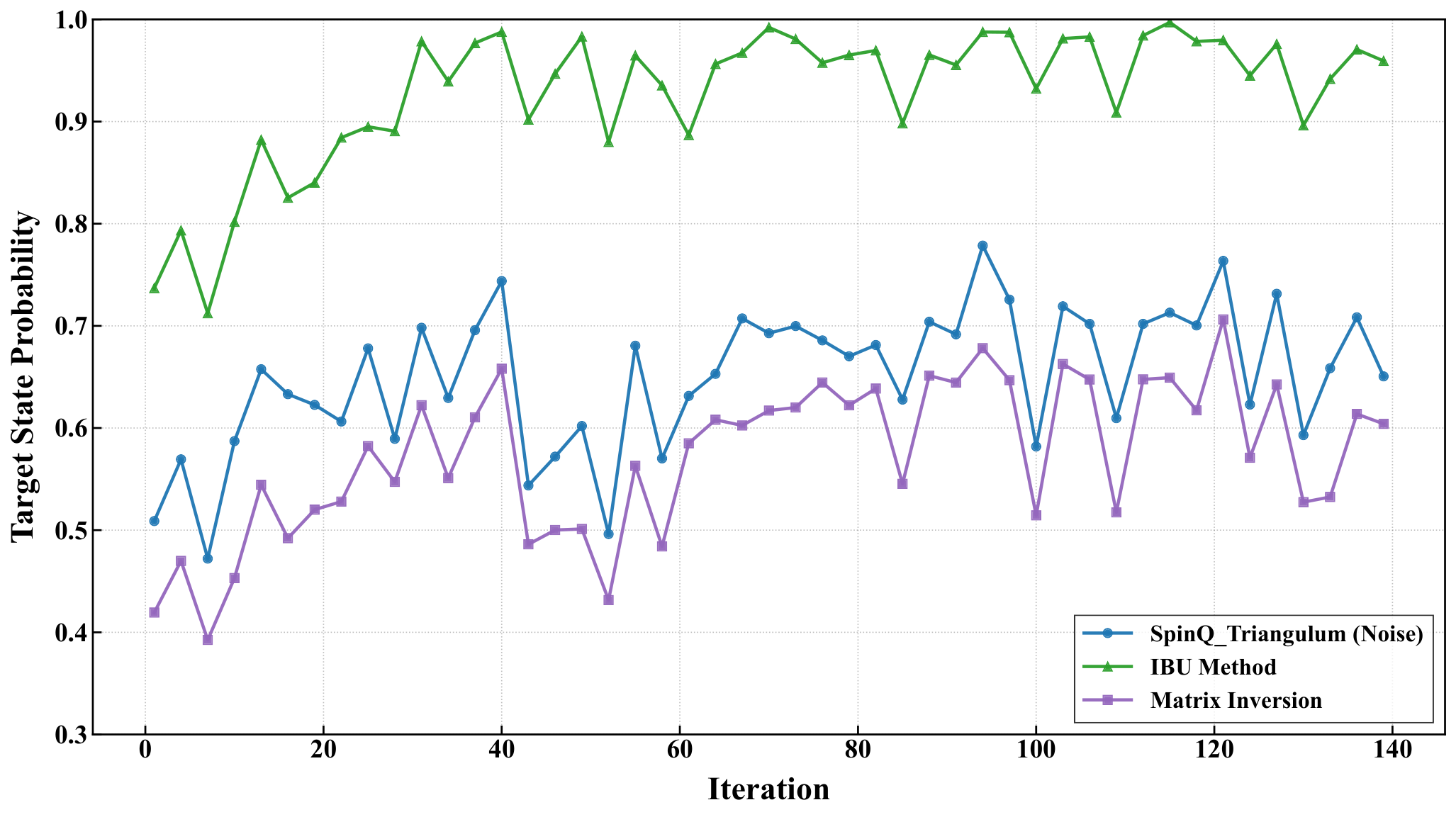
Section 3.4 deploys the divide-and-conquer engine on hardware. For the 5-city instance the symmetry-reduced problem is an 8-qubit Hamiltonian (M=4, k=2 → 4 registers × 2 qubits = 8); they partition into 4 subsystems of 2 qubits each, prepare the 2-qubit hardware-efficient block on each, and reconstruct the global energy by classical multiplication of subsystem expectation values. SPSA drives 120 optimization iterations with 1024 shots/circuit. On Gemini Pro the raw loss falls 101.81 → 98.75, with target-state probability 0.714 → 0.829; IBU mitigation pushes those to 98.35 / 0.868. On Triangulum II raw measurements are noisier (loss fluctuating 108–112, target-state probability 0.651), but IBU-mitigated trajectories sit in 97–100 with target-state probability 0.959 (peaking >0.98). The authors attribute IBU's edge over matrix-inversion mitigation to its preservation of physical probability constraints under noisy calibration — the same reason matrix-inversion error mitigation is fragile in Y3-style shot-noise studies.
The conclusion (Section 4) is appropriately hedged: the work covers only 4–6 city instances; trainability under barren plateaus is unanalyzed; and the divide-and-conquer approximation deliberately discards inter-subsystem entanglement, which limits accuracy when the optimal-solution distribution is correlated. The authors flag matched-budget benchmarks against one-hot ansatze and CSWAP decomposition cost as the obvious next steps.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary encoding + hard mixer for portfolio): the strongest parallel. Both papers replace one-hot encoding with a logarithmic compact encoding (Y2: ~2log2(U−L+1) qubits per asset; this paper: ⌈log2 M⌉ qubits per tour position) and pair it with a feasibility-preserving mixer (Y2: hard XY-style mixer over fixed cardinality slice; this paper: ancilla-controlled register-SWAP that never leaves the permutation subspace). The motivation paragraph — penalty terms reshape the landscape and waste qubits — is essentially the same. Differences: Y2 is QAOA-style alternating cost-mixer with iterative refinement and CVaR-QAOA loss; this paper uses a single problem-inspired ansatz with Adam/SPSA and plain energy loss.
- Y4 (Grover + ADMM for cardinality-constrained binary optimization): shared scope of constrained discrete combinatorial optimization with structured feasible spaces. Y4 attacks cardinality constraints with sqrt(C(n,k)/M) Grover rotations plus ADMM; this paper attacks permutation constraints with a feasibility-preserving variational ansatz. Different algorithmic family, but the design philosophy — exploit the structure of the feasible set rather than penalize infeasibility — is identical.
- Y3 (end-to-end QAOA portfolio with shot-noise / thermal-noise crossover): shared scope of NISQ-era variational optimization for combinatorial problems. The hardware section's IBU-vs-matrix-inversion comparison is in the same broad territory as Y3's sensitivity analysis to thermal vs. shot noise — both papers find that fragile mitigation strategies destabilize the variational optimization. The depth-dependent success-rate behaviour (62.3% → 95.5% on 6 cities) also echoes Y3's layerwise / dual-annealing depth-vs-quality trade-off.
- Y1 (warm-started QAOA, 3-regular MaxCut): weaker overlap. The fixed canonical initial permutation |π0⟩ used here is a deterministic warm-start of sorts, but it is structural rather than measurement-derived; it does not iteratively refine from a quantum measurement as Y1 does. Conceptually adjacent but not directly comparable.
- Y5 (GW SDPs via Pauli-sparse Gibbs states), Y6 (PBR on Heron2): no meaningful overlap.
Recommended action for Yuan
- Cite in the next compact-encoding paper. This is the most natural recent reference point for Y2's quasi-binary + hard-mixer design pattern applied in a different problem domain (TSP rather than portfolio). Citing it strengthens Y2's contextual grounding and signals that the paradigm generalizes.
- Read deeper, then consider a matched-budget benchmark. The CSWAP gate count ⌈log2 M⌉(M−1)L scales much better than the prior one-hot construction's cubic CSWAPs, but the authors flag CSWAP→native-gate decomposition as an unresolved confound. A direct CVaR-QAOA-style comparison (Y2's optimizer applied to this Hamiltonian, or this ansatz with Y2's CVaR loss) on the same 4/5/6-city benchmarks would isolate the encoding effect from the optimizer effect — exactly the matched-budget benchmark the authors call for in their conclusion.
- Email the corresponding author (Cong Guo, cguo@spinq.cn). SpinQ controls both the Gemini Pro and Triangulum II NMR platforms used here and is therefore a natural collaborator for any follow-up that wants real-hardware validation of compact-encoded combinatorial-optimization circuits. Yuan has not (per the citation check) been on their radar.