Graph-Conditioned Meta-Optimizer for QAOA Parameter Generation on Multiple Problem Classes
Abstract
We study parameter transferability for the Quantum Approximate Optimization Algorithm (QAOA) across multiple combinatorial optimization problem classes from a parameter generation perspective. Specifically, a meta-optimizer is trained on one problem class and deployed on another during test time. Prior work employs a Long Short-Term Memory network to emulate QAOA optimization trajectories, but the learned dynamics usually collapse to near-identical paths, limiting cross-problem transfer efficiency. In this paper, we present a problem-aware graph-conditioned meta-optimizer for QAOA that learns to generate parameter trajectories over a fixed horizon, providing strong initializations with only a few steps. The optimizer is conditioned on compact graph embeddings and trained end-to-end using differentiable feedback from the QAOA objective, avoiding the need for ground-truth angles. We evaluate across multiple graph problem classes, including MaxCut, Maximum Independent Set, Maximum Clique, and Minimum Vertex Cover. Results across a comprehensive empirical study consisting of 64 settings show that the learned optimizer can reduce optimization effort and improve performance over standard initialization, while exhibiting transferable behavior across graph families and problem types.
Executive summary
A graph-conditioned meta-optimiser for QAOA: an LSTM/RNN that emits a trajectory of QAOA angles over a fixed horizon, conditioned on a problem-aware graph embedding (UniHetCO encodes problem structure + objective + constraints in a unified heterogeneous graph). The diagnosis (Fig. 1, motif): vanilla Meta-LSTM collapses to near-identical paths across instances, hurting transferability. Conditioning on a unified embedding restores diversity. Evaluated on MaxCut, MIS, MaxClique, MVC at four QAOA depths — 16 single-problem and 48 cross-problem transfer settings — with five-shot fine-tuning across problem classes. Code released at github.com/Nyquixt/Cross-Problem-QAOA-ParamGen.
Main contribution
The work identifies a concrete failure mode of prior meta-optimisers (Verdon et al., Huang et al.) — trajectory collapse — and resolves it by injecting a graph embedding into the RNN hidden state at each rollout step. The novel ingredient is the choice of embedding: rather than the structure-only Graph2Vec, the paper uses UniHetCO (Nguyen & Safro), which encodes problem structure (red), objective (green), and constraints (blue) in a single heterogeneous graph. This produces problem-aware embeddings that transfer across problem classes (e.g., from MaxCut to MIS), enabling few-shot (5 gradient steps) cross-problem deployment.
Key theorems / results / algorithms
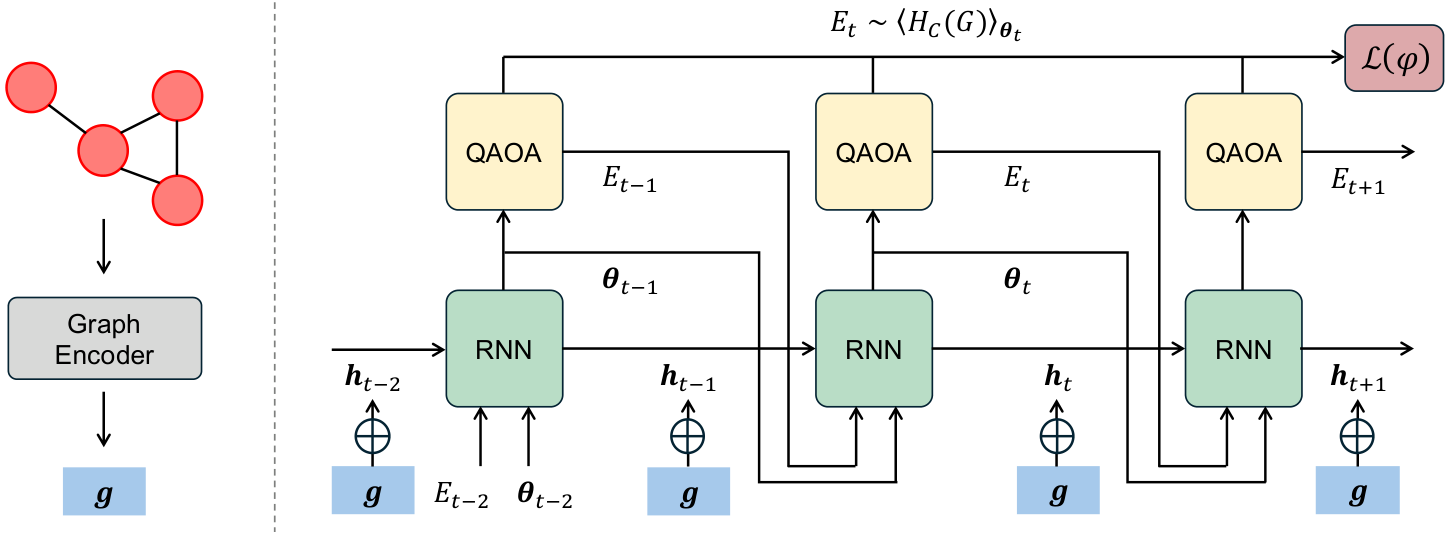
- Algorithm — Meta-optimiser training (Sec. III): at each rollout step t in {1,…,T}, the RNN hidden state h_t is concatenated with the graph embedding g and passed through an update block to emit (gamma_t, beta_t). Training uses end-to-end differentiable QAOA objective feedback (no ground-truth angles required).
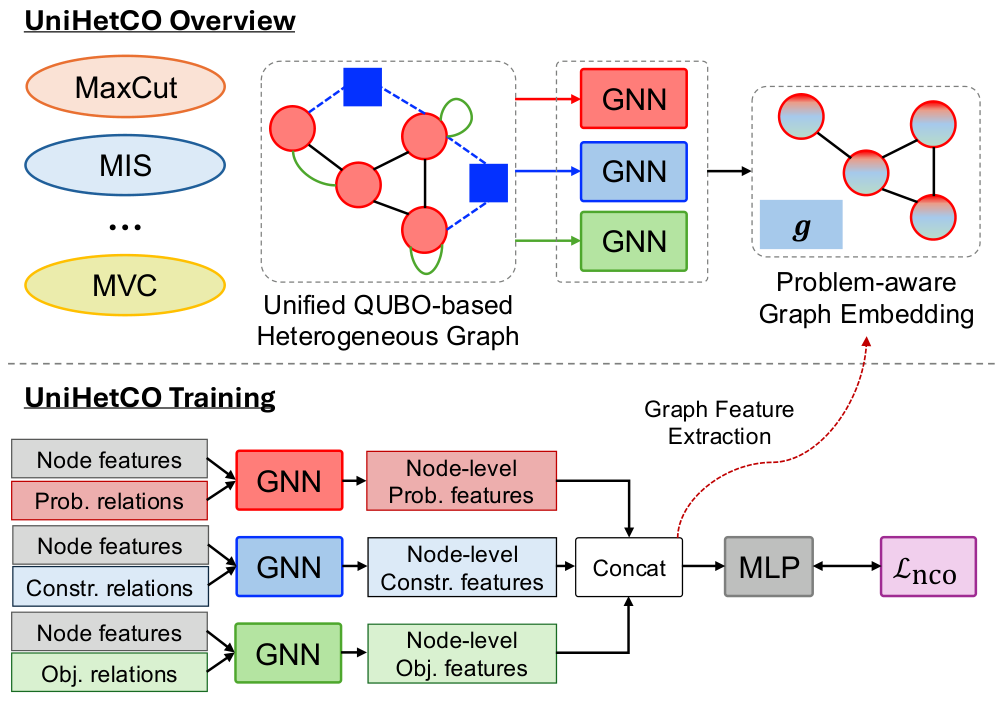
- UniHetCO graph encoder (Sec. IV.A): a heterogeneous graph G = G_prob ∪ G_obj ∪ G_constraint where G_prob captures instance structure, G_obj encodes objective coupling (off- and diagonal edges), and the constraint hypergraph encodes variable-constraint relations.
- HetGNN solver (Sec. IV.B): trained with a universal QUBO objective over the combined embedding so embeddings reflect both the structure and the problem class.
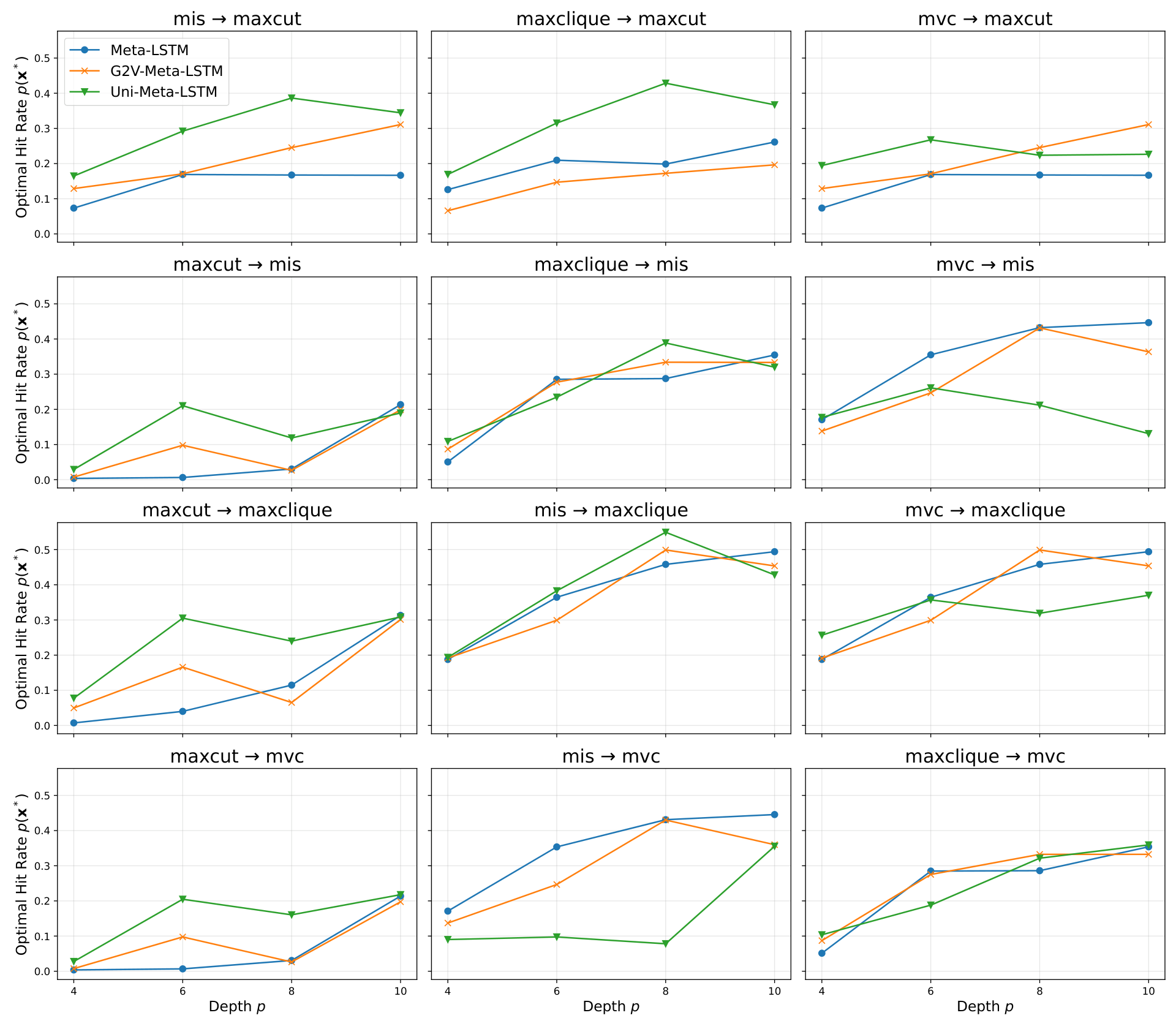
- Empirical protocol: 16 single-problem settings (4 problem classes × 4 depths p ∈ {4,6,8,10}) plus 48 cross-problem transfer settings (12 source-target pairs × 4 depths) with 5-step fine-tuning at test time.
Detailed walkthrough
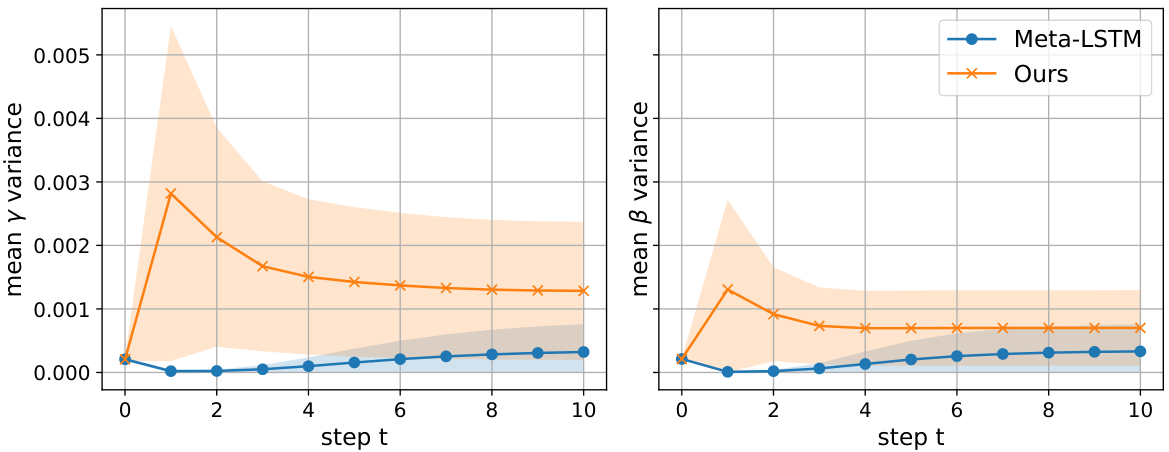
The introduction (Sec. I) opens with a memorable framing question — "Can a variational quantum optimiser trained on yesterday's problems produce high-quality parameters for tomorrow's, possibly unexpected, optimisation task?" — and identifies the gap: most QAOA parameter-transferability studies stay within a single problem class. The motivating empirical observation (Fig. 1, motif) is that the vanilla Meta-LSTM produces parameter trajectories whose mean squared deviation from the per-instance mean is small, i.e., it has effectively collapsed to one "average best" trajectory. This kills the optimiser's ability to adapt and limits cross-problem transfer.
The architecture (Sec. III, Fig. title) is a two-stage pipeline. Stage 1 (left): a graph encoder maps the instance G to a fixed-dimension vector g. Stage 2 (right): a meta-optimiser RNN emits a trajectory of QAOA parameters, with g injected into the hidden state at each step so generation is conditioned on instance-specific features.
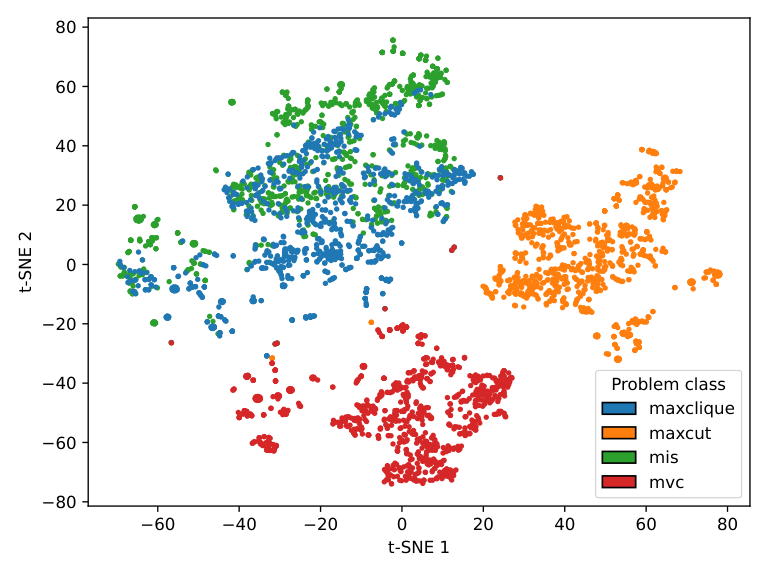
The graph encoder is the heart of the contribution. UniHetCO (Sec. IV, Fig. unihetco) augments the original graph by adding objective-coupling edges and constraint nodes/edges, producing a heterogeneous graph that simultaneously encodes the instance topology, the objective function, and the constraint structure. A heterogeneous GNN trained on a universal QUBO objective (Sec. IV.C) then learns embeddings that cluster by problem class but preserve cross-class similarity — the t-SNE visualisation (Fig. tsne) shows MIS and MaxClique embeddings interleaving in a way that reflects their actual problem-theoretic similarity, while MaxCut and MVC sit in well-separated clusters.
Single-problem results (Sec. V, Tables in experiment.tex) show the graph-conditioned meta-optimiser dominating Vanilla QAOA on MaxCut, MIS, MaxClique, and MVC across all four depths, with the asterisk-marked results indicating "better than Vanilla QAOA" being the modal outcome. The cross-problem transfer table (Fig. cross-problem) reports optimal hit rate p(x*) on the 48 transfer settings — training on one problem class and fine-tuning with 5 gradient steps on another — showing positive transfer across most problem pairs.
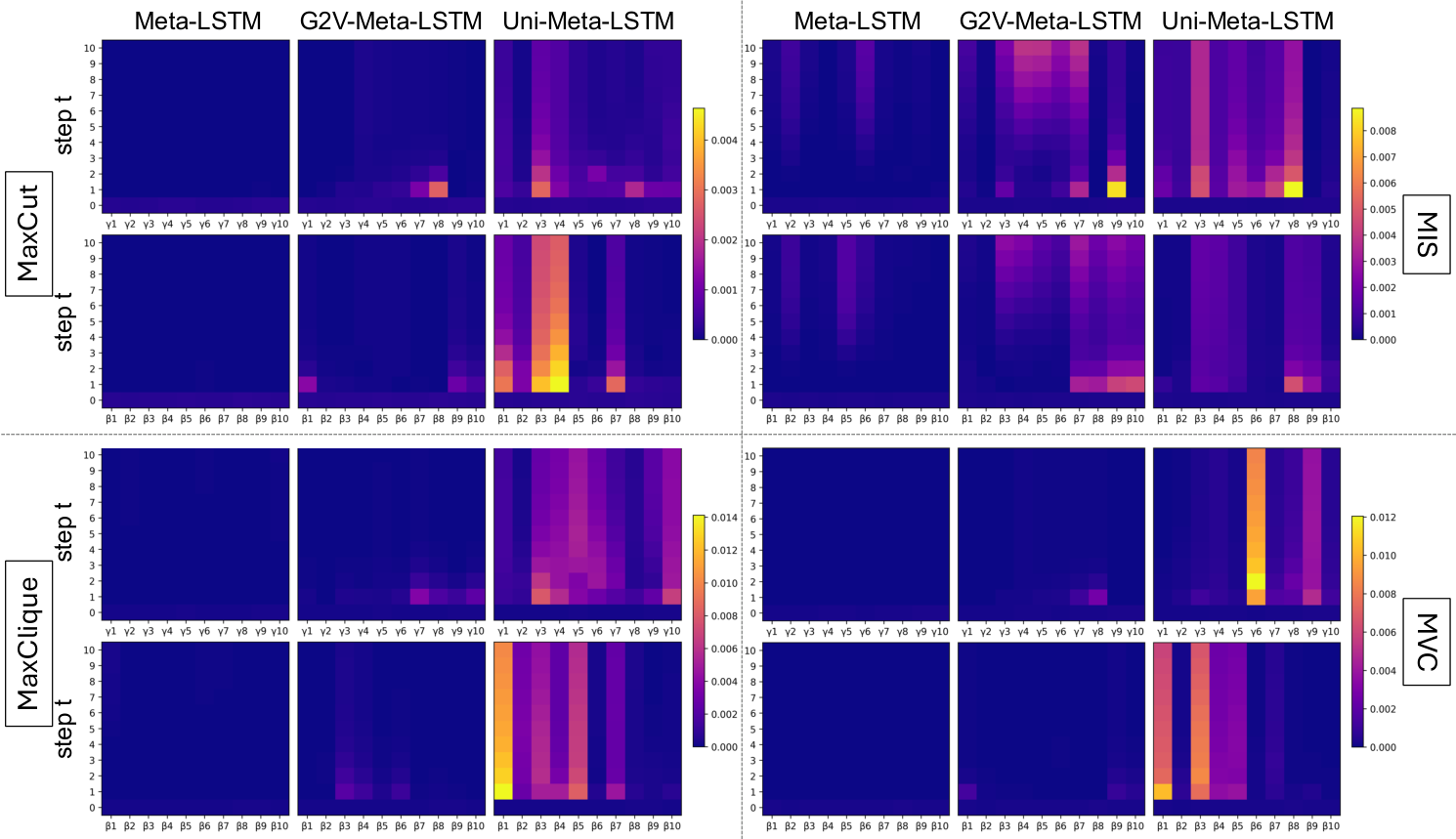
The diversity figure (Fig. variance) measures the variance of generated parameter trajectories across 100 random graph instances for Meta-LSTM, G2V-Meta-LSTM (Graph2Vec conditioning), and Uni-Meta-LSTM (UniHetCO conditioning). The progression Meta-LSTM → G2V → UniHetCO shows monotonically increasing trajectory diversity, validating the diagnosis: better embedding → richer per-instance trajectories → better transfer.
The takeaway for QAOA practitioners: structural similarity (Graph2Vec) is not enough for cross-problem transfer — the embedding has to encode the problem semantics (objective + constraints) too. Once it does, the meta-optimiser amortises across problem classes, making the QAOA parameter-search problem dramatically cheaper at deployment time.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
Y1. Direct method overlap. Y1's iterative quantum warm-start prepares a high-quality seed via an earlier QAOA layer; this paper produces a high-quality angle trajectory via a learned meta-optimiser. Both seek to amortise the cost of finding good QAOA parameters; Y1 amortises across iterations, this paper amortises across instances and problem classes.
Y3. Direct method overlap. Y3 found that layerwise optimisation gave the most robust schedule for QAOA on the DGMVP portfolio. This paper provides a learned alternative — a meta-optimiser trajectory — which could plausibly be competitive with or complementary to layerwise schemes for portfolio instances.
Y2. Light scope overlap. Y2 also handles a structured constrained problem (portfolio with cardinality), where a custom mixer enforces feasibility. The UniHetCO embedding's explicit handling of constraints makes it a natural fit for Y2-style constrained portfolio QAOA — the embedding can represent the cardinality constraint as constraint-node hyperedges.
Recommended action for Yuan
- Read deeper, especially Sec. IV. The UniHetCO embedding is a more principled approach to encoding QAOA instances than what Y3 used and could simplify cross-instance transfer for portfolio QAOA.
- Try the released code. github.com/Nyquixt/Cross-Problem-QAOA-ParamGen — quick to clone and run on Y2/Y3 portfolio instances; positive results would directly motivate a follow-up paper.
- Adapt UniHetCO to portfolio instances. Encode the DGMVP cardinality constraint as a hyperedge over the asset variables and train UniHetCO across asset universes. This could turn Y3's instance-specific QAOA pipeline into a pre-trained model that generalises across portfolios.