Experimental Workflows for Combinatorial Optimization: Towards Quantum Advantage
Abstract
Demonstrating quantum advantage for combinatorial optimization requires more than standalone algorithmic results; it calls for end-to-end case studies that integrate problem modelling, quantum execution, and classical refinement into practical workflows. This paper presents a sandbox platform for experimenting with hybrid quantum-classical workflows in graph optimization, enabling the systematic study of end-to-end optimization pipelines. Using our platform, we investigate three classically intractable and mutually reducible graph problems—Minimum Vertex Cover, Maximum Independent Set, and Maximum Clique—by transforming them into an unconstrained problem and solving the resulting instances with QAOA on IBM platforms. Our workflow combines classical pre-processing to reduce instance size, quantum optimization on the reduced problem, and classical postprocessing to map quantum outputs to high-quality feasible solutions, thereby avoiding direct constraint encoding in the quantum circuit. We evaluate the approach on synthetic graphs, benchmark instances, and real-world networks, and report hardware experiments on IBM Quantum System One at PINQ² in Bromont, Quebec, powered by IBM's 156-qubit Heron r2 processor on graphs up to 128 vertices, with circuits involving up to 128 qubits and 13,555 two-qubit gates.
Executive summary
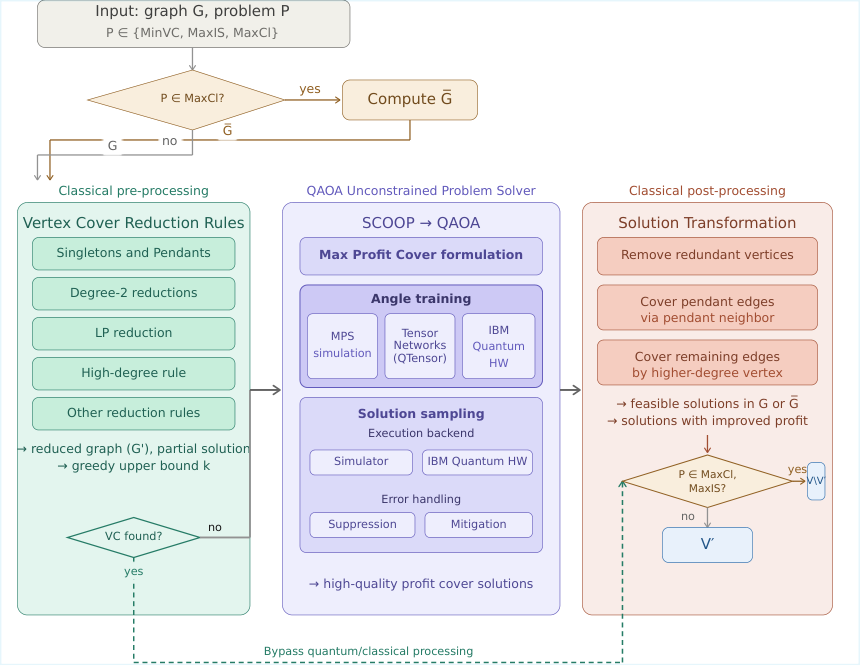
A modular three-stage "sandbox" platform for end-to-end QAOA on constrained graph optimisation: (1) classical pre-processing via vertex-cover reduction rules; (2) QAOA on the unconstrained Maximum Profit Cover (MaxPC) reformulation of MinVC/MaxIS/MaxCl; (3) classical post-processing that recovers feasible solutions. Hardware results from IBM's 156-qubit Heron r2 at PINQ² Bromont on graphs up to 128 vertices and circuits with up to 13,555 two-qubit gates. The architectural argument is that constraint feasibility should be offloaded to classical post-processing rather than encoded as penalty terms in the quantum circuit — directly side-stepping the penalty-tuning problem that hampers Y3-style end-to-end portfolio studies.
Main contribution
The paper's thesis is that QAOA's notorious penalty-tuning problem for constrained optimisation can be avoided entirely by reformulating constrained problems into transformationally equivalent unconstrained problems via the SCOOP/MaxPC framework, then handling feasibility classically in post-processing. Combined with parameterised-complexity reduction rules in pre-processing, this allows the QAOA stage to operate on a smaller, penalty-free instance. The platform demonstrates this end-to-end on real IBM Heron r2 hardware on graphs up to 128 vertices, providing a concrete template for how to assemble a hybrid quantum-classical pipeline whose components can be benchmarked individually.
Key theorems / results / algorithms
- Theorem 1 (Background): equivalence of MinVC/MaxIS/MaxCl with their unconstrained MaxPC/MaxPI/MaxPCl twins under the SCOOP framework — solving the unconstrained twin yields an exact feasible solution for the constrained original.
- Algorithm — three-stage pipeline: (a) Classical pre-processing applies vertex-cover reduction rules iteratively until none fires, identifying V_safe; (b) QAOA on MaxPC for the reduced graph G' using the SCOOP encoding (no penalty terms); (c) Classical post-processing combines reduction rules with a folklore greedy step (pick max-uncovered-degree vertex) to recover a feasible solution.
- Hardware protocol: ibm_quebec (IBM Heron r2, 156 superconducting qubits) experiments on synthetic Erdős-Rényi graphs with edge probability {0.1, 0.3, 0.5, 0.8} and 3-regular graphs from 4 to 100 vertices. QOBLIB benchmark instances up to 156 vertices. Network Repository real-world graphs up to 781 vertices end-to-end through the full pipeline.
Detailed walkthrough
The framework (Sec. II) frames the work as a sandbox platform with three exchangeable sandboxes — pre-processing, QAOA, post-processing — so that any one stage can be varied while the others are held fixed. This separation of concerns is crucial for benchmarking: it makes performance differences directly attributable to a single stage. The paper distinguishes "structural" hybridisation (QAOA bracketed by classical algorithms) from "parametric" hybridisation (classical optimisation of QAOA angles, the standard variational loop).
Section III's key insight is the QAOA constrained-optimisation challenge: penalty methods impose binary feasibility (either feasible or not), but in practice some infeasible solutions are close to feasible ones and recoverable, while some feasible solutions are of poor objective quality. A penalty-only formulation cannot exploit this. The SCOOP/MaxPC reformulation removes this binary cliff: the unconstrained problem assigns a profit to each candidate solution, and the post-processing step decides what to do with infeasible candidates by case (apply reduction rule? apply greedy correction?).
The methodology (Sec. IV, with the IBM Heron r2 details) walks through the pipeline on graphs up to 128 vertices. The classical pre-processing alone resolves a large fraction of vertices on real-world application graphs — for example, instances with hundreds of vertices may reduce to tens before any quantum work happens. For synthetic graphs the pre-processing step is intentionally omitted to study QAOA scaling on graphs whose full structure is preserved. Hardware-specific transpilation produces circuits with up to 13,555 two-qubit gates on the largest instances.
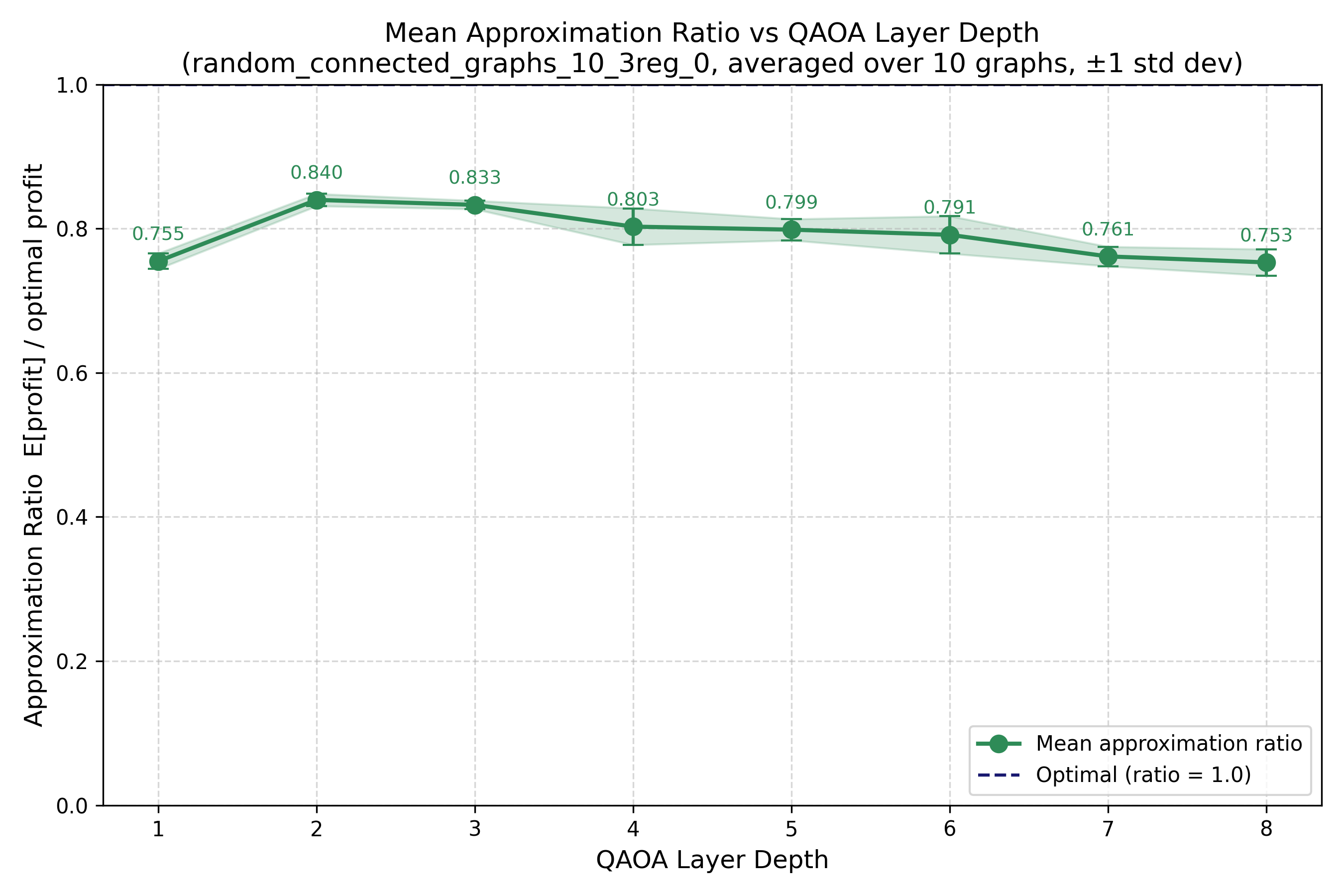
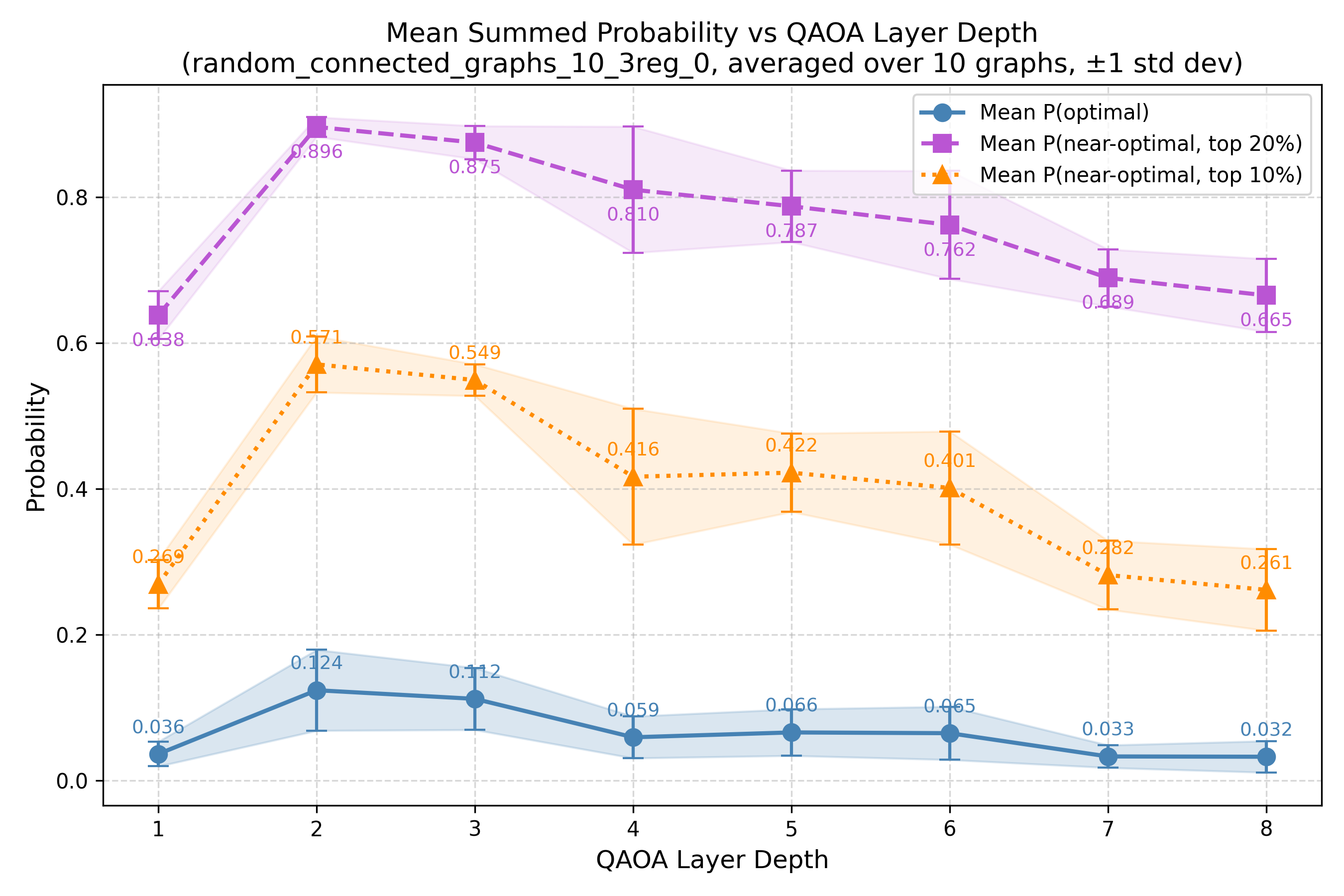
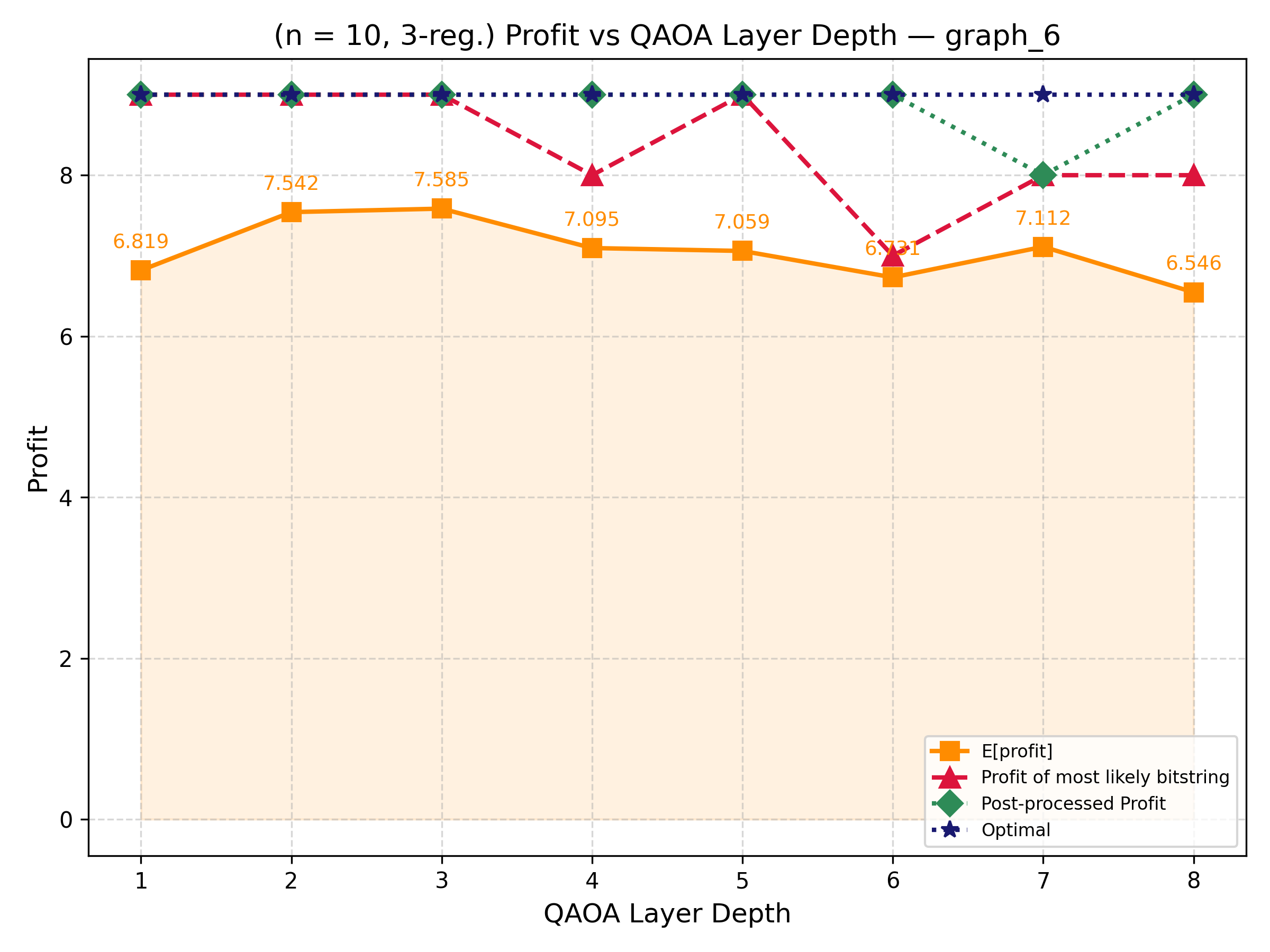
The results (Sec. V–VI) report: training and hardware performance on synthetic graphs up to 100 vertices on the 156-qubit Heron r2; QOBLIB benchmark instances up to 156 vertices; and end-to-end runs on real-world networks up to 781 vertices with the full pre+QAOA+post pipeline. The reported metrics are explicitly distributional — probability mass on optimal vs. near-optimal solutions, approximation ratios, expectation values — because quantum sampling produces a distribution rather than a single answer, and a multi-objective practitioner benefits from a basket of high-quality candidates.
The paper does not claim quantum advantage. Its contribution is methodological: a benchmarkable end-to-end pipeline, with hardware-grounded numbers on a current 156-qubit machine, and a strong argument that future quantum-advantage claims for constrained optimisation should be assessed through this kind of sandbox infrastructure rather than from isolated algorithmic numbers. This framing aligns directly with Yuan's Y3 conclusion that "thermal relaxation precludes quantum advantage" for current-noise QAOA portfolio runs — the present paper is the methodological complement.
Practitioner-oriented guidance (Contribution 4 in the introduction) explains how to interpret QAOA outputs as distributions, including key performance indicators (KPIs) for distinguishing useful runs from noise.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
Y2. Direct method overlap. Y2's quasi-binary encoding + hard mixer for portfolio QAOA explicitly avoids penalty terms; this paper avoids penalty terms via a different route (problem reformulation + classical post-processing). Both share the conviction that penalty terms are the wrong abstraction for constrained QAOA.
Y3. Direct conclusion overlap. Y3 reports thermal relaxation precludes quantum advantage for current-noise QAOA on DGMVP, and recommends a careful end-to-end pipeline analysis. This paper builds exactly that kind of pipeline (sandbox platform) and reports honest end-to-end numbers on IBM Heron r2 — a near-perfect methodological complement to Y3.
Y4. Scope overlap. Both target constrained binary optimisation. Y4's Grover+ADMM has provable speedup guarantees on the cardinality-constrained class; this paper takes the experimental NISQ route on graph-constrained problems. The two could form a side-by-side comparison.
Recommended action for Yuan
- Read deeper, especially Sec. III–IV. The MaxPC/SCOOP reformulation is a cleaner alternative to the penalty-tuning machinery that Y2 and Y3 work around. Worth knowing in detail.
- Cite in next end-to-end portfolio paper. When the next iteration of Y3-style work argues for a particular pipeline structure, this paper is the textbook example of "do all three stages, benchmark each".
- Adapt the sandbox idea. The three-stage modular benchmarking idea is directly transferable to the DGMVP and cardinality-constrained portfolio settings of Y2/Y3 — could become a methodology section in a follow-up paper.
- Email authors / discuss with PINQ² Bromont. They have access to a 156-qubit Heron r2 and have already run circuits with thousands of two-qubit gates. Direct collaboration on portfolio benchmarks could be high-value.