Qubit-Scalable CVRP via Lagrangian Knapsack Decomposition and Noise-Aware Quantum Execution
Abstract
Hybrid quantum optimization for vehicle routing faces a practical bottleneck: (i) direct QUBO encodings of CVRP quickly exceed near-term qubit and gate budgets; and (ii) near-term quantum evaluations are expensive, noise-limited, and highly sensitive to backend and circuit configuration. We address this gap with an end-to-end decomposition-based pipeline that converts CVRP into a sequence of bounded-width quantum subproblems and treats quantum execution itself as a decision problem within the optimization loop. Starting from a Fisher–Jaikumar assignment linearization, we apply Lagrangian relaxation to dualize customer-assignment couplers, yielding independent, per-vehicle knapsack subproblems that admit QUBO/Ising evaluation. To replace brittle subgradient tuning in the outer loop, we learn a multiplier-update controller using a two-stage protocol (expert-guided pretraining followed by reinforcement learning fine-tuning) with rewards defined by execution-realized progress and route reconstruction. Furthermore, we introduce constrained contextual bandit as a hardware-aware execution layer that selects backend and circuit configuration with feasibility screening, thereby enabling safe adaptation across heterogeneous noisy resources and parallel multi-QPU scheduling. Computational results on multiple CVRPLIB families demonstrate that (i) the decomposition yields stable bounded-width subproblems across instance sizes, (ii) learned multiplier updates improve end-to-end routing quality relative to classical subgradient control under matched budgets, and (iii) hardware-aware configuration on real devices reduces median optimality gaps compared with static hardware execution, improving the utility of each costly quantum evaluation. Our goal is not to claim quantum advantage, but together, these components provide a practical end-to-end framework for scaling hybrid quantum CVRP optimization through OR decomposition, AI (learning-augmented dual control), and adaptive hardware-aware execution.
Executive summary
This paper builds an end-to-end hybrid pipeline for the capacitated vehicle routing problem (CVRP) on near-term hardware. The core trick is replacing the monolithic CVRP QUBO with a Fisher–Jaikumar linearization plus Lagrangian relaxation that produces a stream of per-vehicle knapsack QUBO subproblems whose logical width is bounded by the candidate set rather than the full customer count. Two learning layers sit on top: a PPO-fine-tuned multiplier-update controller replaces hand-tuned subgradient ascent, and a constrained contextual bandit selects backend, depth, qubit-placement, and entanglement pattern subject to gate-budget feasibility. For Yuan, the relevance is direct: the encoding-efficiency, hard-feasibility, and hybrid classical–quantum-decomposition themes line up squarely with Y2 (quasi-binary portfolio QAOA), Y3 (noise-aware QAOA portfolio), and Y4 (ADMM cardinality-constrained BO).
Main contribution
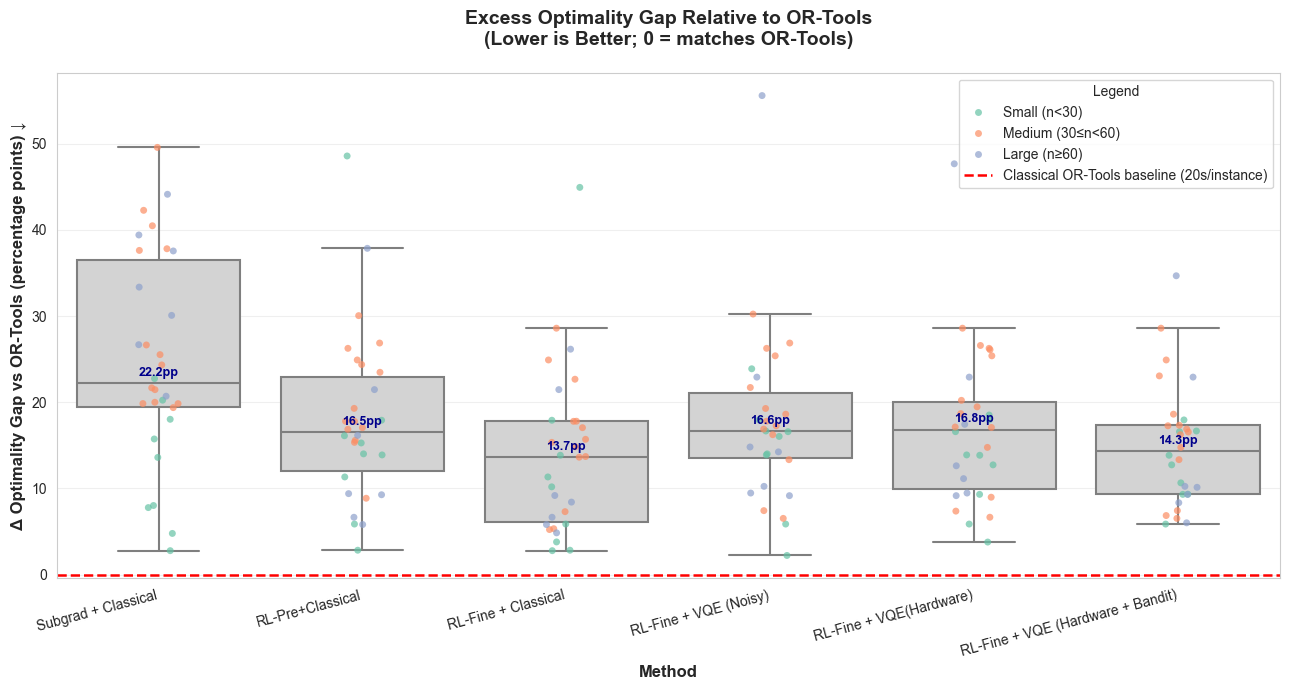
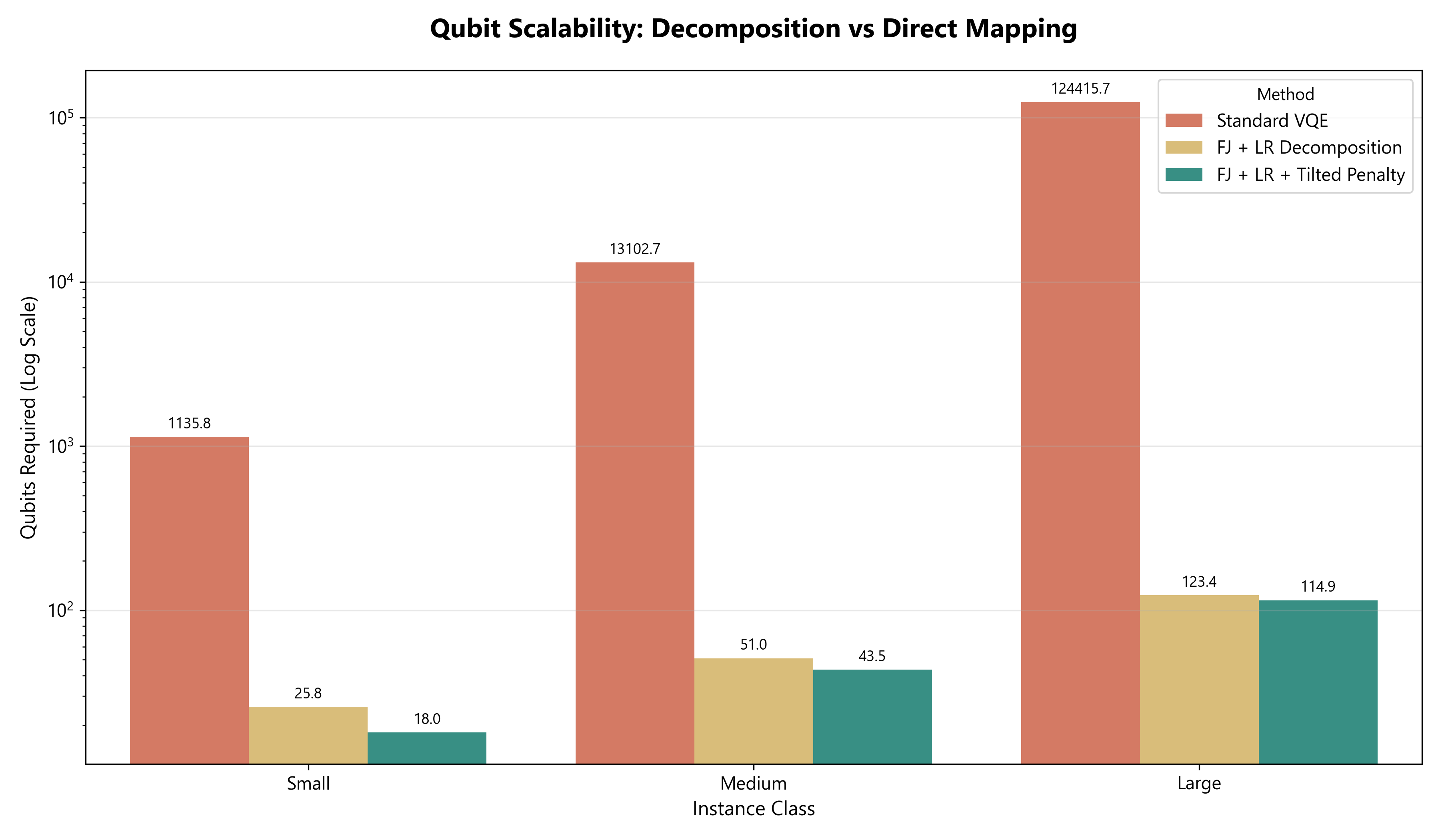
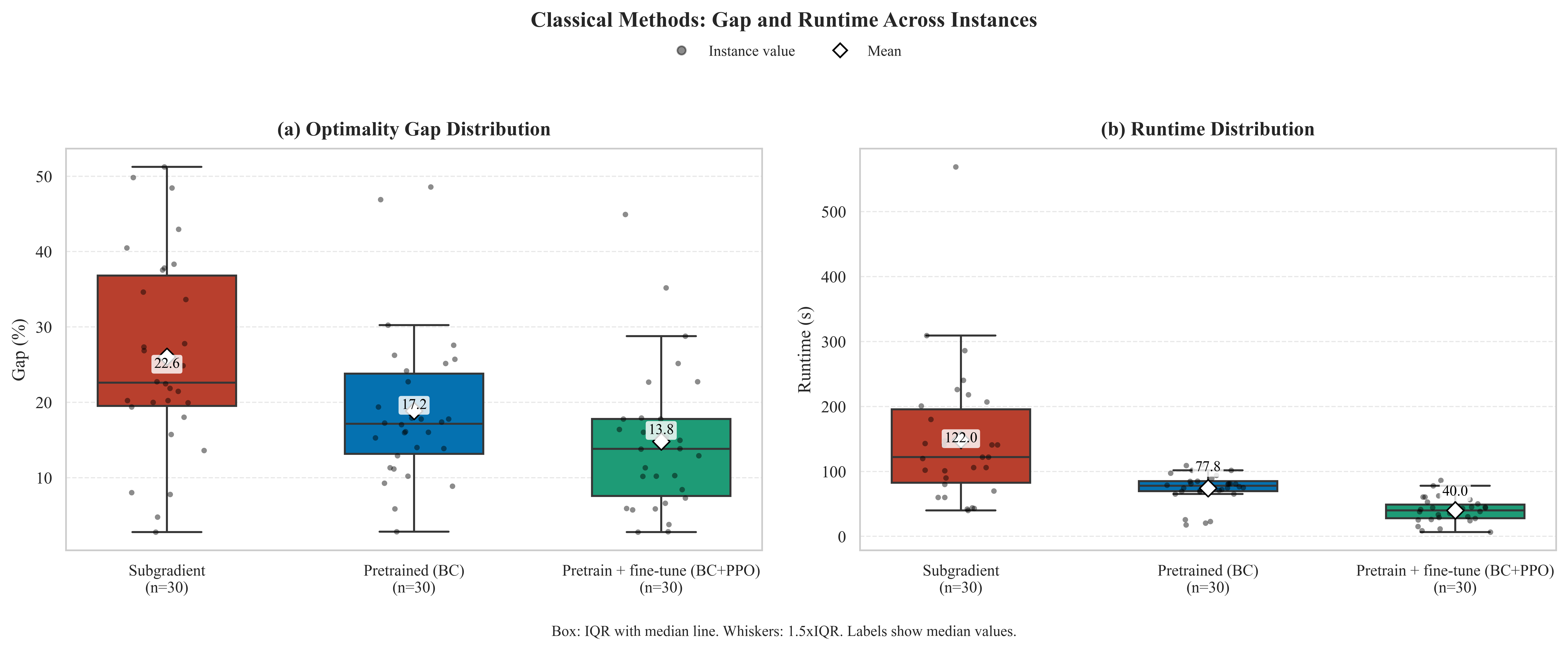
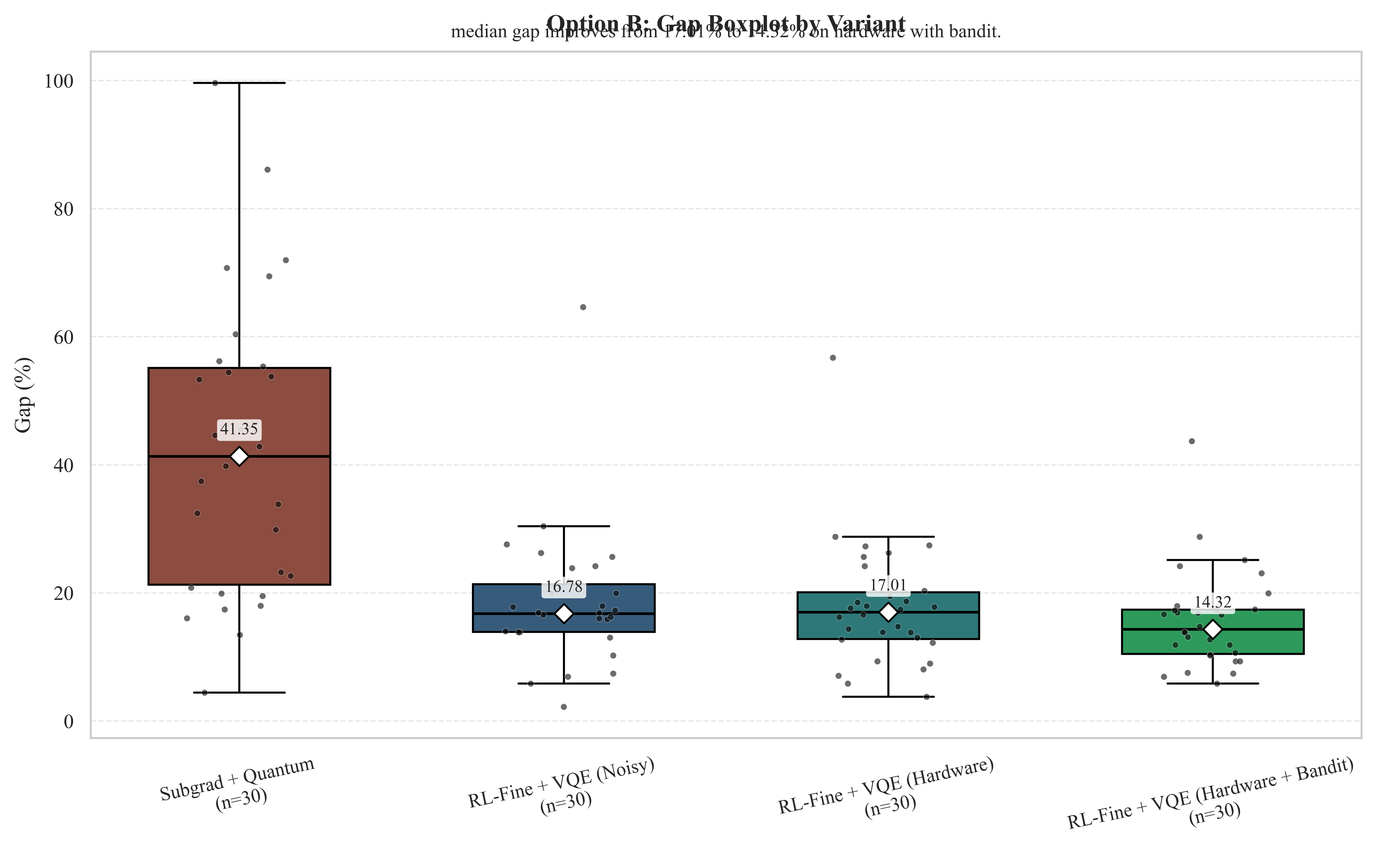
The paper contributes a four-piece system. (1) An OR decomposition that converts CVRP via Fisher–Jaikumar GAP linearization, then dualizes the customer-assignment couplers via Lagrangian relaxation, yielding K independent 0–1 knapsack subproblems with bounded width. (2) A novel tilted quadratic capacity penalty (Eq. 4) that biases towards a controlled headroom band W ∈ [Q−s, Q] instead of using slack variables — saving qubits and improving feasibility yield under sampling noise. (3) A two-stage learned multiplier controller (expert behavior cloning + PPO fine-tuning) with execution-realized rewards. (4) A constrained contextual bandit (LinUCB) for hardware-aware backend/configuration selection, with explicit gate-budget feasibility screening. Empirically, on 30 CVRPLIB instances, learned multiplier control alone cuts mean end-to-end gap from 26.0% (subgradient) to 14.8%, and hardware-aware execution further trims the bandit-enabled hardware setting from 17.8% (RL+HW) to 15.7% mean gap.
Key algorithms / formulations
- Per-vehicle knapsack subproblem (Eq. 3): for fixed multipliers λ, minimize
Σ ã_ik(λ) y_iks.t.Σ d_i y_ik ≤ Q, with adjusted costsã_ik(λ) = a_ik − λ_i. Decomposes across vehicles. - Tilted quadratic penalty (Eq. 4): energy
E = Σ ã_i y_i + ρ(r(y)² + s·r(y))withr(y) = Σ d_i y_i − Q. Optimal atr* = −s/2i.e. an intended loadW* = Q − s/2, encouraging a feasibility band. - Two-stage multiplier controller: expert-guided behavior cloning (subgradient demonstrations) followed by PPO fine-tuning with curriculum-shaped reward combining dense proxy signals and periodic end-to-end routing feedback.
- Contextual bandit (Section 5): LinUCB over a discrete action space (qubit subset × entanglement pattern × depth) conditioned on backend descriptors and subproblem width; rejection of top-ranked arm if estimated gate count
Ĝ > G_max, with fallback to best feasible alternative. - Primal recovery: decode → repair → route reconstruction (Sections 4.1–4.3); uses CVaR-style best-of-samples selection.
Detailed walkthrough
The paper opens by emphasizing two NISQ pain points (Section 1): direct QUBO encodings of CVRP scale superlinearly because assignment and sequencing decisions are coupled in a monolithic formulation, and execution quality varies sharply with backend/configuration. The proposed system addresses both layers separately.
Decomposition (Section 3). The pipeline begins with the Fisher–Jaikumar linearization (Section 3.2) which fixes a per-arc cost approximation a_ik for assigning customer i to vehicle k, separating assignment from routing. Section 3.3 then takes the GAP and dualizes the customer-coverage constraints Σ_k y_ik = 1 via Lagrange multipliers λ_i. This is the key move: the Lagrangian is separable across vehicles, and each per-vehicle subproblem becomes a 0–1 knapsack of width equal to the candidate set considered for that vehicle (Section 3.4). A tilted quadratic penalty (Eq. 4) replaces slack-variable encodings of the capacity inequality, eliminating ⌈log₂ Q⌉ auxiliary qubits per vehicle and yielding a further width reduction beyond decomposition alone. The authors justify the tilt by noting that under sampling noise, near-feasible solutions that "hug" the boundary frequently flip to slight overloads; biasing toward a band below capacity raises feasibility yield in decoding (Appendix A micro-benchmark on noisy simulator).
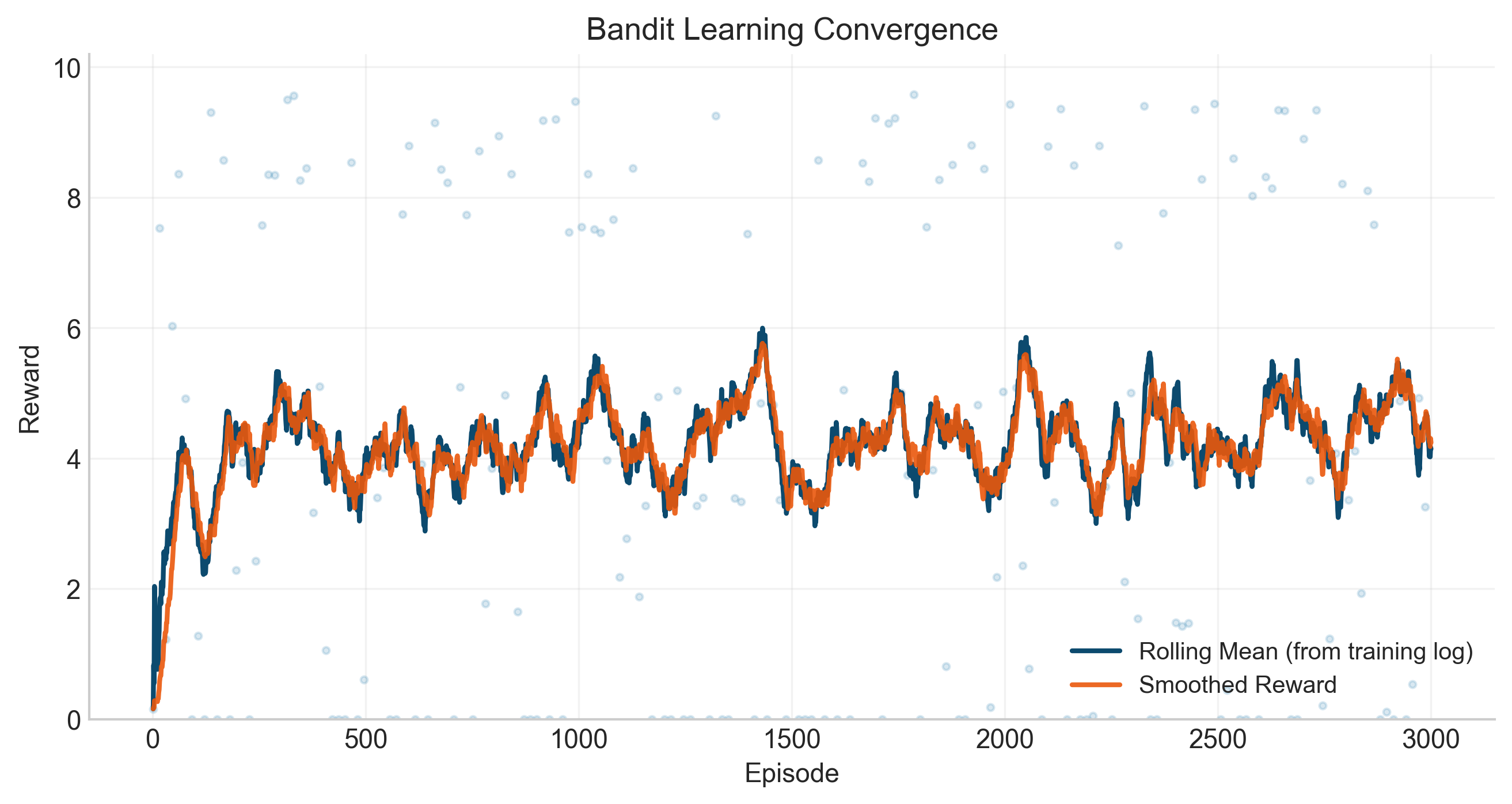
Learned multiplier control (Section 5). Standard subgradient updates on λ are stepsize-sensitive and oscillate when subproblem solutions are noisy. The authors formulate multiplier updates as a controlled MDP whose state aggregates per-customer assignment statistics, dual progress signals, and instance descriptors. Stage 1 is behavior cloning of an expert subgradient demonstrator with curriculum-difficulty regularization; Stage 2 is PPO fine-tuning with reward shaped by dense per-iteration progress signals plus periodic end-to-end routing reward (after decoding/repair). The ablation (Section 7.3, Table I) is striking: subgradient → 26.0% mean gap, pretraining → 18.9%, pretraining + PPO → 14.8%, with mean runtime dropping from 148.6 s to 40.1 s. These numbers are before any quantum execution noise enters the picture, so the improvements come from outer-loop control quality rather than execution-side fidelity.
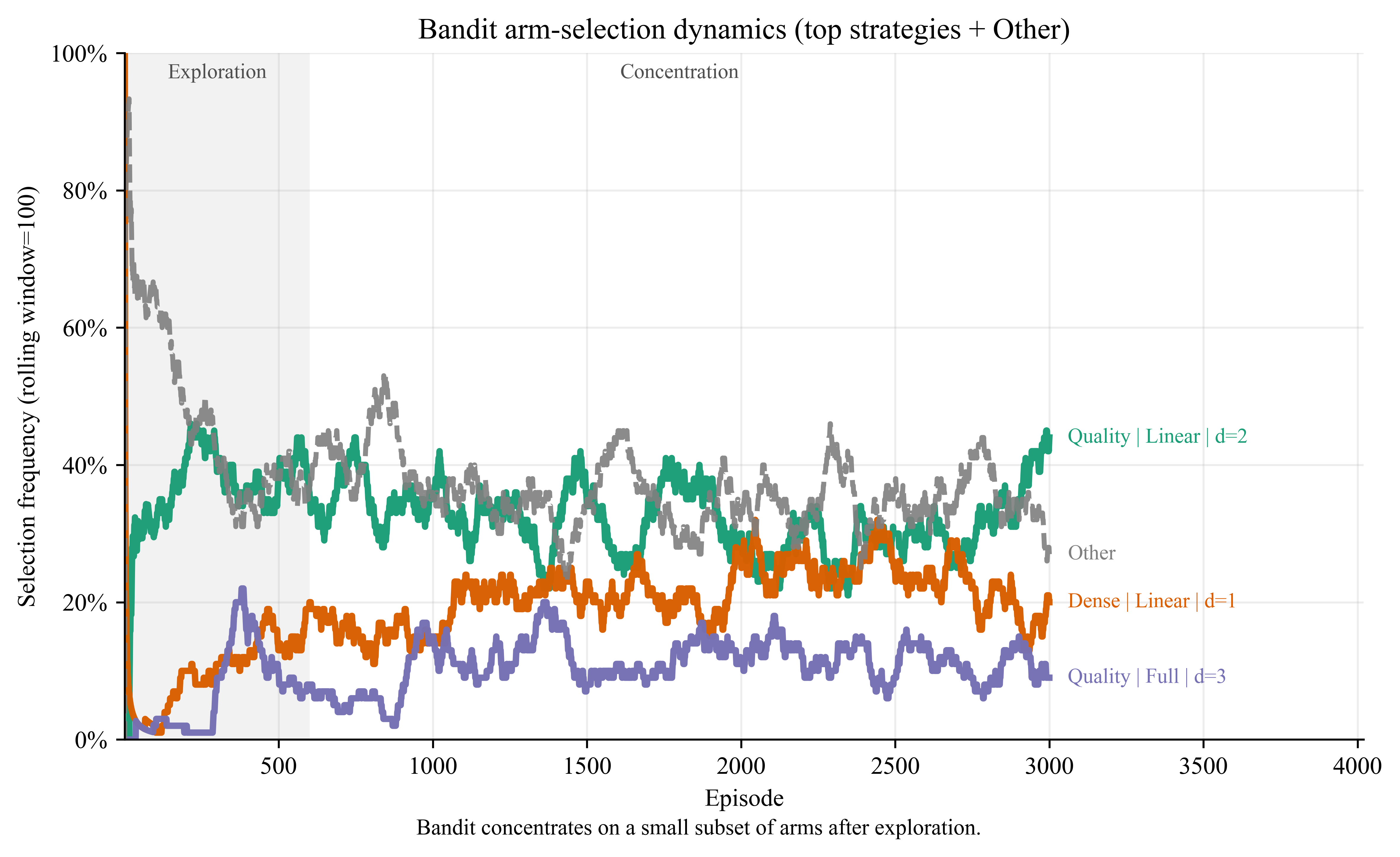
Hardware-aware execution (Section 6). Even bounded-width subproblems suffer SWAP overhead, depth–coherence tradeoffs, and calibration drift. The authors cast configuration as a constrained contextual bandit over (qubit-placement, ansatz family, depth) tuples. Context features include backend descriptors (T1, T2, two-qubit error rates, coupling map degree) and subproblem context (logical width, density). LinUCB with bounded execution-proxy reward learns offline from traces, then deploys with feasibility screening: any top-ranked arm whose estimated gate count exceeds G_max is rejected and the policy falls back to the best feasible alternative.
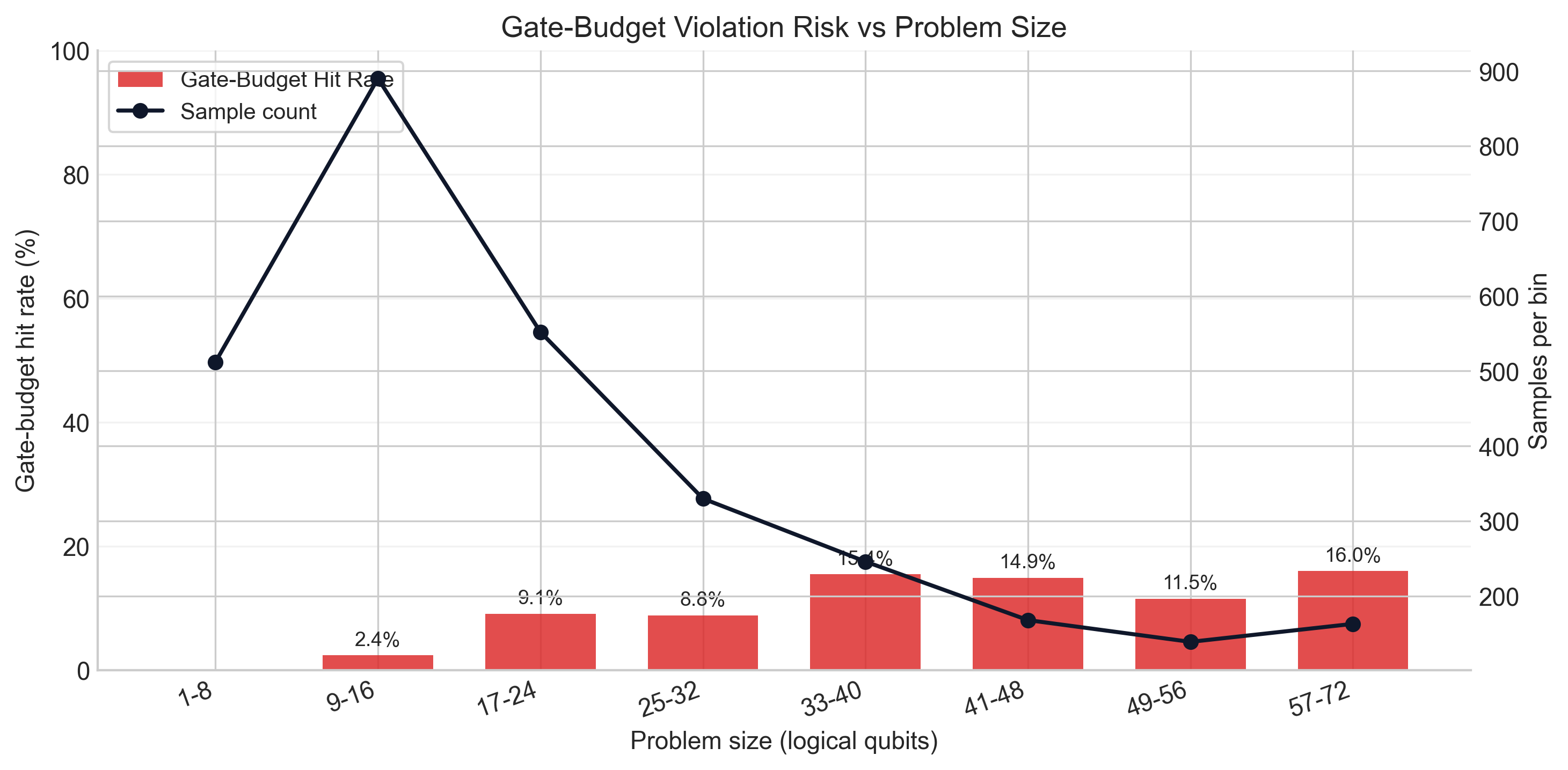
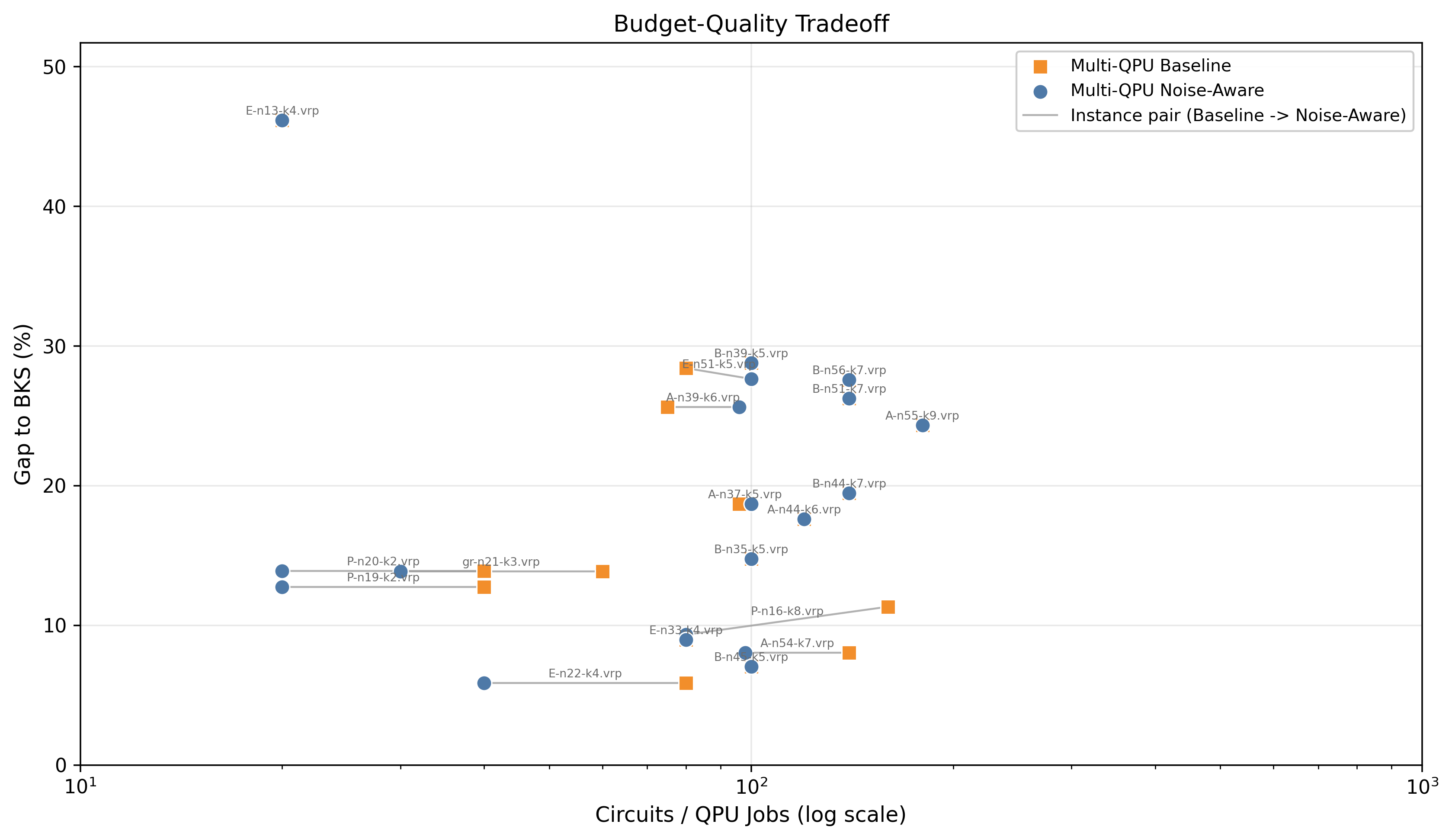
Results (Section 7). On 30 CVRPLIB test instances under matched evaluation budgets, four findings stand out. (i) FJ+LR gives orders-of-magnitude reduction in logical width vs direct CVRP QUBO, with the slack-free tilted penalty reducing width further. (ii) Learned multiplier control roughly halves both mean gap and runtime relative to subgradient. (iii) Bandit-enabled hardware execution lowers mean gap from 17.83% (RL+HW) to 15.72% (RL+HW+Bandit) and median from 17.02% to 14.32%; noisy simulation alone is worse (18.54% mean). (iv) Gate-budget hit rate is negligible at small widths but rises to 9–16% at larger widths — feasibility screening becomes operationally binding rather than ornamental. The honest discussion (Section 8) notes that none of these variants beats a 20s OR-Tools call in absolute terms; the contribution is at the systems level — making each expensive quantum evaluation more useful within an OR-driven decomposition.
Figures
Citations to Yuan's papers
xiao2022class.)
Overlap with Y1–Y6
- Y2 (quasi-binary portfolio QAOA, arXiv:2304.06915) — strong method overlap. Y2's central design move was a logarithmic-qubit encoding plus hard-feasibility mixer that avoids penalty terms; this paper makes the dual move — penalty retained but tilted, with an OR decomposition that bounds width via candidate sets. Both papers also use CVaR-QAOA in the inner solver. The Lagrangian dual loop is analogous to Y2's iterative refinement of QAOA solutions across portfolio-sized blocks.
- Y3 (QAOA DGMVP portfolio, arXiv:2410.16265) — strong scope overlap. Y3 is the closest analogue: an end-to-end QAOA pipeline for a constrained portfolio problem with explicit noise modeling. This paper does the same for CVRP, and its bandit hardware-aware layer extends Y3's noise-regime analysis from "given a fixed backend" to "actively schedule across heterogeneous backends."
- Y4 (Grover + ADMM cardinality-constrained BO, arXiv:2603.14744) — strong method overlap. Y4 already gave an ADMM classical–quantum hybrid for cardinality-constrained binary optimization; this paper provides a parallel design for capacity-constrained binary optimization with Lagrangian outer loop and quantum subproblem solver. The decomposition into bounded-width subproblems mirrors Y4's separation of classical and quantum work.
- Y1 (warm-started QAOA, arXiv:2502.09704) — moderate method overlap. Y1's iterative warm-starting and Y3's layerwise optimization both address QAOA optimization landscapes; this paper's "execution-realized" reward feedback is a related, but coarser-grained, way of stabilizing iterative updates.
- Y5 (Goemans–Williamson via Gibbs states, arXiv:2510.08292) — weak overlap. Both target structured combinatorial optimization, but Y5 is SDP/dequantization-flavored while this paper is QAOA/QUBO-flavored; the connection is at the level of "structured-feasibility encodings" rather than common method.
- Y6 (PBR test on Heron2, arXiv:2510.11213) — none. Foundations vs optimization scope.
Recommended action for Yuan
- Read deeper, then cite from Y4-followup. The CVRP+Lagrangian framing is a near-direct analogue of Y4's ADMM cardinality-constrained pipeline. Any follow-up to Y4 that broadens scope to capacity-constrained or vehicle-routing analogues should cite this paper.
- Adapt the tilted penalty for portfolio. The tilted quadratic penalty (controlled headroom band
[Q−s, Q]) is a small addition that materially improves feasibility yield under sampling noise. It should be tested on Y3's DGMVP encoding where similar boundary-flipping problems likely degrade samples. - Borrow the bandit hardware-aware layer. For any noisy-execution comparison in a Y3 sequel, this paper's LinUCB-with-feasibility-screening recipe is a clean baseline to compare against fixed-backend execution.
- No reciprocal-cite obligation. The authors don't cite Y1–Y6, so there's no immediate diplomatic reason to email; but the Y4 method overlap is a natural conversation starter if collaboration is in scope.