Q3SAT-GPT: A Generative Model for Discovering Quantum Circuits for the 3-SAT Problem
Abstract
This work introduces Q3SAT-GPT, a generative model for discovering quantum circuits for the Max-E3-SAT problem. Our method learns from high-performing QAOA-style ansätze to directly generate candidate circuits. To create high-quality supervision, we also introduce Mosaic Adaptive QAOA (MosaicADAPT-QAOA), an adaptive strategy for constructing low-depth QAOA circuits by selecting subsets of mixer operators in each step, rather than inserting operators sequentially. The resulting circuits serve as training data for the generative model, allowing it to learn effective circuit design patterns while eliminating the need for costly variational optimization at inference time. Experiments show that our framework attains strong solution quality with shallow circuits and scales significantly better than both our adaptive construction procedure and conventional variational baselines.
Executive summary
Two intertwined contributions: (1) MosaicADAPT-QAOA, a variant of ADAPT-QAOA that selects a maximum-weight independent set (MWIS) of mutually-disjoint mixer operators per layer (rather than greedy single-operator selection à la ADAPT or TETRIS); (2) Q3SAT-GPT, a transformer trained to amortise the per-instance MosaicADAPT-QAOA optimisation by directly generating mixer operators and parameters from a tokenised 3-CNF formula plus FEATHER graph embeddings. Direct overlap with Yuan's Y1 (iterative warm-started/adaptive QAOA) and Y2 (mixer-construction philosophy). The mixer-tile selection is the most interesting novel piece: choosing a disjoint set of operators that maximises total gradient is provably better than the greedy ADAPT/TETRIS heuristic in the conflict cases the authors construct.
Main contribution
The paper formulates Max-E3-SAT exactly as a HUBO Hamiltonian (cubic Pauli-Z products from each clause) and constructs an enriched operator pool of single- and two-qubit Pauli mixers (excluding Z-only operators that commute with HC). At each ADAPT step, instead of greedily selecting the single highest-gradient operator, MosaicADAPT-QAOA builds an "incompatibility graph" where nodes are candidate operators (weighted by gradient magnitude) and edges connect operators with overlapping qubit support. Solving the resulting MWIS via Memetic-MWIS (KaMIS) yields a maximally-disjoint operator tile per layer. Q3SAT-GPT then learns to emit these tiles directly: a transformer encoder consumes a canonicalised 3-CNF formula and FEATHER embeddings of the literal-clause graph, and the decoder autoregressively emits a sequence (op1, β1, op2, β2, …, γ) per layer.
Key constructions and algorithms
- HUBO cost Hamiltonian (Sec. III.B): exact Pauli-Z encoding of Max-E3-SAT clauses via products of (I±Zi)/2 — yields up to 3-local Z-Z-Z terms.
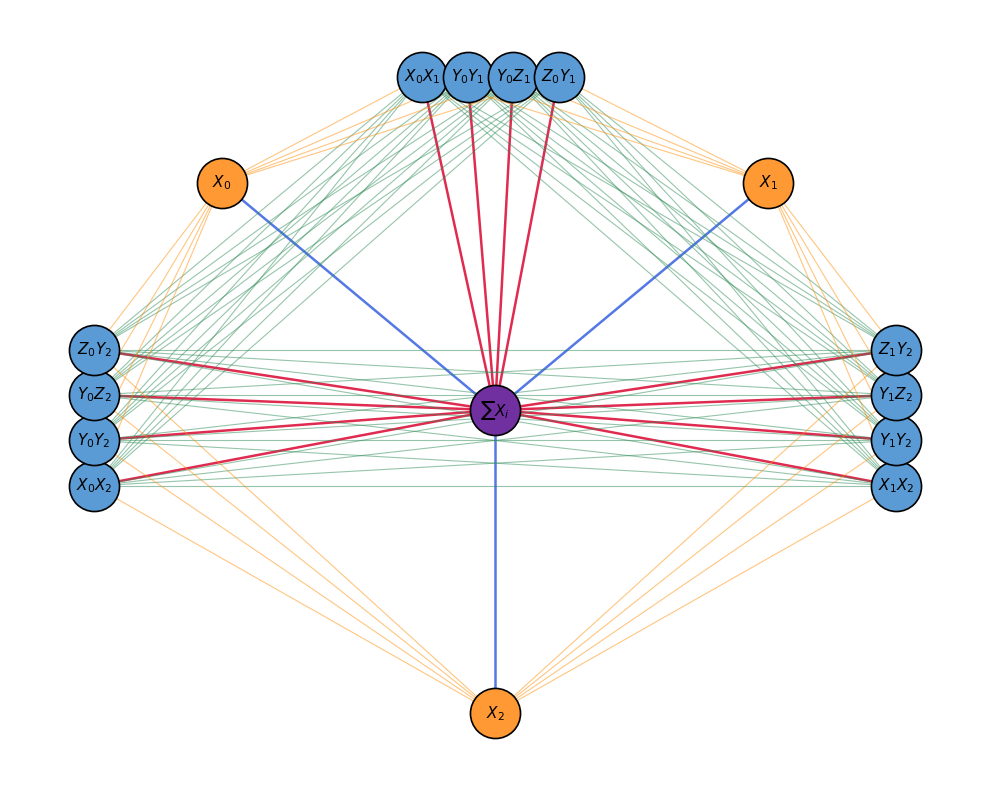
- Operator pool (Sec. III.C, Eq. 2): P = {ΣXk} ∪ {Xi, Yi} ∪ {XiXj, YiYj, XiYj, XiZj, YiZj}. Z-only operators are excluded as they commute with the diagonal HC.
- Algorithm 1 (MosaicADAPT-QAOA): at each layer, compute gj = −i⟨ψ|e−iγ₀HC[HC, Aj]e−iγ₀HC|ψ⟩ for all candidates; build incompatibility graph; solve MWIS via KaMIS; add the disjoint operator set as a single layer; reoptimise (β, γ) globally with BFGS.
- Q3SAT-GPT pipeline (Sec. III.D–G): deterministic 3-CNF canonicalisation; tokenisation of literals + clause separators; FEATHER embeddings of the literal-clause graph projected via MLP and added to token+positional embeddings; output sequence is decoded into MosaicADAPT-QAOA-style layered circuit.
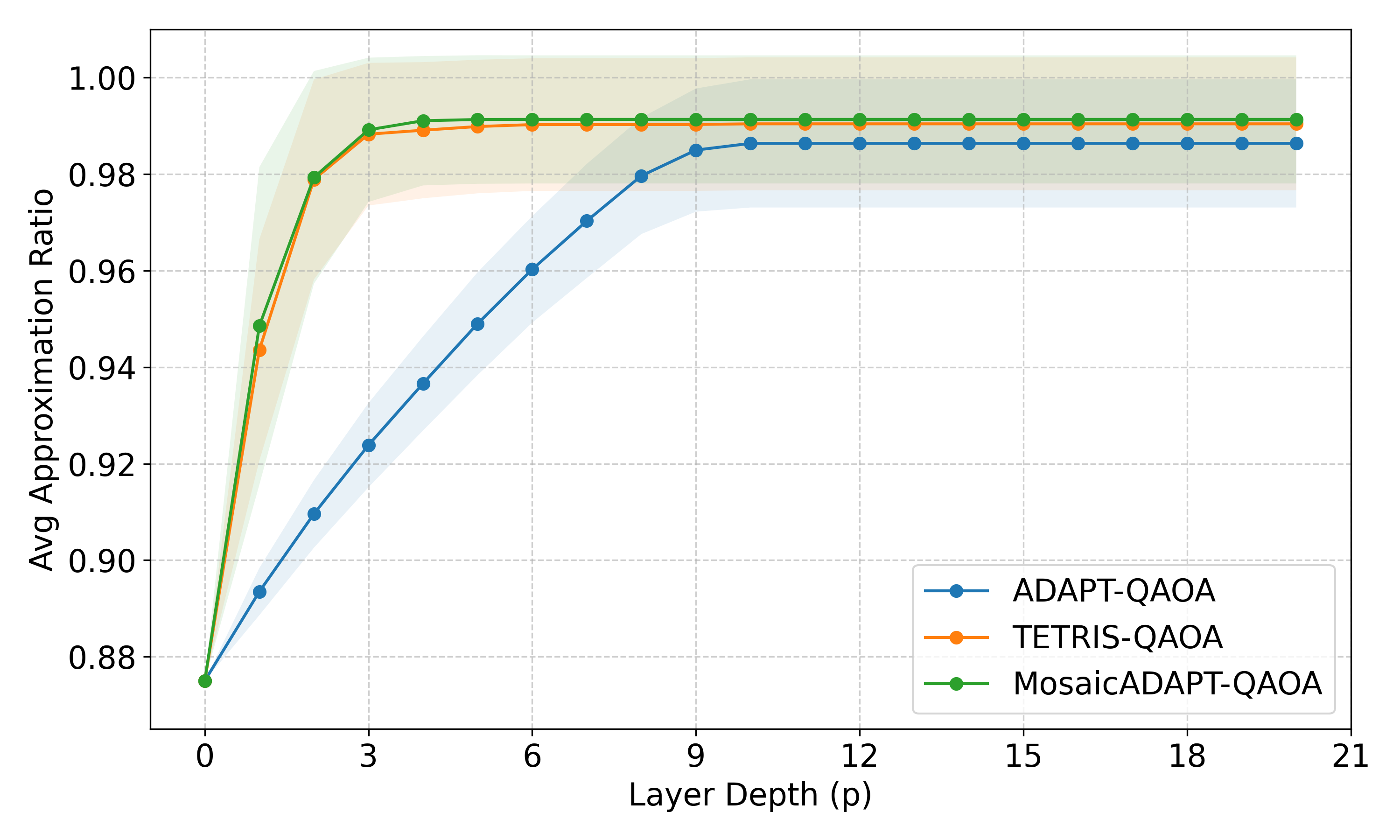
- Empirical results (Tables I–II): MosaicADAPT-QAOA achieves mean AR 99.71% at γ₀=0.5 (median 100% reaching 99.9% AR in 12 layers), beating ADAPT-QAOA (99.68%, 16 layers) and TETRIS-QAOA (99.68%, 16 layers); Q3SAT-GPT amortised inference (GPU) is 0.16 s for n=10 vs 88.21 s for sequential MosaicADAPT-QAOA on CPU (550× speedup at N=10).
Detailed walkthrough
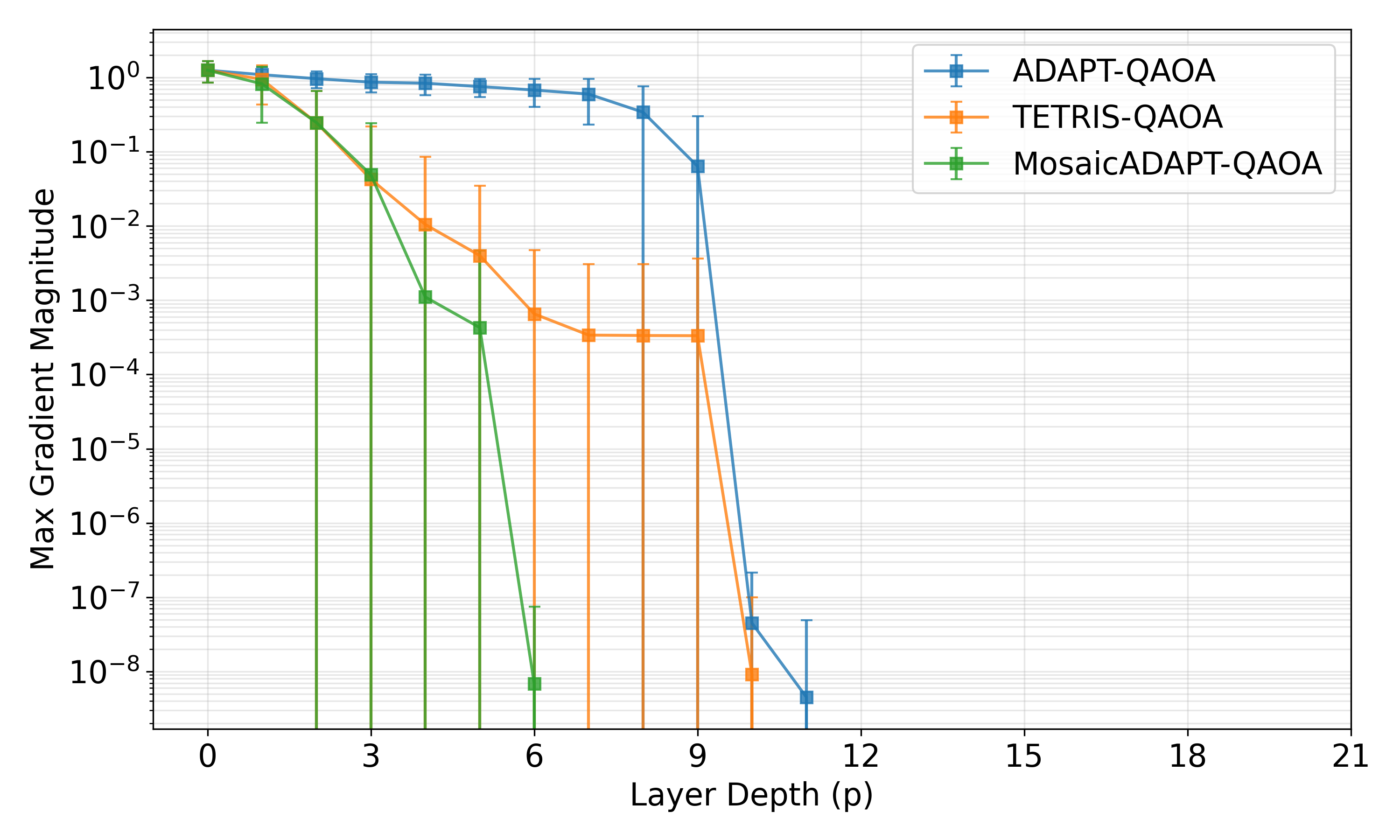
The paper opens (Sec. II.B) with a careful review of ADAPT-QAOA, the original adaptive QAOA variant that selects a single mixer operator per layer based on its individual gradient. ADAPT-QAOA's main weakness is greediness: in any layer where multiple low-overlap operators are available, ADAPT can only pick one. TETRIS-ADAPT-VQE (Anastasiou et al. 2024) addressed this by selecting a greedy disjoint set per step, but the paper observes (Fig. 1) that even greedy disjoint selection can be suboptimal when the highest-gradient operator blocks the use of multiple near-best disjoint operators.
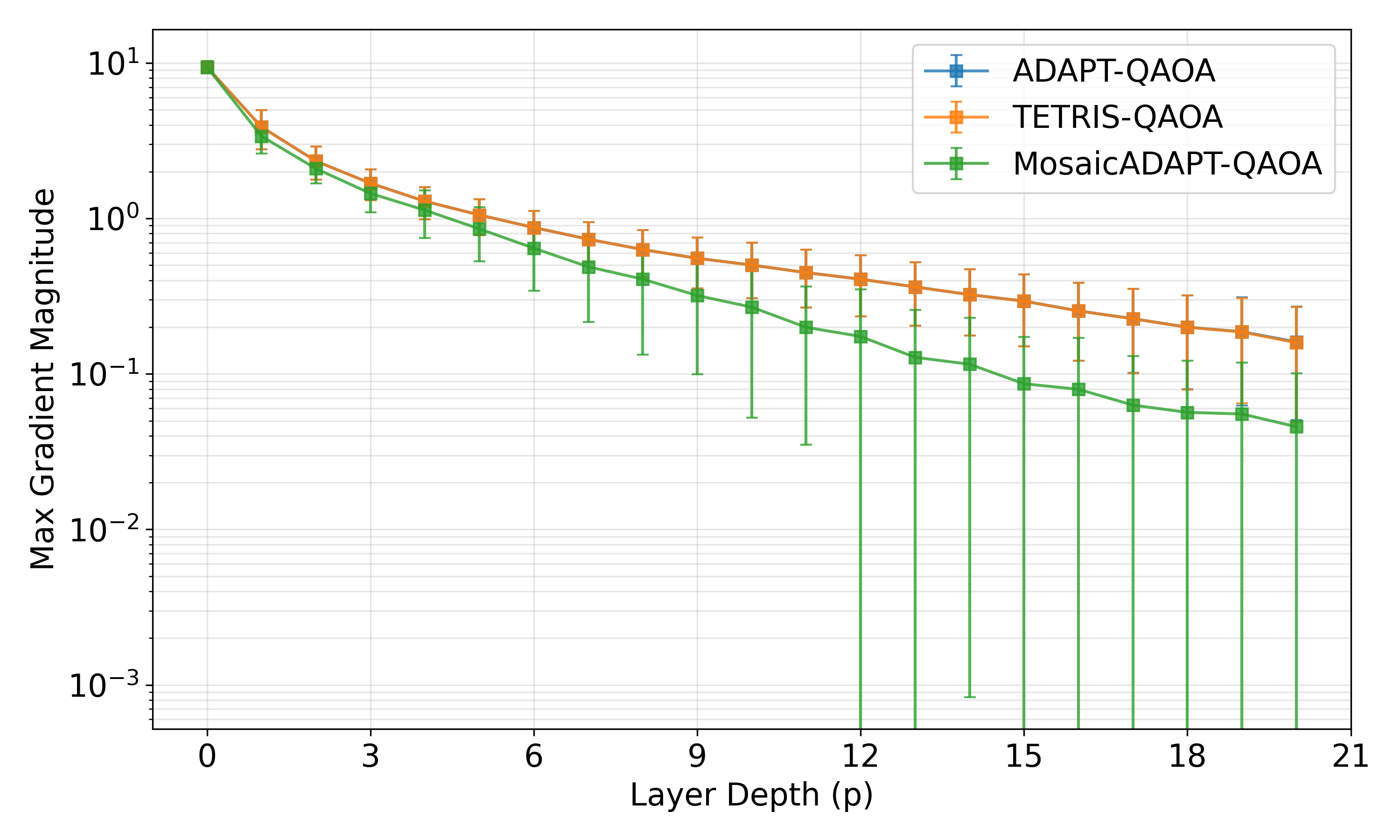
The MosaicADAPT-QAOA construction (Sec. III.C) reframes operator selection as an exact optimisation: build the incompatibility graph G where nodes are operators, weighted by their gradient magnitudes, and edges connect operators with overlapping qubit support. The optimal tile is a maximum-weight independent set on G. Because MWIS is NP-hard, the authors use the Memetic-MWIS solver KaMIS (Lamm et al.), which reaches near-optimal solutions in practice. Algorithm 1 is the high-level loop: gradient evaluation, MWIS, layer addition, BFGS reoptimisation, repeat until convergence or layer cap.
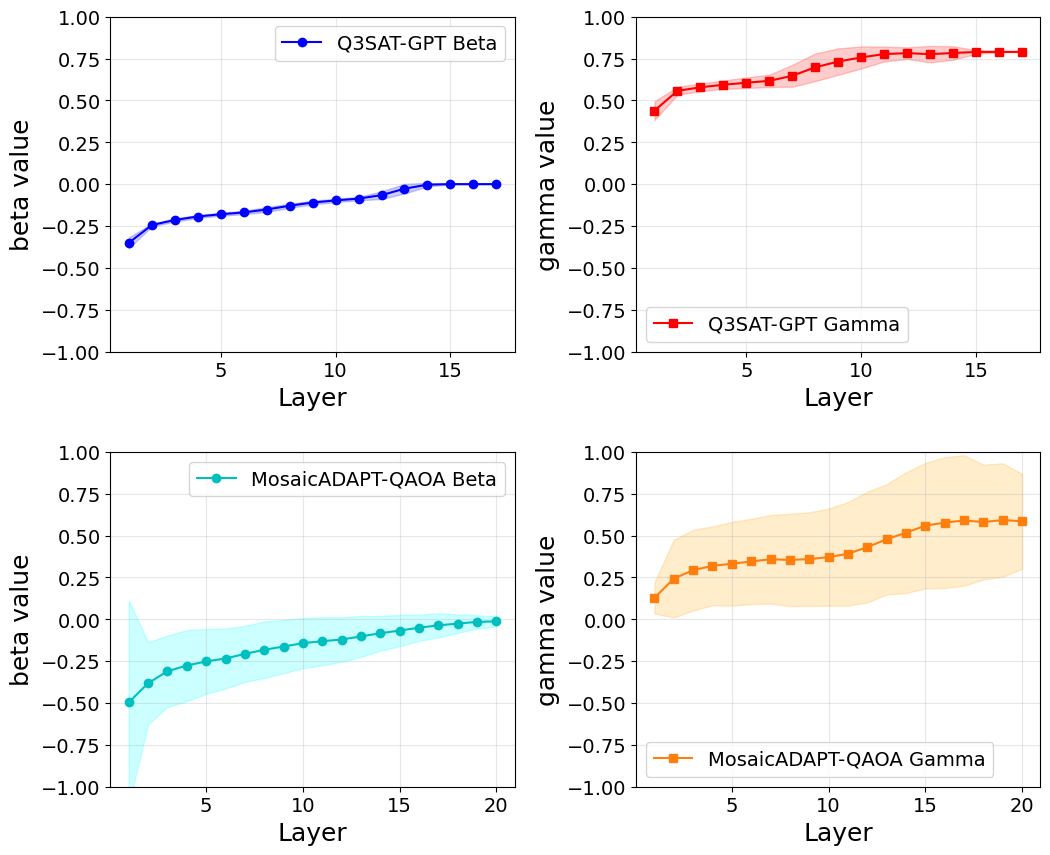
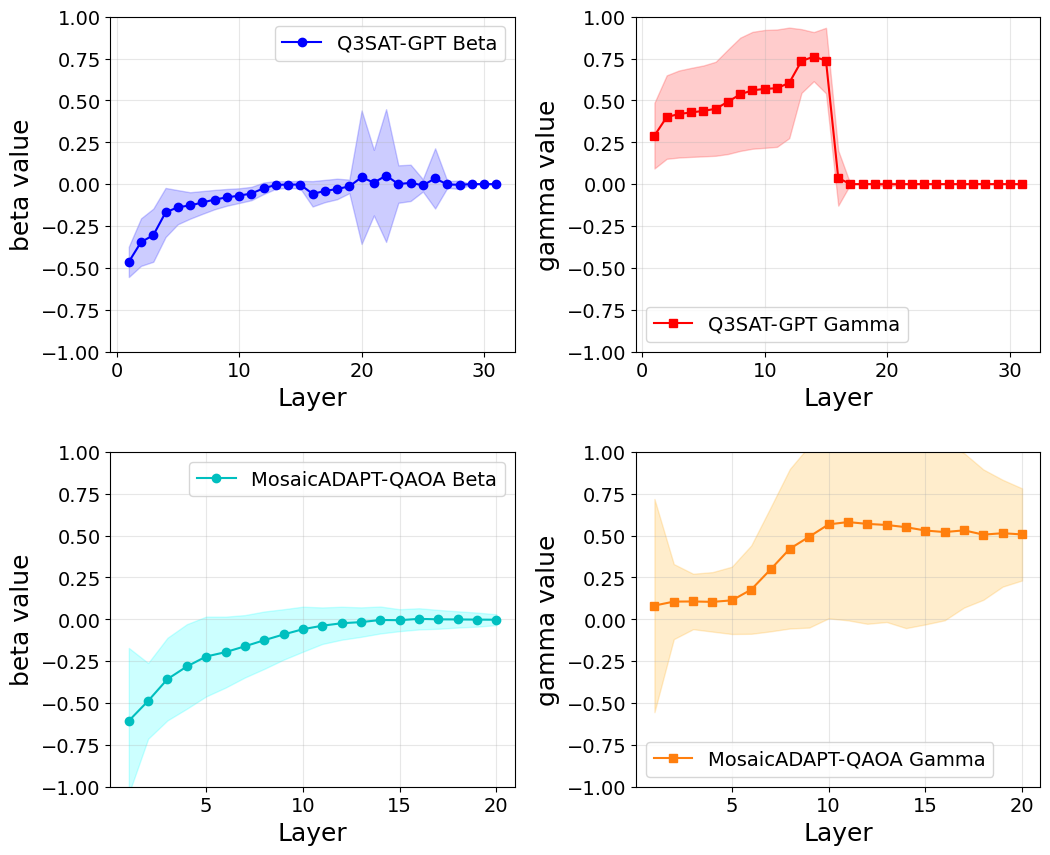
An interesting subtlety is the role of γ0, the initial cost-evolution angle used to evaluate gradients. The paper studies two regimes: γ0=0.01 (low) and γ0=0.5 (high). At γ0=0.01 all three methods (ADAPT, TETRIS, Mosaic) tend to "stick" — gradients fall below the 10⁻⁶ threshold prematurely, with Mosaic being the most aggressive at hitting this stopping condition (27/100 stuck instances). At γ0=0.5 no instance gets stuck and Mosaic uses 4 fewer layers than ADAPT/TETRIS to reach 99.9% AR. This sensitivity to γ0 is qualitatively similar to Y1's observation that warm-started QAOA initialisation matters more than the algorithm details — both papers find that the right initialisation regime is decisive for adaptive QAOA performance.
The Q3SAT-GPT side (Sec. III.D–G) is essentially an amortisation strategy: train once on 50K MosaicADAPT-QAOA-supervised examples; at inference time, generate the entire circuit (operators + parameters) in a single autoregressive pass. The model sees the 3-CNF formula as a token sequence and a FEATHER graph embedding of the literal-clause graph; the output sequence encodes the layered circuit including disjoint operator groups and parameter tokens. The loss masks input and pad tokens (Eq. 6). The architecture is a single 1024-token-context transformer (no sliding window) — large enough to fit any 10–12 variable instance.
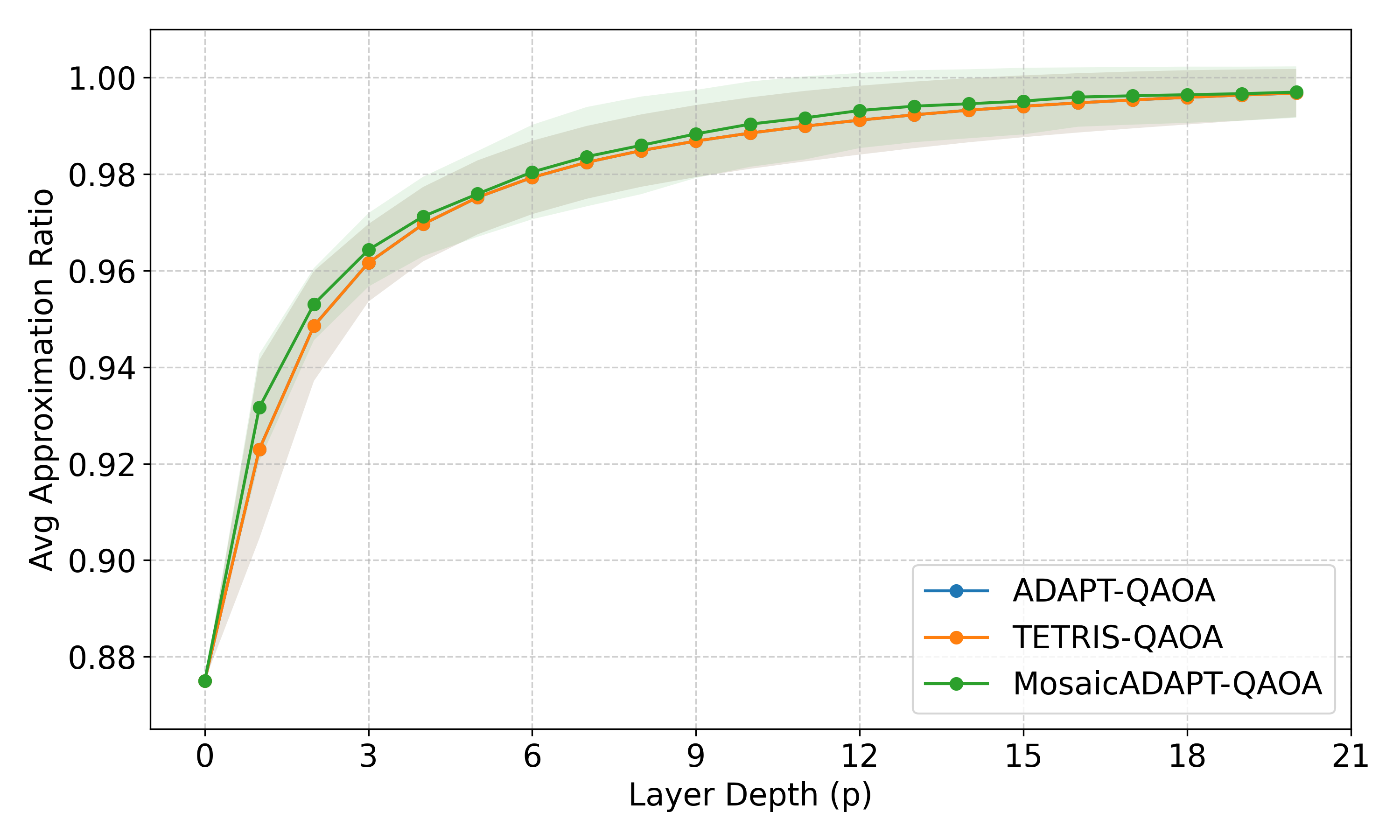
Empirically (Sec. IV), Q3SAT-GPT generates circuits whose AR is within ~2% of the MosaicADAPT-QAOA target on balanced instances and within ~3% on random instances (Table II). Notably, training with single γ0=0.5 yields better generalisation than the grid-search variant — the authors hypothesise that the grid-search supervision spreads its signal across multiple local minima, confusing the model. The runtime story (Table III) is the practical pitch: 0.16 s amortised inference vs 88 s of CPU MosaicADAPT-QAOA at n=10, scaling to 0.45 s vs 504 s at n=12 — three orders of magnitude.
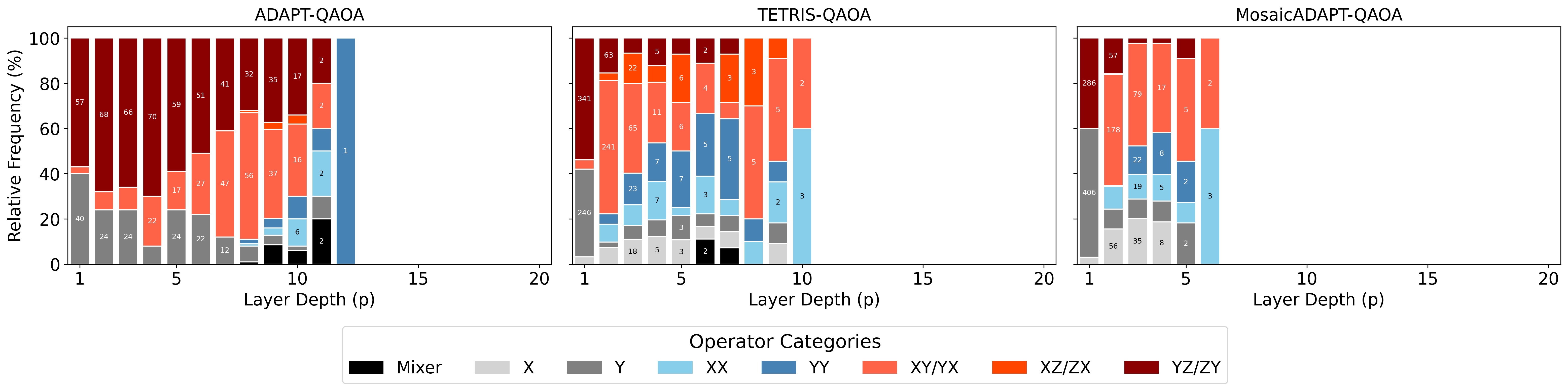
Discussion (Sec. V) explores two failure modes worth noting in light of Y1: (i) at low γ0, the optimiser pushes γ → 0 and β → ±π/4, effectively turning the circuit into a deterministic state-flip rather than a QAOA. Mosaic actually amplifies this tendency. The authors argue this is consistent with prior reports of ADAPT-QAOA stalling in excited states. (ii) At higher γ0, ADAPT and TETRIS preferentially select the standard sum-of-X mixer in early layers (essentially recovering vanilla QAOA), while Mosaic chooses single-qubit X operators — moving toward multi-angle QAOA. This is exactly the kind of layerwise/parameterised-mixer flexibility Y1 exploited via warm-started state preparation.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (iterative warm-started QAOA, MaxCut): Both papers exploit the layered/iterative structure of QAOA and care deeply about initialisation. Y1's warm-start idea is operationally orthogonal (initial state preparation) but philosophically aligned (sound initialisation determines whether iterative QAOA escapes local minima). Y1's 3-regular MaxCut benchmark is exactly the type of instance MosaicADAPT-QAOA could handle as a head-to-head comparison.
- Y2 (hard-mixer QAOA, no penalty): Mosaic's operator pool excludes Z-only operators because they commute with HC; Y2's hard mixer also restricts the operator pool to feasibility-preserving moves. Both are operator-pool-design choices that exploit the structure of the cost Hamiltonian. A natural cross-paper experiment: substitute Y2's quasi-binary hard mixer into Mosaic's pool and see whether the disjoint-tile MWIS selection automatically discovers it.
- Y3 (DGMVP QAOA, layerwise optimisation): Mosaic's BFGS reoptimisation after each layer addition is a Y3-style layerwise step. The explicit observation that MosaicADAPT-QAOA reaches AR=100% in 12 layers (vs 16 for ADAPT/TETRIS) is a direct improvement on the layerwise-QAOA baseline used in Y3.
Recommended action for Yuan
- Implement and benchmark on Y1's 3-regular MaxCut instances: the warm-start used in Y1 plus MosaicADAPT-QAOA's layered construction would be a clean composition test. Hypothesis: Y1's warm-start removes the γ0=0.01 stalling failure mode, making Mosaic strictly better than ADAPT/TETRIS in both low- and high-γ0 regimes.
- Substitute Y2's hard-mixer pool into Mosaic: the operator-pool design is the cleanest cross-paper hook. If Mosaic's MWIS selection over a Y2-style pool is well-defined (likely yes, since Y2's mixers are operator products with known supports), the experiment is straightforward.
- Cite as Y3 follow-up: Mosaic's layerwise BFGS reoptimisation directly extends Y3's layerwise-optimisation framework. Worth citing in any forward-looking version of Y3 as a state-of-the-art adaptive baseline.