Qubit-efficient and gate-efficient encodings of graph partitioning problems for quantum optimization
Abstract
We introduce a qubit- and gate-efficient higher-order unconstrained binary optimization (HUBO) encoding for graph partitioning problems requiring label-count minimization. This widely applicable class of problems includes minimum graph coloring, minimum k-cut, and community detection. To the best of our knowledge, this is the first work to address the optimization versions of these problems in a quantum setting, rather than only their decision counterparts. Our construction encodes each k-valued vertex variable using ⌈log2 k⌉ bits and employs a novel lexicographic penalty system that implicitly minimizes partition count without requiring dedicated indicator variables. We derive provably sufficient conditions on all penalty coefficients, including those arising from Rosenberg quadratization, guaranteeing feasibility and optimality of the lowest-energy solution. Analogous conditions are derived for a one-hot encoding to enable controlled comparison. We also show that our encoding reduces two-qubit gate count per QAOA layer from Θ(|V||k|² + |E||k|) for one-hot to Θ(|E|·|k|⌈log2|k|⌉). Benchmarking on a quantum annealer demonstrates that our logarithmic encoding significantly improves solution quality and time-to-solution for minimum graph coloring relative to one-hot encoding, with greater advantage as problem size increases.
Executive summary
The paper introduces a HUBO encoding for a broad class of label-symmetric, pairwise-decomposable graph partitioning problems with partition-count minimization (minimum graph coloring, minimum k-cut, community detection) that uses only ⌈log2 k⌉ bits per vertex instead of the one-hot k. A novel lexicographic penalty implicitly minimizes partition count without indicator variables. Provably sufficient conditions on every penalty coefficient (including Rosenberg quadratization penalties) are derived. Empirically on D-Wave Advantage2_1.11, the log encoding beats one-hot in time-to-solution by 1–2 orders of magnitude at |V|=20, with the gap widening with size. For Yuan this is the closest 2026-04-24 neighbour to Y2 (quasi-binary encoding of discrete-valued variables for QAOA on constrained optimization) and Y4 (structured-feasible-space optimization) — the lexicographic-penalty idea is a potential tool for budget/cardinality-constrained variants of Y4.
Main contribution
For a graph G=(V, E) with vertex labels in [k], the paper encodes each vertex as ⌈log2 k⌉ binary variables and represents the indicator 1[ℓu=ℓv] as ∏j(xu,j ⊙ xv,j) (XNOR product), yielding a HUBO of degree up to 2⌈log2 k⌉. To minimize partition count without an explicit count register, the authors add a linear lexicographic term Σk Pk Σv xv,k with geometrically increasing Pk that penalizes use of higher-index bits. The QAOA CNOT count per layer drops from Θ(k²|V| + k|E|) to Θ(k·logk·|E|) — near-exponential for sparse graphs. Practical penalty formulas Pk=(|V|+1)k−1, Aadjacency=|V|·ΣPk+1, and Rosenberg M = 2((|V|+1)L−1)+1+ϵ are all given in closed form.
Key theorems / lemmas / algorithms
- Theorem 3.1 (sufficient one-hot QUBO penalties): Alink>1, Aadjacency>Alink·Cnum, Aone-hot>Aadjacency·|E|+Alink·Cnum suffice for indicator faithfulness, proper coloring, one-hot constraint, and color-count minimality.
- Theorem 3.2 (sufficient log HUBO penalties): With Pk+1>|V|·Σj≤k Pj and A>|V|·Σk Pk, any lowest-energy solution satisfies lexicographic ordering and feasibility (Hadjacency=0).
- Corollary 3.3 (practical log penalties): Pk=(|V|+1)k−1, A=|V|·ΣPk+1.
- Theorem 3.4 (Rosenberg quadratization penalties): M(1), M(2) > A + |V|·ΣPj suffice for the HUBO→QUBO reduction to preserve Theorem 3.2's guarantees.
- Theorem 3.5 (CNOT count, one-hot): NCNOT(one-hot) = Cnum·(|V|(Cnum+1)+2|E|).
- Theorem 3.6 (CNOT count, log): NCNOT(log) = |E|·(2(L−1)·2L+2) via phase-gadget expansion of the XNOR product.
- Theorem 4.1 (general GP penalty): Apartition>|V|·ΣPk/Δmin guarantees feasibility for arbitrary pairwise-decomposable graph partitioning problems with hard constraints, where Δmin is the feasibility gap (min infeasible energy − min feasible energy).
Detailed walkthrough
Setup (§III.A–B). The benchmark problem is Minimum Graph Coloring (MGC): minimize |C| such that adjacent vertices receive different colors. The baseline one-hot QUBO uses Cnum = Cnumu (an efficient upper bound via Brooks' theorem) and introduces a secondary register y of indicator bits yc ∈ {0,1} for "color c is used", giving a Hamiltonian Hone-hot + Hadjacency + Hcount + Hlink requiring (|V|+1)·Cnum qubits and three independent penalties.
Logarithmic HUBO (§III.C). Encode each vertex with L = ⌈log2 Cnum⌉ bits. Since xu,k⊙xv,k = 2xu,kxv,k−xu,k−xv,k+1, the adjacency Hamiltonian Hadjacency=A Σ(u,v)∈E ∏k(xu,k⊙xv,k) is exactly 0 on valid colorings (different bitstrings on adjacent vertices) and ≥1 otherwise. The innovation is the lexicographic term Hlexicographic = Σk Pk Σv xv,k, with Pk+1>|V|·Σj≤kPj. This geometric blowup ensures that reducing one "high-significance" bit (st) always beats any accompanying increases in lower-significance bits, which proves lexicographic minimization (Theorem 3.2(i)). Feasibility (Theorem 3.2(ii)) follows from A>|V|·ΣPk: any infeasible solution costs at least A, which dominates any lexicographic saving. Concretely the authors recommend Pk=(|V|+1)k−1.
Rosenberg quadratization (§III.D). For platforms that need 2-local Hamiltonians (quantum annealers), the degree-2L adjacency product is reduced in two stages: stage 1 introduces yu,v,k=xu,k⊙xv,k with penalty M(1), yielding |E|·L auxiliary bits; stage 2 recursively reduces the remaining product with L−2 Rosenberg auxiliaries per edge. Total auxiliary count is |E|·(2L−2). The logarithmic encoding beats one-hot in logical-qubit count when |E| < ½·((|V|+1)·Cnum−L)/(L−1), i.e., on sparser graphs. The sufficient Rosenberg penalties M(i)>A+|V|·ΣPj preserve Theorem 3.2.
Gate-count comparison (§III.E). For QAOA phase-separation, the one-hot encoding gives Θ(Cnum2|V|+Cnum|E|) CNOTs per layer. The log encoding, via the identity xu,k⊙xv,k=(1+Zu,kZv,k)/2, expands each edge factor into ΣS⊆[L] ∏k∈S Zu,kZv,k — which requires Σs(L choose s)·2(2s−1)=2(L−1)·2L+2 CNOTs per edge, total Θ(Cnum·log Cnum·|E|). For sparse graphs the ratio scales as Θ(Cnum/log Cnum), a near-exponential reduction. For |V|≥Ω(log Cnum) the log encoding always asymptotically dominates.
General graph partitioning (§IV). The scheme extends to any problem of the form Σ(u,v) [αu,v·1[ℓu=ℓv]+βu,v·1[ℓu≠ℓv]]+λ·|{ℓv}|. The partition penalty Apartition must exceed |V|·ΣPk/Δmin, where Δmin is the feasibility gap between the best infeasible and best feasible partition costs. For MGC Δmin=1 and the formula collapses to Corollary 3.3.
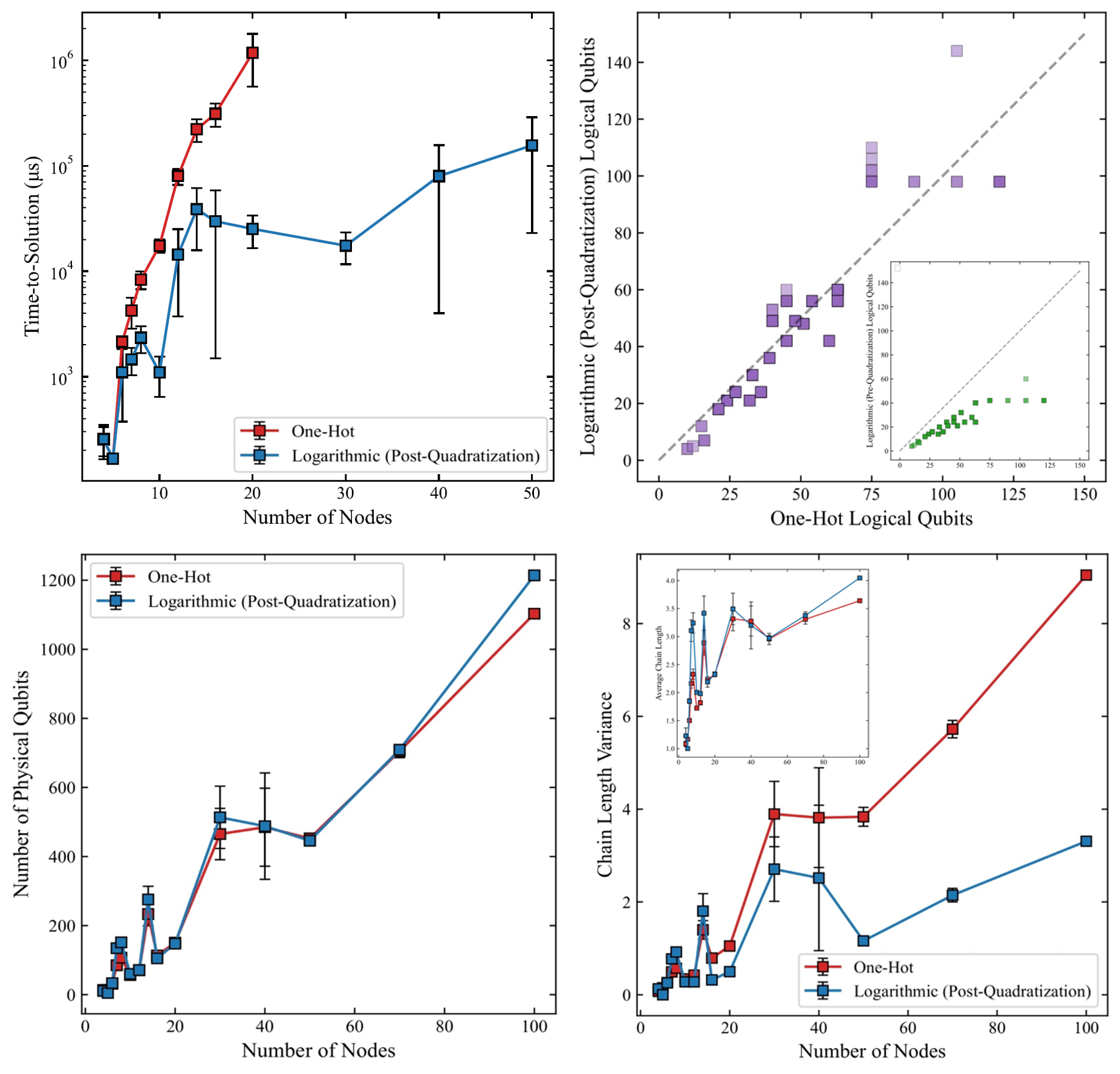
Benchmarking (§V–VI). 350 random graphs with edge density in [0.2, 0.8] and |V|∈[4, 100] were run on the D-Wave Advantage2_1.11 QPU (≈4400 flux qubits, Zephyr topology), with 1000 anneals per instance, TS=20 μs. Kaplan-Meier survival analysis handles instances where pS=0. Headline results (Fig. 2): (i) log-encoding TTS is 1–2 orders of magnitude lower than one-hot already at |V|=20; (ii) pre-quadratization logical qubits lie well below the y=x line (verifying exponential compression); post-quadratization, dense graphs can exceed one-hot, consistent with the sparsity-threshold formula; (iii) physical qubit counts post-embedding are comparable across encodings — so the TTS advantage is not a qubit-savings artifact; (iv) chain-length variance is markedly lower for the log encoding, which the authors credit as the decisive driver (non-uniform chains distort the effective problem Hamiltonian; a single global chain strength can't simultaneously serve long and short chains).
Figures
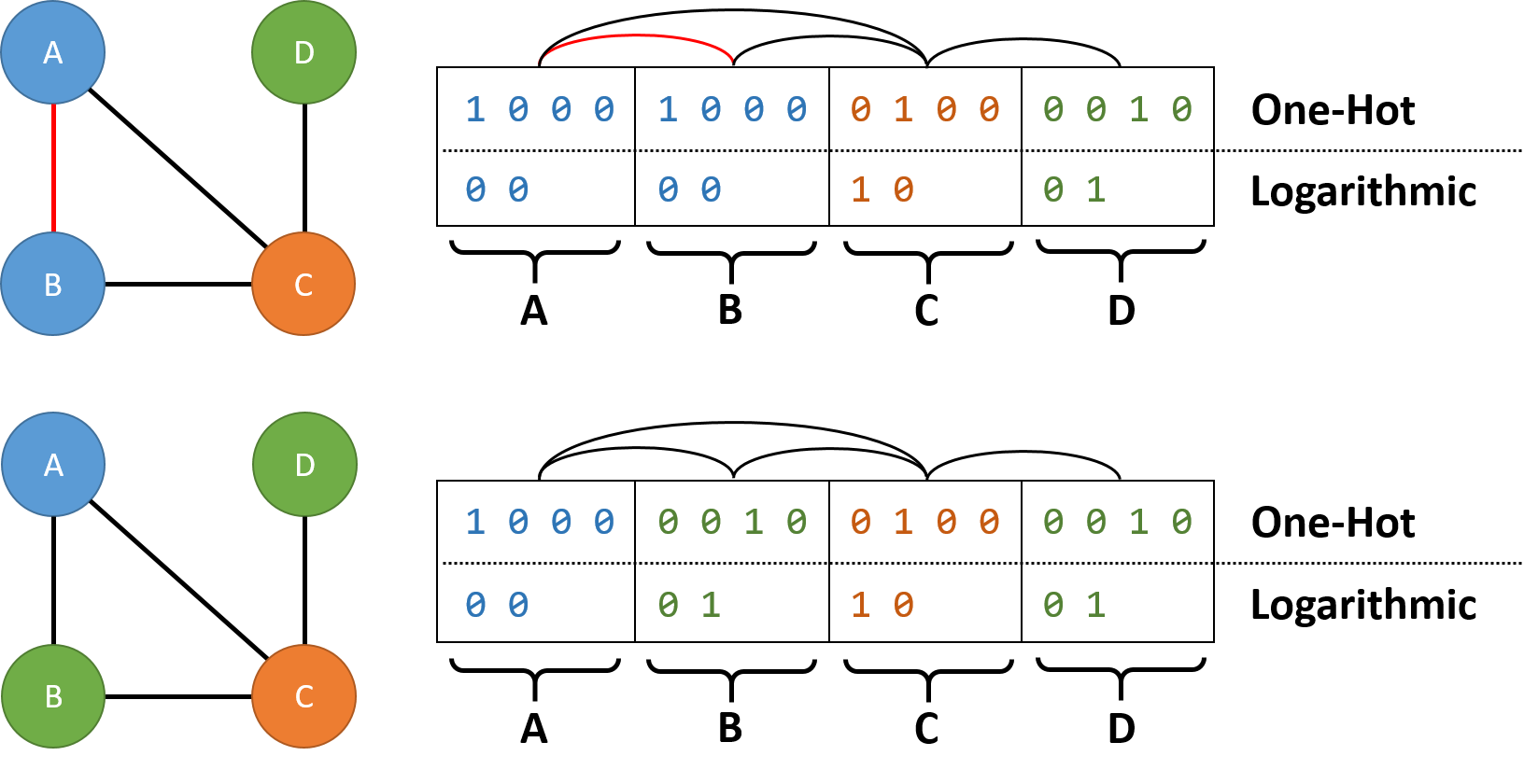
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary encoding, arXiv:2304.06915) — strong method overlap. Y2 encodes each integer variable in ~2⌈log2(U−L+1)⌉ qubits and preserves hard constraints via a tailored mixer (no penalties). This paper encodes each k-valued label in ⌈log2 k⌉ bits and handles constraints via lexicographic penalty instead. The difference in philosophy (penalty vs hard-mixer) is worth highlighting — Yuan could potentially adapt their hard-mixer construction to Zaborniak et al.'s lexicographic setting to avoid penalty-induced landscape distortion.
- Y4 (Grover + ADMM for cardinality-constrained BO, arXiv:2603.14744) — scope/method overlap. Y4 concerns optimization over structured feasible spaces (cardinality constraint); this paper concerns optimization over symmetric-label spaces with partition-count minimization — both are "constrained combinatorial optimization with objective on a complexity-summary of the assignment". The lexicographic penalty idea may generalize to cardinality constraints (priority of "0" bits over "1" bits).
- Y3 (QAOA DGMVP portfolio, arXiv:2410.16265) — indirect method overlap. Y3 gives empirical QAOA benchmarks with careful parameter-optimization; the gate-count reduction here (Theorem 3.6) is directly relevant to Yuan's next-iteration QAOA-on-hardware work, particularly if the portfolio DGMVP is reformulated with k-valued holdings rather than binary.
- Y1 (warm-start QAOA) — weak. No direct method overlap; warm-starting is orthogonal to encoding choice but would compose cleanly on top.
Recommended action for Yuan
- Read deeper and cite. This is a natural citation target for Y2 follow-ups and for any new QAOA-encoding work. Section III.B's literature review of qubit-efficient encodings (domain-wall, logarithmic, polynomial, Sciorilli-style Pauli-compression) is a ready-made related-work scaffold.
- Adapt the lexicographic penalty. For Y4's cardinality-constrained setting, a lexicographic penalty ordering 1-bits by priority could provide an alternative to the Grover+ADMM hybrid when cardinality bounds are soft. Worth a concrete comparison paper.
- Contrast with Y2's hard-mixer. A head-to-head experiment: quasi-binary + hard mixer (Y2) vs log-encoding + lexicographic penalty (this paper), on the same discrete portfolio instance, would clarify when penalty-free encodings outperform and when penalty-based ones do.