Quantum Optimization Methods for the Generalized Traveling Salesman Problem
Abstract
This paper studies quantum optimization baselines for the Generalized Traveling Salesman Problem (GTSP), a clustered routing problem that naturally models variant selection and sequencing problems under discrete alternatives. We propose a novel GTSP QUBO formulation focused on maintaining feasible solutions for quantum annealing, as well as a hardware-executable gate-based pipeline utilizing the Quantum Approximate Optimization Algorithm (QAOA). We implement a constrained QAOA variant using an XY-mixer, which preserves the stepwise Hamming weight in the ideal circuit model, while feasibility with respect to the full GTSP constraints is tracked explicitly during post-processing. We compare the two quantum optimization paradigms on problem instances from GTSPLIB, an established benchmark dataset, and validate against classical state-of-the-art solvers. To mitigate current quantum hardware size limitations, we further extend a preprocessing method to reduce the node count in instance clusters, constructing new NISQ-friendly instances from reduced subsets. Across all tested instances, quantum solvers often produce competitive solution quality when tested on smaller graphs, but exhibit higher runtimes and a sharp degradation in feasibility and scalability as instance size grows.
Executive summary
Quantum optimisation baselines for the Generalised Traveling Salesman Problem (GTSP), comparing a novel feasibility-focused QUBO formulation for quantum annealing (Q-GTSP) against a constrained gate-based QAOA (C-QAOA) with one-hot-preserving XY mixer. Benchmarked on GTSPLIB instances, with a preprocessing method (extended NN2C) that reduces node count to fit current NISQ qubit budgets. The paper is honest about the failure modes: quantum solvers are competitive on small graphs but show sharp degradation in feasibility and scalability as instance size grows. The C-QAOA pipeline with XY-mixer + post-processing-based feasibility tracking is the methodologically-direct overlap with Y2.
Main contribution
Three specific contributions: (i) a GTSP QUBO encoding with quadratic penalty terms specifically designed to preserve feasible solutions under quantum annealing; (ii) a constrained QAOA pipeline (C-QAOA) using a one-hot-preserving XY mixer with feasibility-aware decoding and explicit feasible-shot rate reporting; (iii) an extended Nearest-Nodes-to-Clusters (NN2C) preprocessing method that reduces GTSP instances to NISQ-feasible sizes, enabling experiments on benchmark-derived instances of original size 14–100 vertices reduced to 3–20 nodes. The framework is consciously a baseline study — the value is in honest characterisation of the regime of scalability and feasibility.
Key theorems / results / algorithms
- QUBO formulation (Sec. IV): step×node encoding with quadratic penalty terms enforcing one-hot step assignment (each step picks exactly one node) and cluster-once constraints (each cluster visited exactly once across the tour).
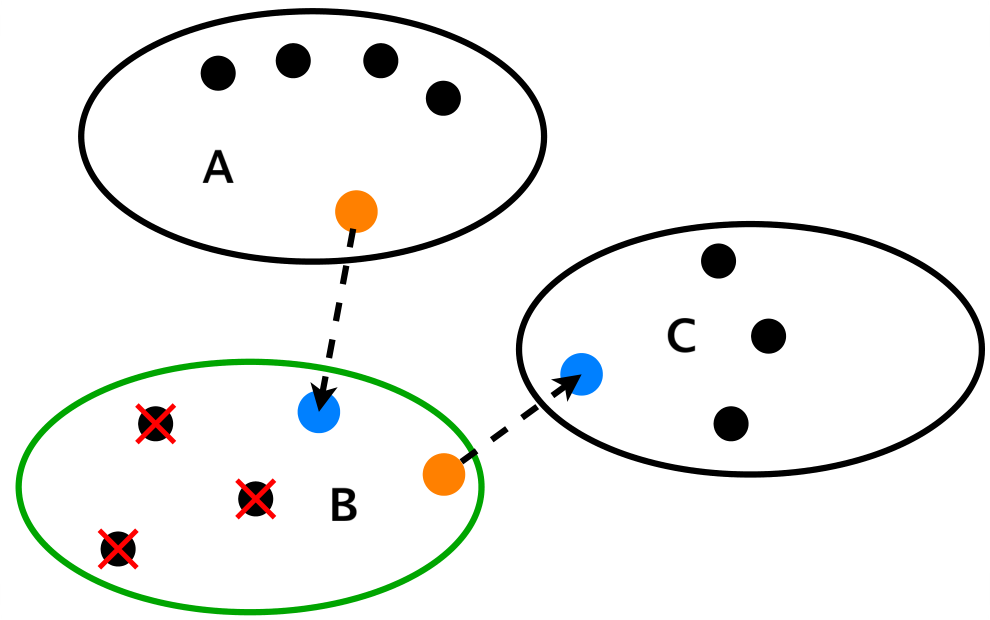
- Algorithm — extended NN2C preprocessing: for each cluster, retain the best entry node (minimises incoming distance from other clusters) and best exit node (minimises outgoing distance), with secondary tie-breaking on average reverse-direction cost. Reduces each cluster to ≤2 nodes; the reduced instance is a smaller GTSP (or a TSP if each cluster collapses to one node).
- Constrained QAOA pipeline (C-QAOA): one-hot-preserving XY mixer over each step's variables, initial state in the one-hot subspace per step, classical post-processing checks feasibility against the full GTSP constraints (one node per cluster) and reports feasible-shot rates.
- Empirical protocol: two experiment groups — Subsample (3-5 nodes, 3-20 nodes) directly drawn from GTSPLIB; Preprocess (3-5 nodes, 3-20 nodes) constructed by NN2C extended from larger GTSPLIB instances of original size 14–100 vertices.
Detailed walkthrough
The motivation (Sec. I) is that GTSP — visit exactly one representative per cluster on a min-cost tour — is industrially common (flexible manufacturing, automated storage/retrieval, robotic motion planning with multiple inverse-kinematics options) but quantum-baselined far less than vanilla TSP. Most existing quantum-routing work is either standalone TSP or quantum annealing on small instances; comparable end-to-end QAOA studies on GTSP are essentially absent, and the GTSP-specific feasibility constraint (visit-each-cluster-exactly-once) is not naturally enforced by standard penalty methods.
The QUBO formulation (Sec. IV) uses a step×node encoding: a binary variable x_{s,v} = 1 iff vertex v is visited at step s of the tour. Penalty terms enforce (i) each step picks exactly one node (one-hot), (ii) each cluster is visited exactly once across the whole tour. The novelty is the choice of penalty weights: rather than tuning to push infeasibility above the optimal cost, the paper tunes for maintaining feasibility distribution under sampling — a different optimisation target that aligns with what quantum annealers actually do.
The C-QAOA pipeline (also Sec. IV, with the gate-level circuit in Fig. qaoa_sara) uses a Hamming-weight-preserving XY mixer on each step's binary variables. This directly enforces the one-hot-per-step constraint inside the quantum circuit, but the cluster-once constraint is not preserved by the mixer, so feasibility is checked classically on each shot. The paper reports feasibility-aware metrics: feasible-shot rate (what fraction of measured bitstrings encode a valid GTSP tour) alongside approximation ratios on the feasible subset.
The NN2C extended preprocessing (Sec. IV, Fig. NN2C_visual / Algorithm 1) is a classical reduction step. For each cluster, identify the best entry and best exit node and discard the rest. This reduces a GTSPLIB instance with 100 vertices and 20 clusters to ≤40 vertices (best case ≤20 if entry and exit collapse). The reduced instance is a smaller GTSP that fits NISQ qubit budgets but no longer provably preserves the original optimum — it's a feasibility/scalability study tool, not an exact reduction.
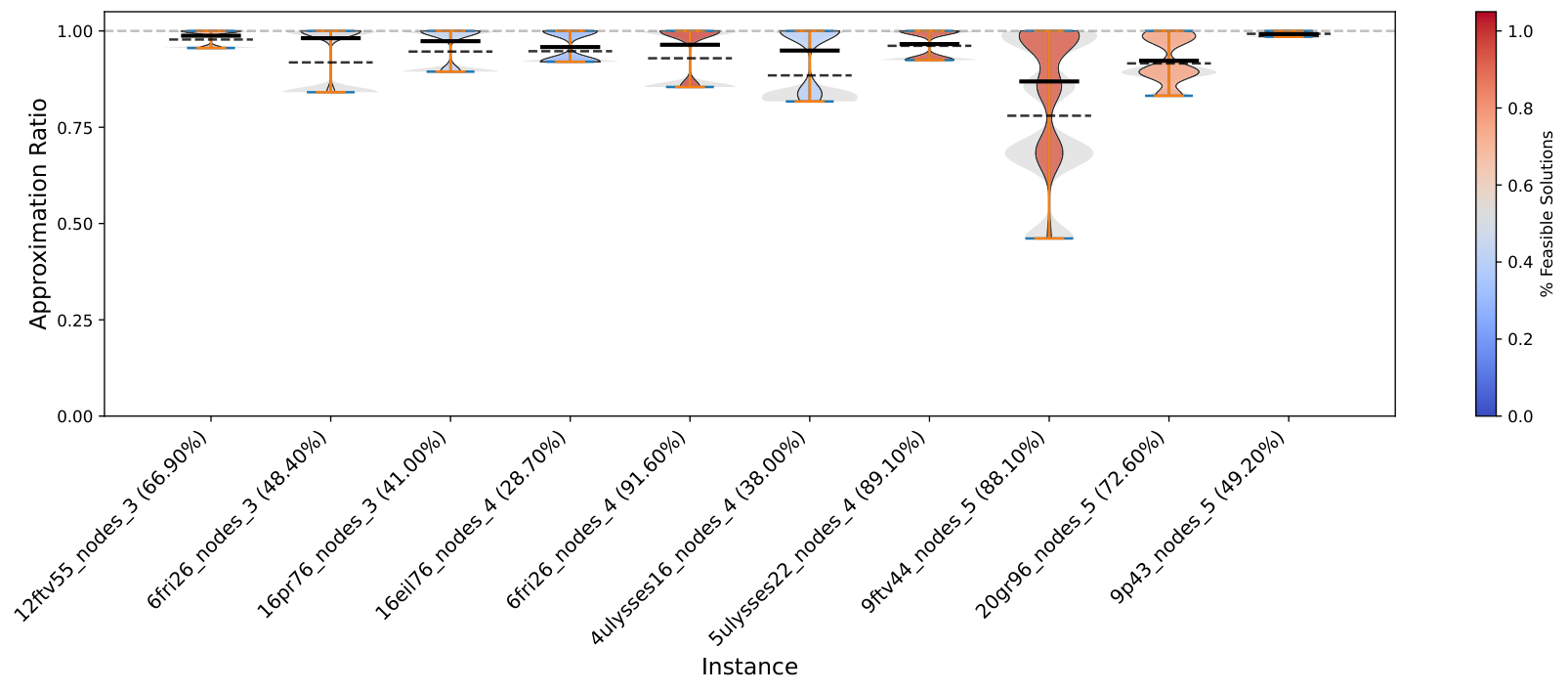
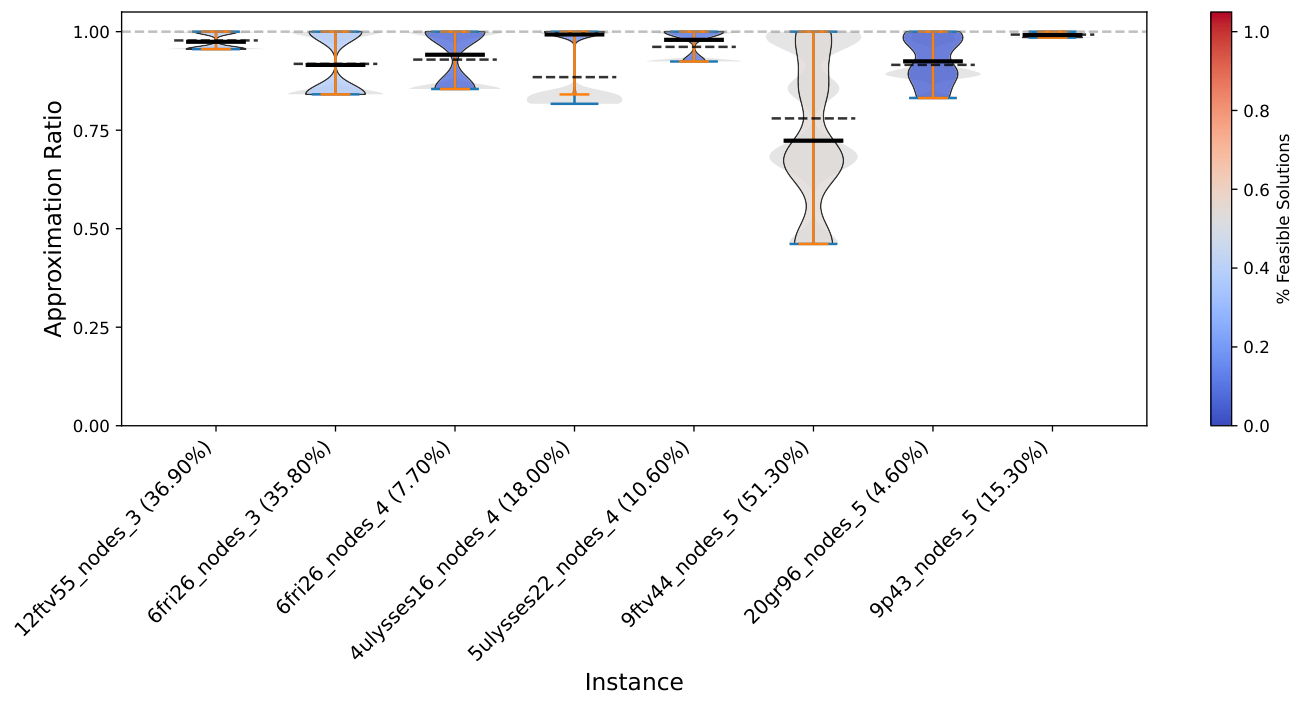
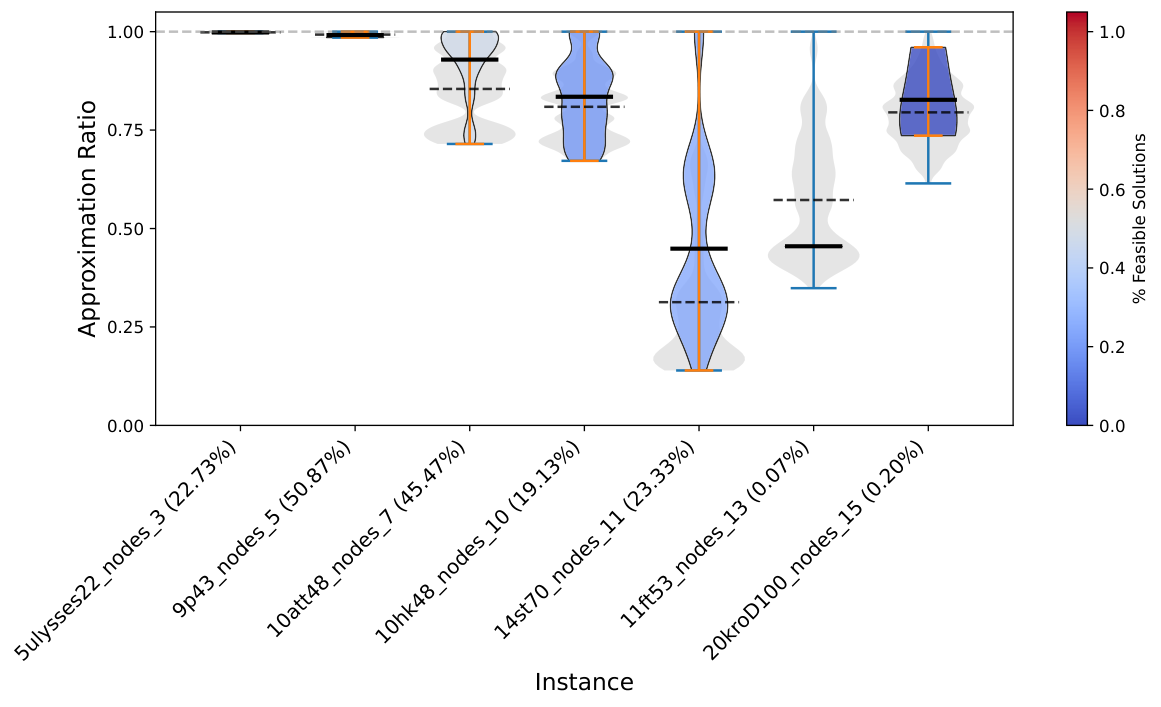
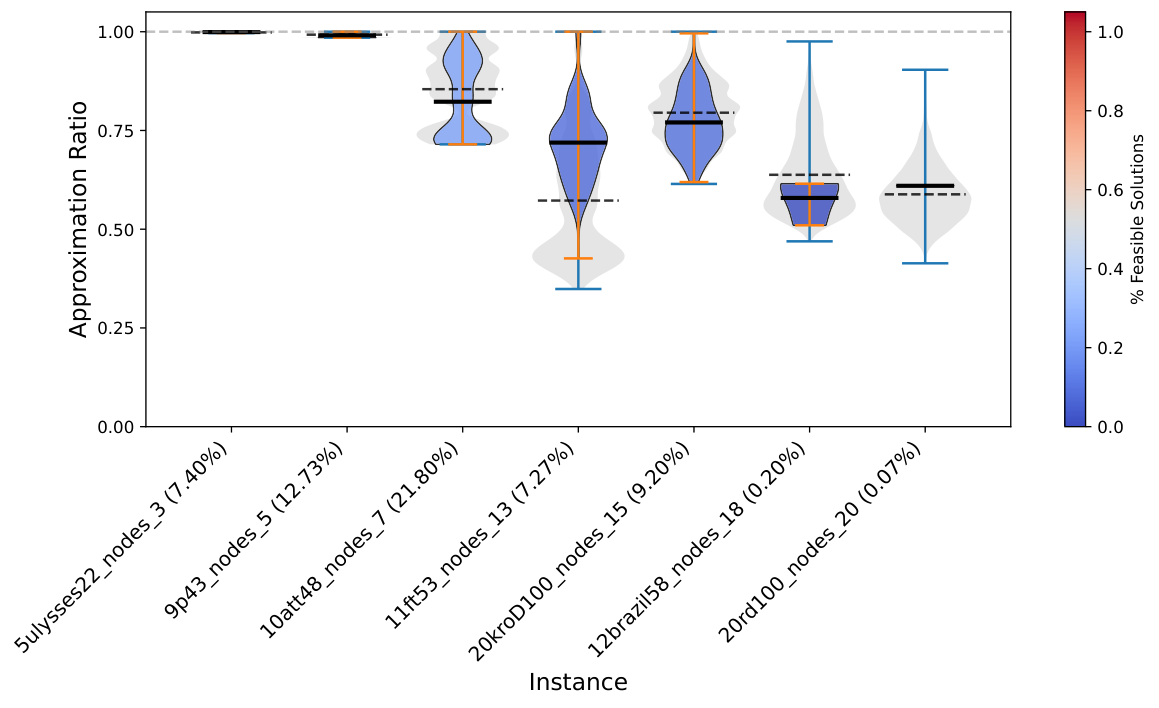
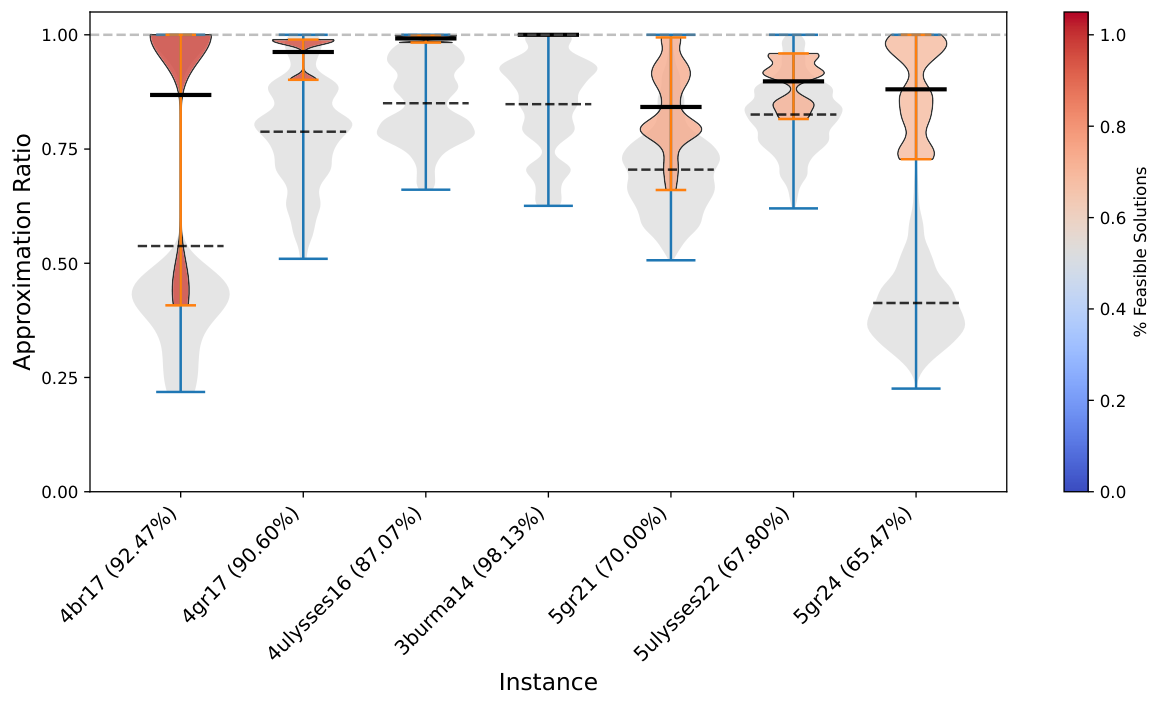
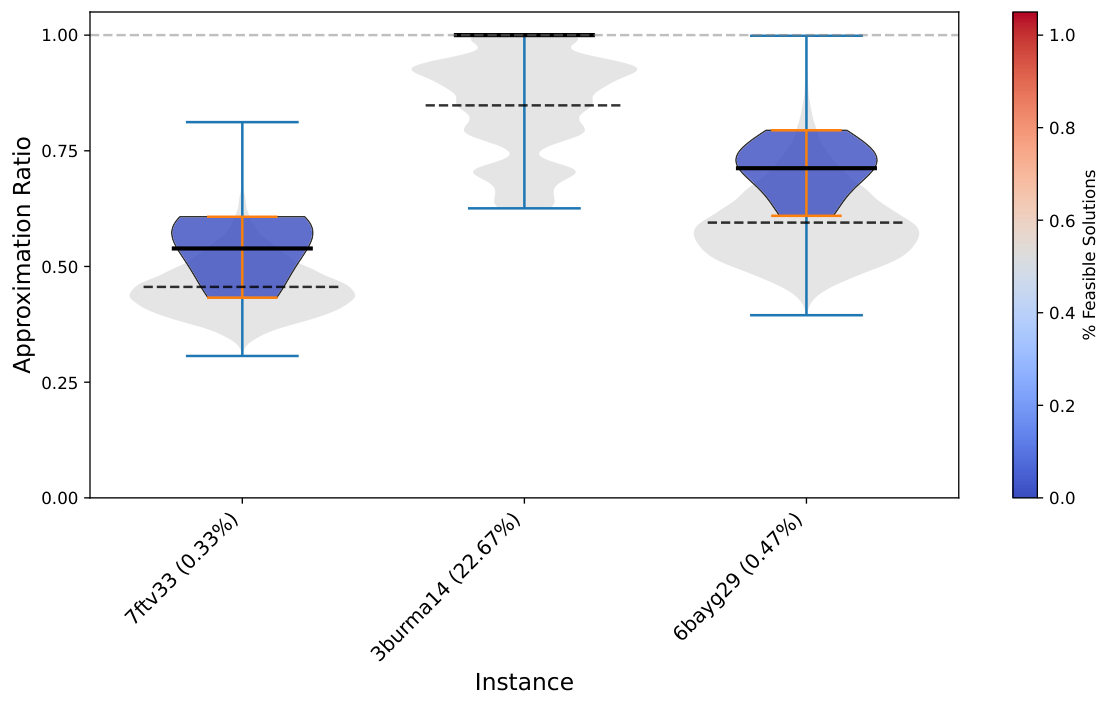
Results (Sec. VI) are reported on four experiment groups: Subsample 3-5 (≤5 nodes drawn from GTSPLIB), Subsample 3-20 (≤20 nodes drawn from GTSPLIB), Preprocess 3-5 (NN2C-reduced from original instances of size 14-24), and Preprocess 3-20 (NN2C-reduced from 14-100). Both Q-GTSP (annealing on the new QUBO) and C-QAOA (gate-based with XY mixer) are reported per instance. The violin plots (e.g. Subsample_3_20_Nodes_CQAOASolver) show the distribution of approximation ratios on feasible shots, with feasible-shot rate annotated on the instance label. The pattern: small instances (3-5 nodes) have high feasibility rates and competitive quality; medium instances (3-20 nodes) show sharp degradation in feasibility and increased runtime as size grows.
The honest-baseline framing is one of the paper's strengths. The conclusion does not over-claim quantum advantage — it identifies which instances are NISQ-tractable today, which formulations preserve feasibility under sampling, and where sampling rates / runtime / constraint violations remain open problems. For Yuan's QAOA programme, this is the kind of careful baseline against which any future portfolio-QAOA-with-cardinality work should be benchmarked.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
Y2. Direct method overlap. Y2's constrained portfolio QAOA uses a quasi-binary encoding with a hard mixer (no penalty terms) to enforce cardinality. This paper uses a one-hot encoding with an XY mixer to enforce per-step Hamming weight (also a kind of cardinality), then handles the cluster-once constraint in classical post-processing — a hybrid of the hard-mixer and post-processing approaches. The XY mixer + Dicke-style initial state machinery is shared.
Y3. Direct scope overlap. Y3 ran end-to-end QAOA on a portfolio problem and reported NISQ noise regimes carefully. This paper does the same exercise for GTSP — a different combinatorial problem but the same methodology of honest feasibility/runtime/quality reporting on real benchmarks. Useful as a non-portfolio comparator for Y3-style claims.
Y4. Light scope overlap. Y4's cardinality-constrained binary optimisation could plausibly be applied to a relaxed GTSP. The paper notes preprocessing as a key bottleneck-mitigation technique, which complements Y4's ADMM-style classical-quantum partitioning.
Recommended action for Yuan
- Read the C-QAOA pipeline section. The "XY mixer enforces partial constraint, post-processing handles the rest" hybrid is a useful intermediate between Y2's pure-mixer approach and Y3's penalty-based approach. Could be a cleaner story for a future cardinality+other-constraint problem.
- Use as a baseline. When framing future Y3-style end-to-end portfolio QAOA results, citing this paper as the GTSP analogue helps establish that careful baselining (feasibility-aware metrics, not just approximation ratio) is becoming the field norm.
- Consider NN2C-style preprocessing for portfolios. Whether DGMVP/cardinality-constrained portfolio QUBOs admit an analogous classical reduction (e.g. cluster correlated assets, take a representative) is an open question worth a quick experiment.