Towards High Performance Quantum Computing (HPQ): Parallelisation of the Hamiltonian Auto Decomposition Optimisation Framework (HADOF)
Abstract
Practical applicability of quantum optimisation on near-term devices is constrained by limited qubit counts and hardware noise. The Hamiltonian Auto Decomposition Optimisation Framework (HADOF) addresses this by decomposing large QUBOs into smaller subproblems that can be solved iteratively on quantum or classical backends. We extend the evaluation of HADOF by benchmarking on real IBM QPUs across sequential, single-QPU parallel, and multi-QPU parallel execution modes, advancing toward High Performance Quantum (HPQ) computing for combinatorial optimisation. Experimental results on IBM hardware show 3–4× wall-clock reduction with four QPUs, and we further validate HADOF on real-world genome-assembly instances.
Executive summary
HADOF is a QAOA-style hybrid that decomposes large QUBOs into fixed-width 5-qubit sub-problems, iteratively solves them with mean-field substitution, and aggregates. The paper's contribution is multi-QPU parallelisation: instead of solving sub-Hamiltonians sequentially, it submits them concurrently to four IBM Heron-class QPUs (ibm_kingston, ibm_pittsburgh, ibm_fez, ibm_marrakesh) using digitised QAOA with annealing-style parameter schedules. Demonstrated on randomly generated QUBOs (100–500 vars) and a 248-variable genome-assembly TSP-derived QUBO. Direct overlap with Yuan's Y3 (end-to-end QAOA on real IBM NISQ hardware), Y2 (constraint-handling for QUBO), and Y4 (decomposition philosophy similar to ADMM hybrid). The trick of using 5-qubit subcircuits to solve 500-variable problems on a 156-qubit device by avoiding monolithic embedding is precisely the kind of practical engineering Y3's analysis would credit.
Main contribution
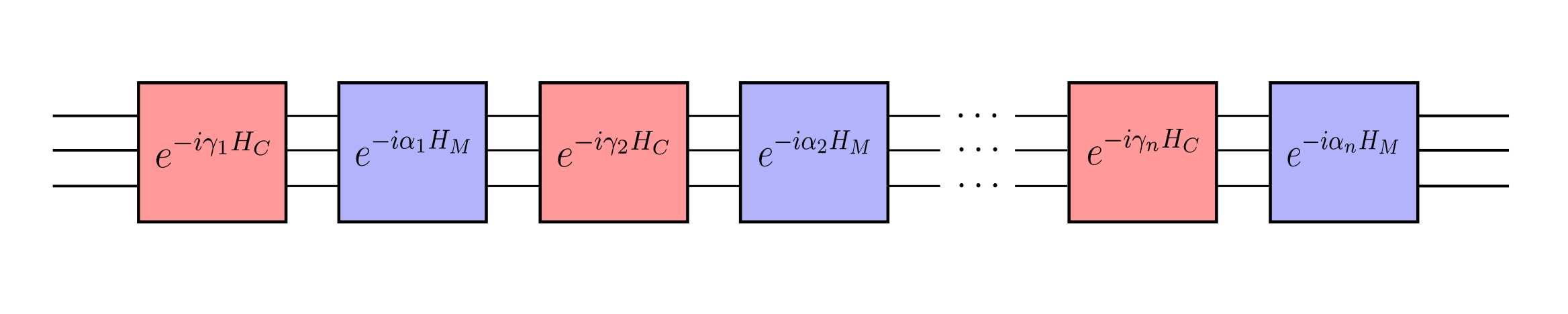
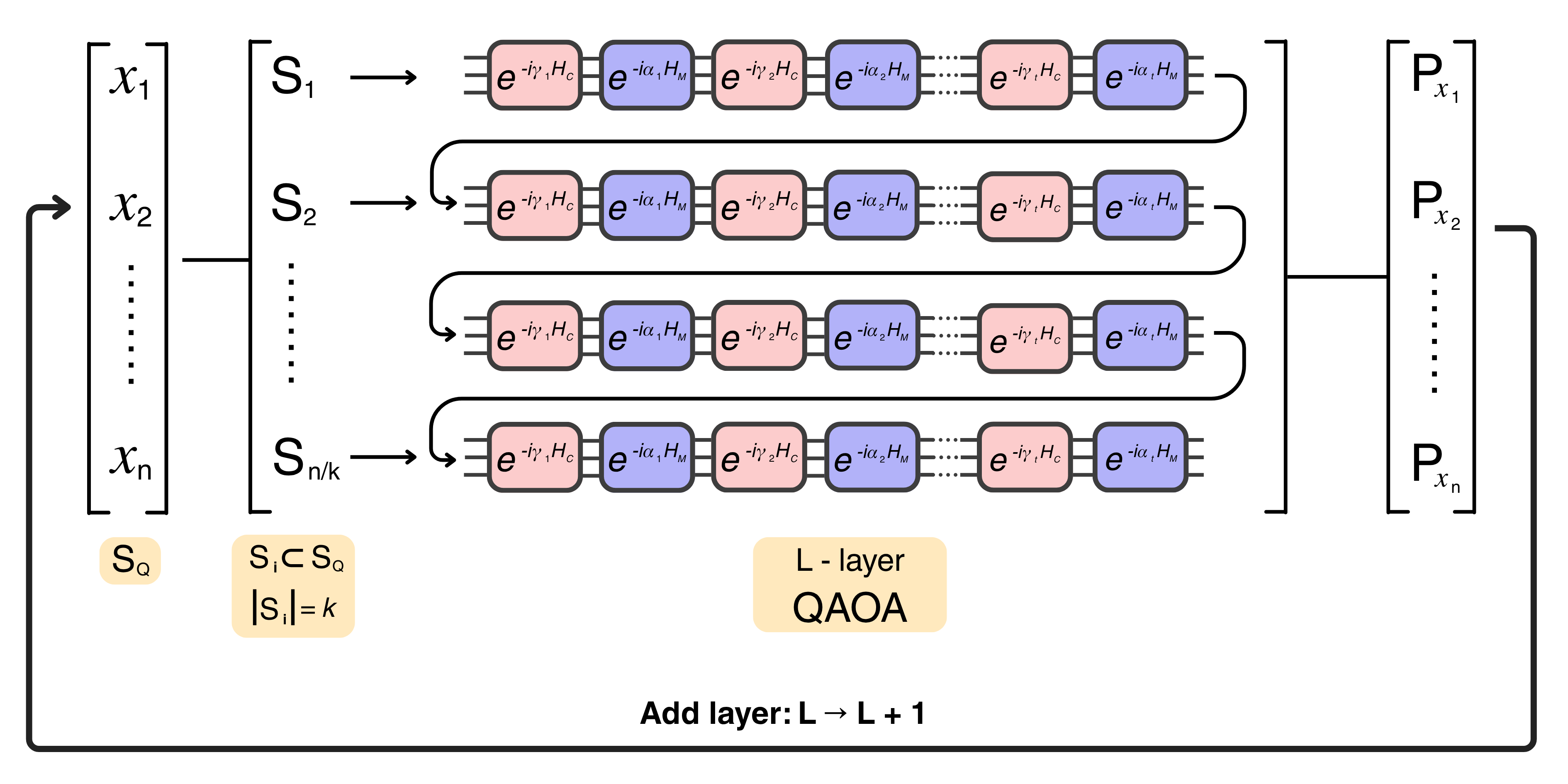
HADOF iteratively decomposes a global QUBO HQ into sub-Hamiltonians Hi defined over k=5 variables each, with the inactive (n−k) variables substituted by their expected values P(xj) from previous iterations. The QAOA layer count starts at 1 and grows by 1 per global iteration (up to 5 layers). β and γ parameters follow an annealing-trotterised schedule βm = 1−m/p, γm = m/p, removing the classical optimisation loop. The paper's parallel extension generates all sub-Hamiltonians at the start of each global iteration using last-iteration expected values, then submits them concurrently to one or more QPUs. Multi-QPU runs use the Qiskit IBM-runtime scheduler with separate jobs per device. Genome assembly is encoded as a Hamiltonian-path QUBO over a directed acyclic overlap graph (Sec. 2 of the paper); the φX 174 bacteriophage instance has 50 nodes / 248 edges / 248 binary variables.
Key constructions and algorithmic steps
- HADOF iteration loop (Sec. 3): Initialise P(xk) = 0.5 for all variables. For L = 1,…,p: for each sub-Hamiltonian i = 0,…,M−1, build Hi with inactive variables fixed to P(xj); construct depth-L digitised QAOA circuit; sample expected values P(xk) from individual qubit measurements; aggregate.
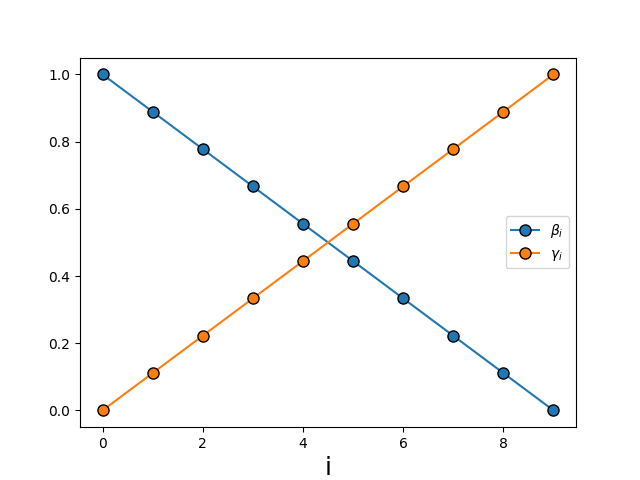
- Digitised-QAOA parameter schedule (Sec. 3, Methods): βm = 1 − m/5, γm = m/5; trotterised approximation of quantum annealing along the standard QAOA cost-mixer alternation, no classical optimiser needed.
- Genome-assembly QUBO (Sec. 2, Eq. 3): for a directed acyclic overlap graph G=(V,E), variables xuv ∈ {0,1} for each edge; Hamiltonian H = A Σu(1 − Σ(u,v)∈Exuv)² + A Σv(1 − Σ(u,v)∈Exuv)² with M = |E| logical variables instead of N² for the permutation-matrix encoding.
- Parallel execution modes (Sec. 3): sequential (legacy); single-QPU parallel via Qiskit-IBM-runtime parallel job orchestration; multi-QPU parallel across {ibm_kingston, ibm_pittsburgh, ibm_fez, ibm_marrakesh}, all 156-qubit Heron-class devices on heavy-hex topology.
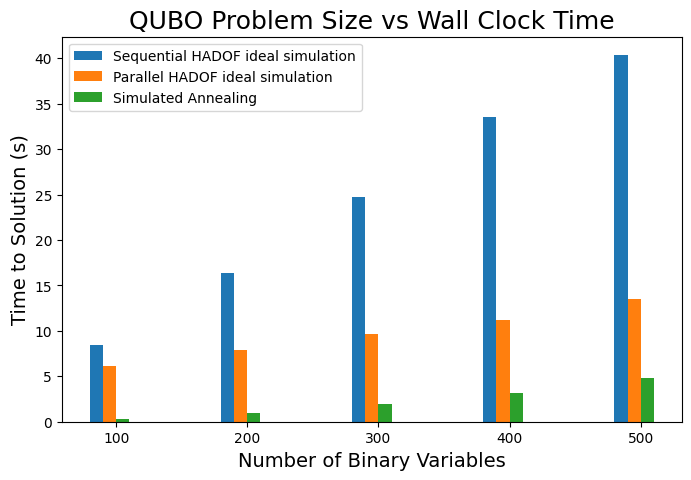
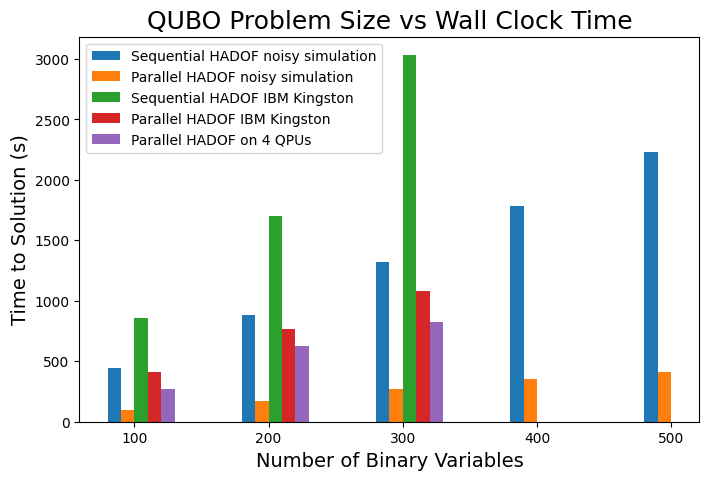
- Empirical results (Sec. 4): ideal-simulation 3× speedup at 500 variables; noisy-simulation 4–5× speedup; real-hardware 3–4× speedup; full-QAOA monolithic execution on Kingston degrades to average accuracy 0.02 at 50 vars vs HADOF's 0.53 at the same size.
- Genome-assembly results (Sec. 4.4, Table 3): 248-variable φX 174 instance; Simulated Annealing reaches optimal energy −496 in 213/N runs; ideal HADOF (sequential, parallel) reaches optimum 187/193 times; real-hardware HADOF best-accuracy 0.88–0.91 with 0 optimal but 52% of distribution recovers correct final sequence after GFAtools post-processing.
Detailed walkthrough
HADOF (Sec. 3, Methods) is a Hamiltonian-decomposition variant of QAOA: instead of embedding the full n-variable QUBO into a single ansatz, it solves k=5-variable sub-Hamiltonians iteratively. Inactive variables are replaced by their expected values P(xj) ∈ [0,1], creating an effective sub-Hamiltonian whose ground state is biased toward the global landscape. The algorithm progressively grows the QAOA depth L from 1 to p=5 across iterations, mimicking quantum-annealing-style adiabatic evolution with hand-set β/γ schedules — no classical outer optimisation loop, in contrast to standard QAOA. The mean-field-style substitution P(xj) → ⟨xj⟩ is updated by sampling each qubit individually with 500 shots per measurement.
The parallel extension (Sec. 3) is conceptually simple but operationally significant: in the original sequential HADOF, each sub-Hamiltonian within a global iteration uses the most-recently-updated expected values, creating a sequential data dependency. In the parallel version, all sub-Hamiltonians within a global iteration use the previous-iteration expected values, breaking the dependency and allowing concurrent submission to multiple QPUs. Within each iteration, expected values are updated only once at the end. Initial P(xi) = 0.5 for all variables.
The hardware setup (Sec. 4) uses four IBM Heron-class 156-qubit devices: ibm_kingston (Heron r2), ibm_pittsburgh (Heron r3), ibm_fez (Heron r2), and ibm_marrakesh (Heron r2), all heavy-hex topology. Crucially, this is the same Heron family that Y6 uses for its PBR test (Heron2). The paper notes that submission is staggered to avoid queue-time bias; all reported wall-clock times exclude queueing where reported as QPU-usage.
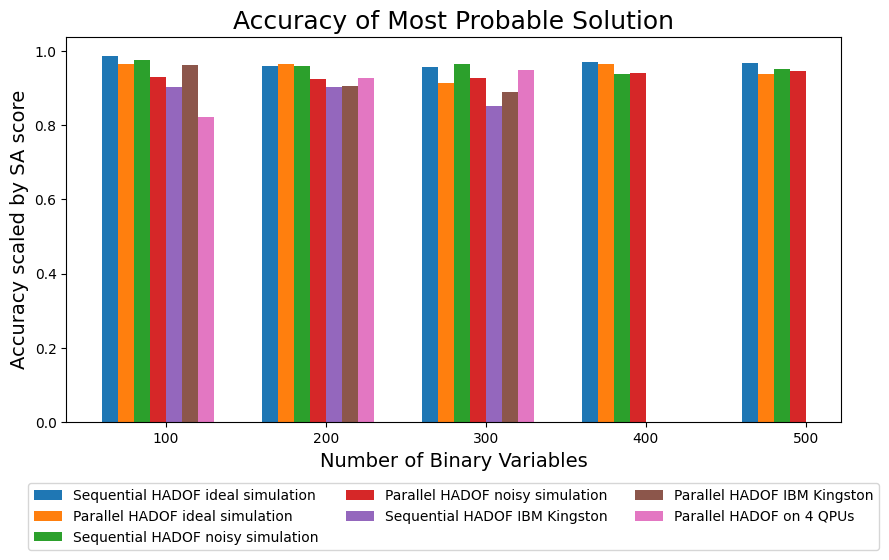
The accuracy story (Sec. 4.2, Figs. acca/accb) is structured around two metrics: (i) accuracy of the most-probable sampled solution, and (ii) average accuracy across the full sampled distribution, both normalised to simulated-annealing benchmarks. Under ideal simulation, both sequential and parallel HADOF achieve accuracy > 0.95 across all sizes 100–500. Under noisy simulation accuracy drops marginally to 0.92–0.97. On real Heron hardware, best-solution accuracy stays consistently above 0.80; the average-distribution accuracy drops to ~0.5–0.6 at larger sizes. Parallelisation does not degrade quality — the wall-clock advantages come "for free" in solution-quality terms.
Section 4.3 is the most directly comparable to Yuan's Y3: head-to-head HADOF vs full-circuit QAOA. At 50 variables on Kingston, full QAOA's average accuracy collapses to 0.02 (effectively random), while HADOF holds 0.53. The reason is mechanistic: full-circuit QAOA at 50 dense variables requires SWAP-heavy embedding on the 156-qubit heavy-hex layout (limited to ~50 dense variables in practice), and the resulting circuit depth saturates the device's coherence budget. HADOF avoids this entirely by working in 5-qubit subcircuits regardless of n. The paper's framing — "HADOF is robust because it never uses the full-circuit embedding" — is essentially what Y3's NISQ analysis was forecasting: monolithic QAOA fails at the noise crossover, but properly-decomposed QAOA can keep going.
The genome-assembly demonstration (Sec. 4.4) is the most ambitious application. The φX 174 bacteriophage genome (5386 bp) is reconstructed from 50 simulated reads (600 bp each) generated by Grinder. The overlap graph has 50 nodes / 248 edges, mapped to a QUBO with 248 binary variables for the Hamiltonian-path objective. Simulated annealing finds the unique optimal energy −496 in 213/N runs; ideal-simulation HADOF (sequential and parallel) reaches −496 in 187 and 193 runs respectively. On real Heron hardware, the best-accuracy is 0.88–0.91, no optimal solutions in the sampled distribution, but 52% of sampled solutions reconstruct the correct final sequence after post-processing with GFAtools. Multi-QPU parallel run-time is 889 s vs 2345 s sequential — a 2.6× speedup.
Section 5 (Conclusions) flags adaptive/problem-specific decomposition as a future direction. This is exactly the design space Y4's ADMM hybrid occupies. A natural composition: replace HADOF's fixed k=5 decomposition with an ADMM-style adaptive partitioning that respects QUBO sparsity, and run on the same multi-QPU testbed. Yuan's Y4 ε-approximation guarantees would translate into a stronger statement about the correctness of the federated solution.
Figures

Citations to Yuan's papers
Overlap with Y1–Y6
- Y3 (DGMVP portfolio QAOA, NISQ scaling): Strong overlap. Y3's analysis says monolithic QAOA fails at thermal-noise crossover; HADOF empirically demonstrates the failure mode (full QAOA avg accuracy 0.02 at 50 vars on Kingston) and presents decomposition as the workaround. Same hardware family (Heron); same QUBO formulation philosophy. The paper's wall-clock and accuracy curves are directly comparable to Y3's results — citing this would strengthen Y3's "decomposition is the practical path" framing.
- Y4 (Grover + ADMM hybrid): Both papers use a classical-quantum hybrid decomposition. Y4's ADMM gives ε-approximation guarantees for cardinality-constrained problems; HADOF's mean-field decomposition is heuristic but operationally simpler. A natural follow-up composition: replace HADOF's fixed k=5 partition with Y4's ADMM-style adaptive partition.
- Y2 (quasi-binary, hard mixer): Genome-assembly Hamiltonian (Eq. 3) uses standard squared-deviation penalty terms — exactly the construction Y2 dispenses with. A Y2-style hard mixer for the genome-assembly path constraint would be a natural next experiment.
- Y6 (PBR on Heron2): Shared hardware platform — Heron r2/r3 — providing comparable single- and two-qubit gate-fidelity baselines. Cross-calibration of HADOF circuit performance against Y6's gate-fidelity measurements would be informative.
Recommended action for Yuan
- Cite as the practical-decomposition complement to Y3: the head-to-head HADOF-vs-full-QAOA at 50 variables on Kingston is the empirical evidence that monolithic QAOA does not scale on current Heron hardware — exactly the conclusion Y3's noise analysis predicted. Worth citing.
- Implement HADOF with Y4's ADMM partitioning: the obvious composition. Y4's ε-approximation guarantees plus HADOF's multi-QPU runtime engineering could give a portfolio-grade end-to-end pipeline.
- Email the authors: Caton (UCD) is open to collaboration on quantum optimisation systems; the genome-assembly testbed is a clean alternative to portfolio benchmarks for cross-validation of Y2/Y4 methods.