Divide-and-Conquer Neural Network Surrogates for Quantum Sampling: Accelerating Markov Chain Monte Carlo in Large-Scale Constrained Optimization Problems
Abstract
Sampling problems are promising candidates for demonstrating quantum advantage, and one approach known as quantum-enhanced Markov chain Monte Carlo [Layden, D. et al., Nature 619, 282–287 (2023)] uses quantum samples as a proposal distribution to accelerate convergence to a target distribution. On the other hand, many practical problems are large-scale and constrained, making it difficult to construct efficient proposal distributions in classical methods and slowing down MCMC mixing. In this work, we propose a divide-and-conquer neural network surrogate framework for quantum sampling to accelerate MCMC under fixed Hamming weight constraints. Our method divides the interaction graph for an Ising problem into subgraphs, generates samples using QAOA for those subproblems with an XY mixer, and trains neural network surrogates conditioned on the Hamming weight to provide proposal distributions for each subset while preserving the constraint. In numerical experiments of Boltzmann sampling on 3-regular graphs, our method consistently accelerated mixing as the system size N increased, with average improvements in the autocorrelation decay rate constant by speedup factors of about 20.3 and 7.6 over classical pair-flip methods based on nearest-neighbor and non-nearest-neighbor exchanges, respectively. We also applied the method to an MNIST feature mask optimization problem with N=784, obtaining faster energy convergence and a 2.03% higher classification accuracy. These results show that our method enables efficient and scalable MCMC and can outperform classical methods for practical applications on NISQ devices.
Executive summary
Kawamata, Nakano and Fujii combine three threads that each independently matter to Yuan: (i) QAOA with an XY mixer on 3-regular graphs (Y1's benchmark problem + Y2's hard-mixer flavour), (ii) cardinality/Hamming-weight constraints (Y4's regime), and (iii) a divide-and-conquer decomposition followed by a conditional MADE neural-net surrogate that takes the QAOA sample distribution offline — removing the need to run QAOA for every MCMC proposal. The result: 20× / 7× speedups over Kawasaki (pair-flip) dynamics on 3-regular graph Boltzmann sampling up to N=512, and a usable NISQ-practical recipe for MNIST (N=784) feature mask optimisation under Hamming-weight constraint. Score 9/10 because the method stack is exactly the confluence of Y1, Y2 and Y4 — this is the paper most likely to influence Yuan's next draft.
Main contribution
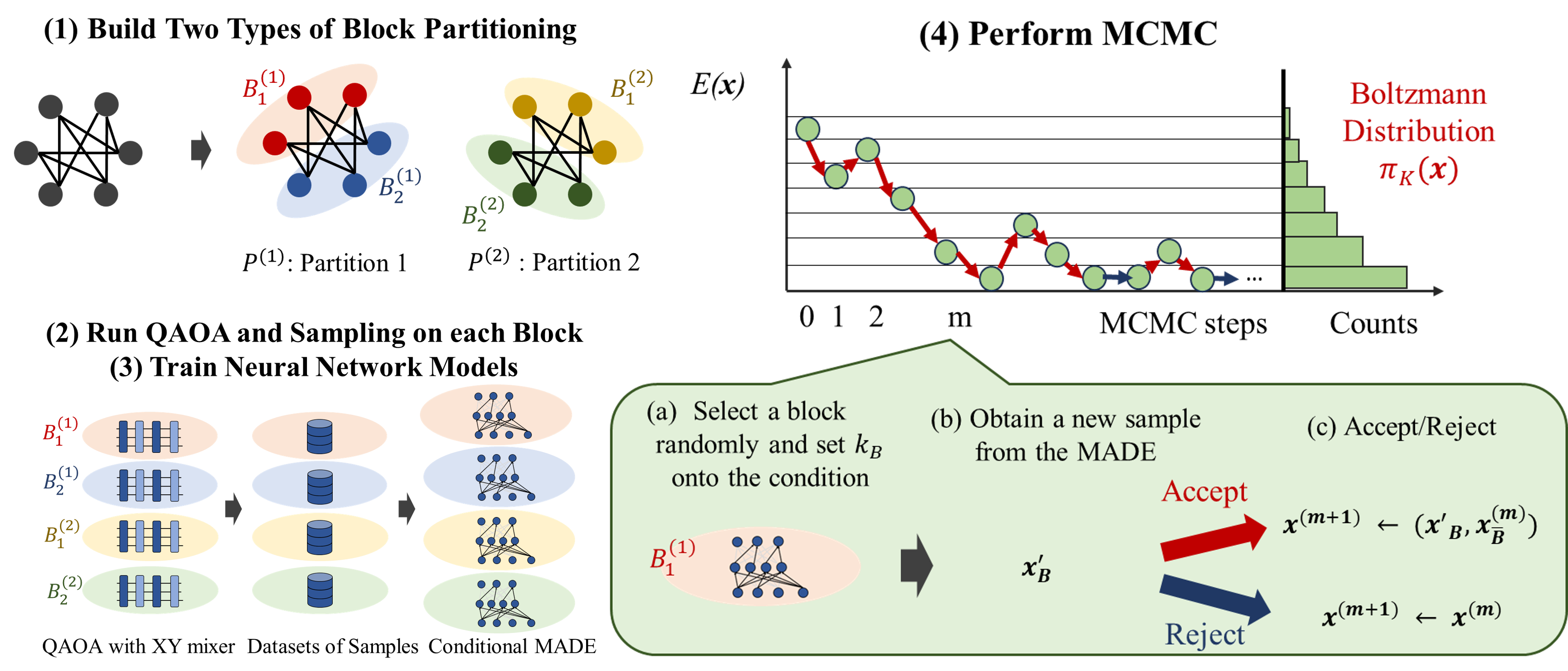
The authors push the Layden “quantum-enhanced MCMC” paradigm to large, constrained systems by (i) decomposing the interaction graph into small blocks (|B|≤16 qubits) whose QAOA can be run on NISQ devices, (ii) training a conditional Masked Autoencoder for Distribution Estimation (MADE) per block, conditioned on Hamming weight, so the same trained network supports any feasible weight, and (iii) using the resulting block-local proposal distribution inside a Metropolis–Hastings chain that preserves the fixed-Hamming-weight constraint globally. The key constraint-preserving ingredient is the XY mixer HM = ½ Σ (XiXj + YiYj), which confines the QAOA evolution to the Hamming-weight-K subspace.
Key algorithmic ingredients
- Cost + mixer QAOA state: |ψ(γ,β)⟩ = ∏l e−iβlHM e−iγlHC |ψ0⟩, with |ψ0⟩ prepared in the K-Hamming-weight subspace.
- XY mixer: HM = ½ Σ(i,j)∈ε (XiXj + YiYj); swaps |01⟩↔|10⟩ so Hamming weight is conserved.
- Block partitioning: interaction graph G divided into size-|B| subgraphs (blocks); authors use |B|≤16, targeting NISQ hardware.
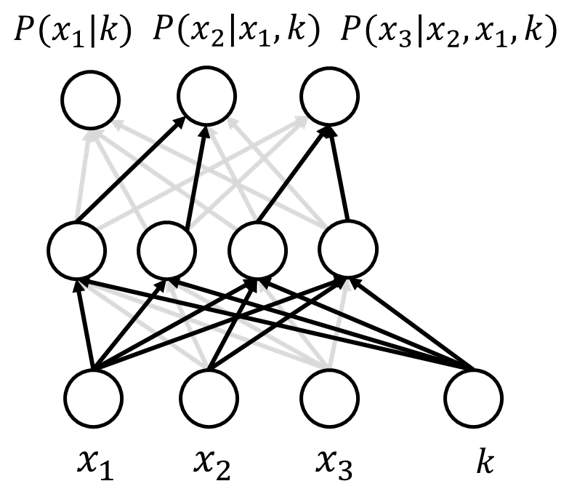
- Conditional MADE surrogate: autoregressive neural network trained to approximate the QAOA output distribution on each block, conditioned on Hamming weight; replaces live QAOA calls during MCMC.
- Metropolis–Hastings proposal: select a block, draw a proposal from the block's MADE while preserving Hamming weight, accept with standard MH ratio.
- Diagnostics: autocorrelation decay τ of Hamming-distance overlap q(t); compared to Kawasaki dynamics (nearest-neighbour and non-nearest-neighbour pair-flip variants).
Detailed walkthrough
Sec. II.A sets up QAOA with an XY mixer on a constrained binary Ising problem. The XY mixer is the textbook tool for Y2-style hard-constraint enforcement: it commutes with the total spin projection along Z, so the state stays inside the Hamming-weight-K subspace. Sec. II.B recaps Layden 2023's quantum-enhanced MCMC: use QAOA samples as proposal distribution for Metropolis–Hastings, accept based on the Boltzmann ratio, avoid the exponentially slow mixing of classical local-move chains. The authors flag the cost issue — running QAOA per proposal is prohibitive — and cite Nakano 2025's MADE surrogate approach as the starting point.
Sec. III (Methods, their Fig. 1 concept_algo) lays out the full pipeline: (1) build two types of block partitioning (so any single spin-flip chain touches multiple blocks over time), (2) run QAOA with XY mixer and sample each block, (3) train a conditional MADE per block with Hamming weight as conditioning input, (4) use the MADE to generate MH proposals. The conditional MADE (Fig. 2, cmade) extends standard MADE (Germain 2015) with active/inactive connections gated by the conditioning Hamming weight — in effect, one neural network covers all feasible weights rather than requiring a separate network per K.
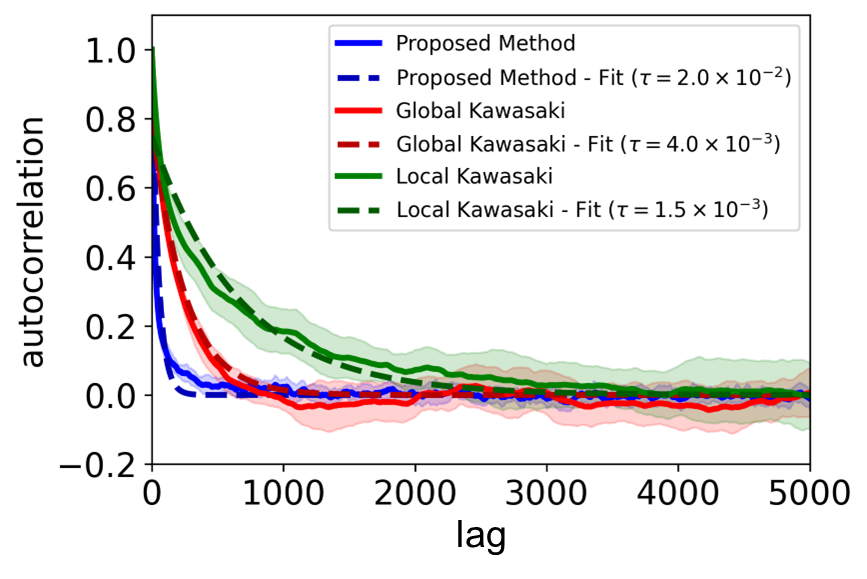
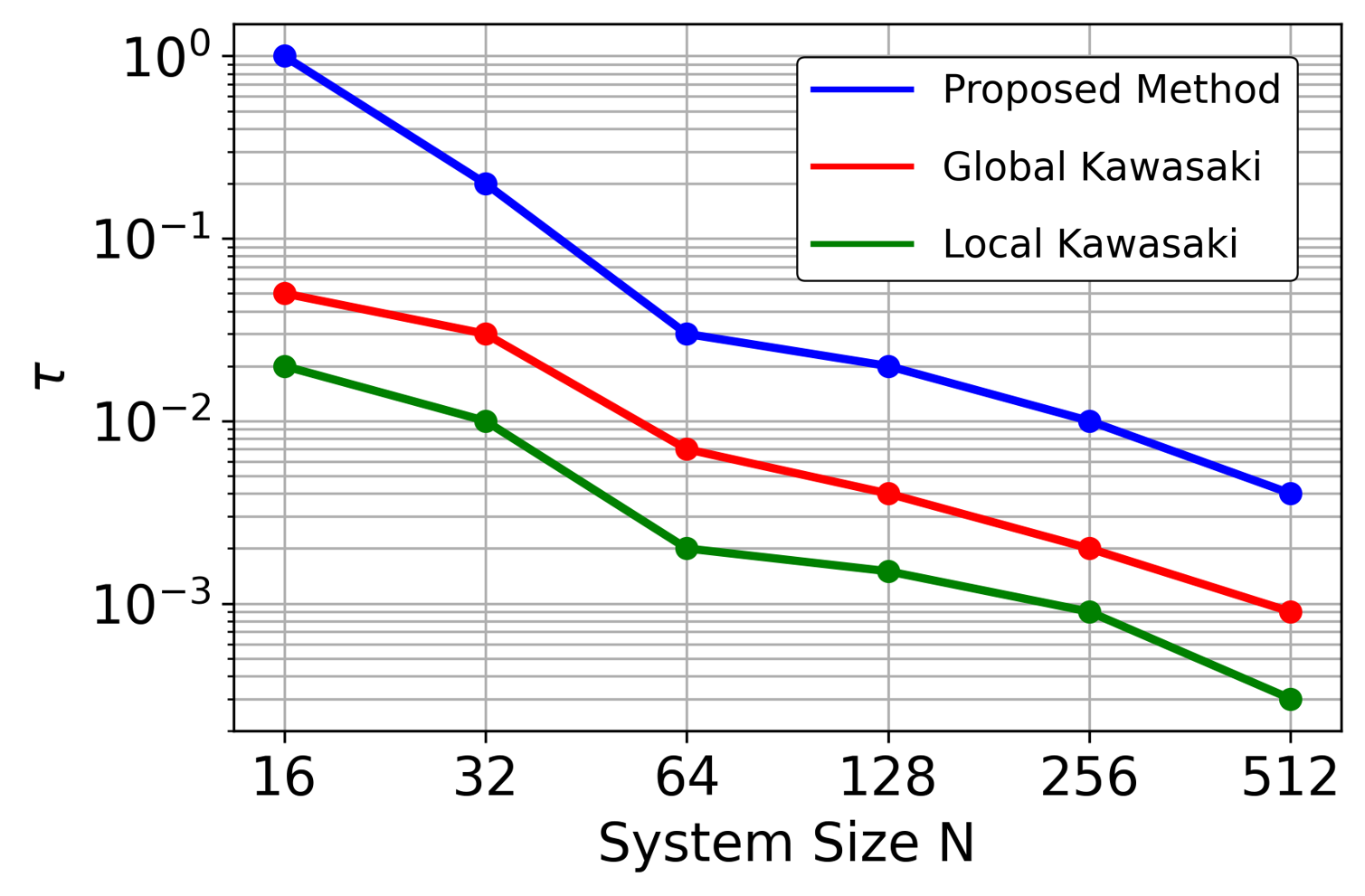
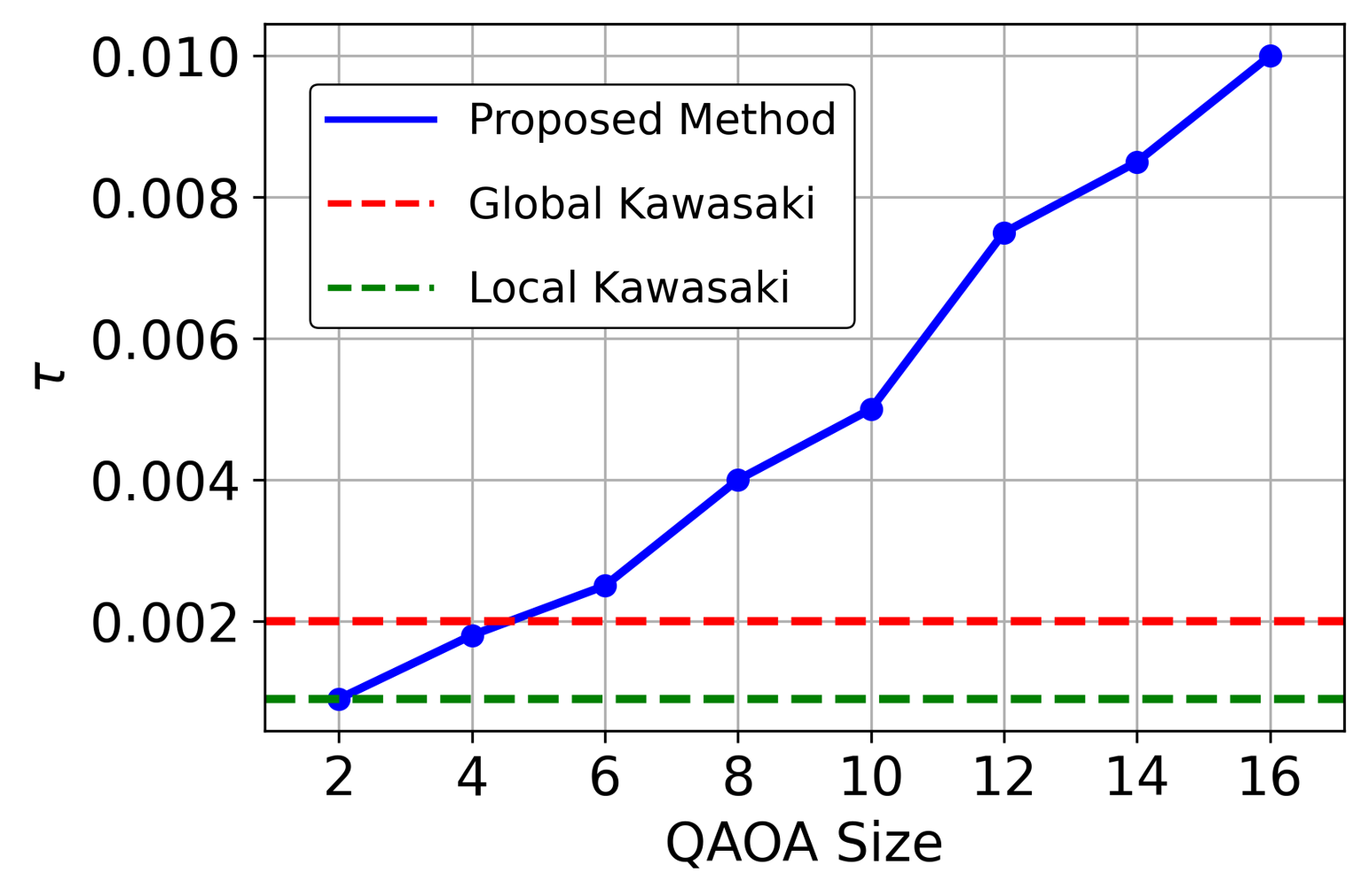
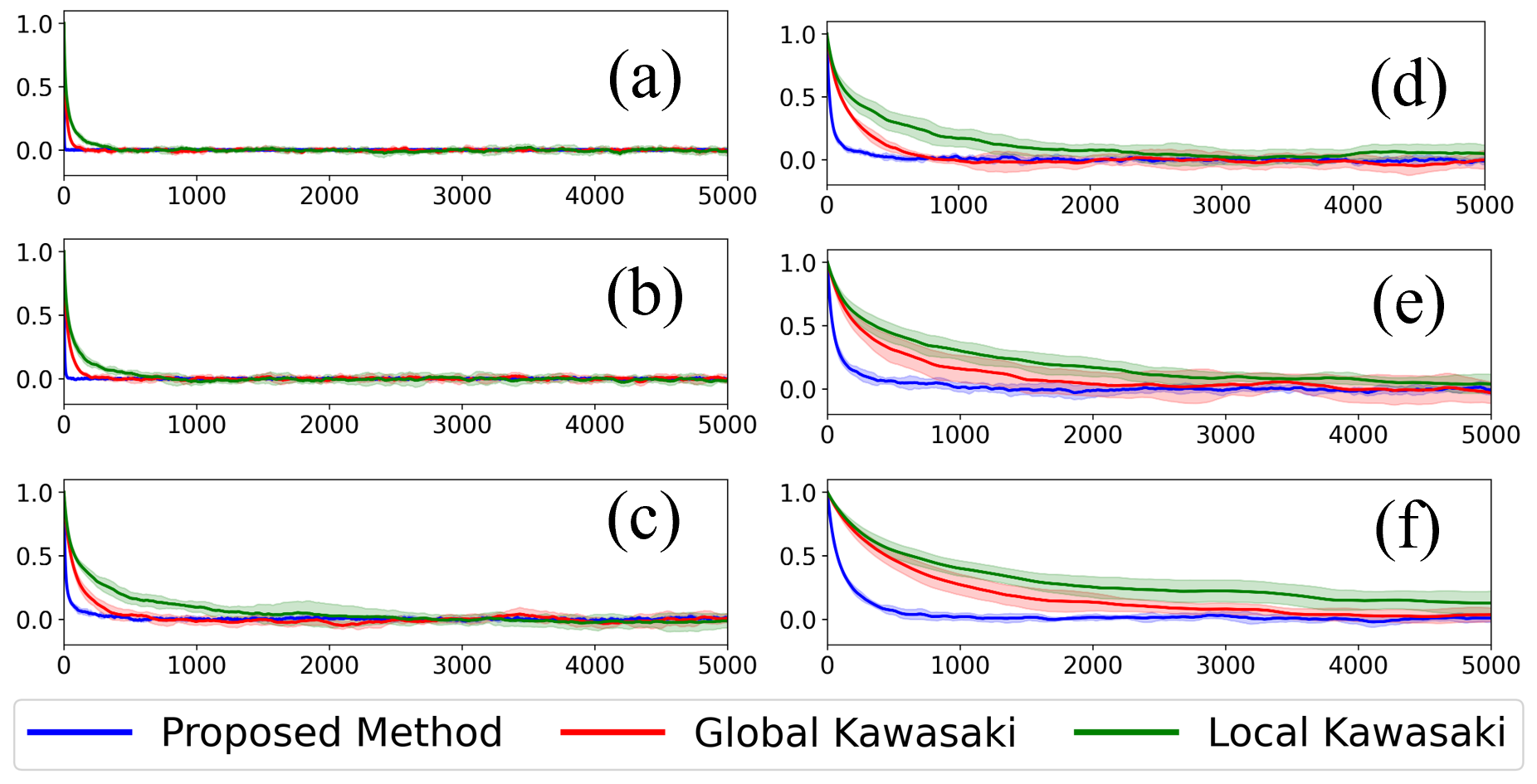
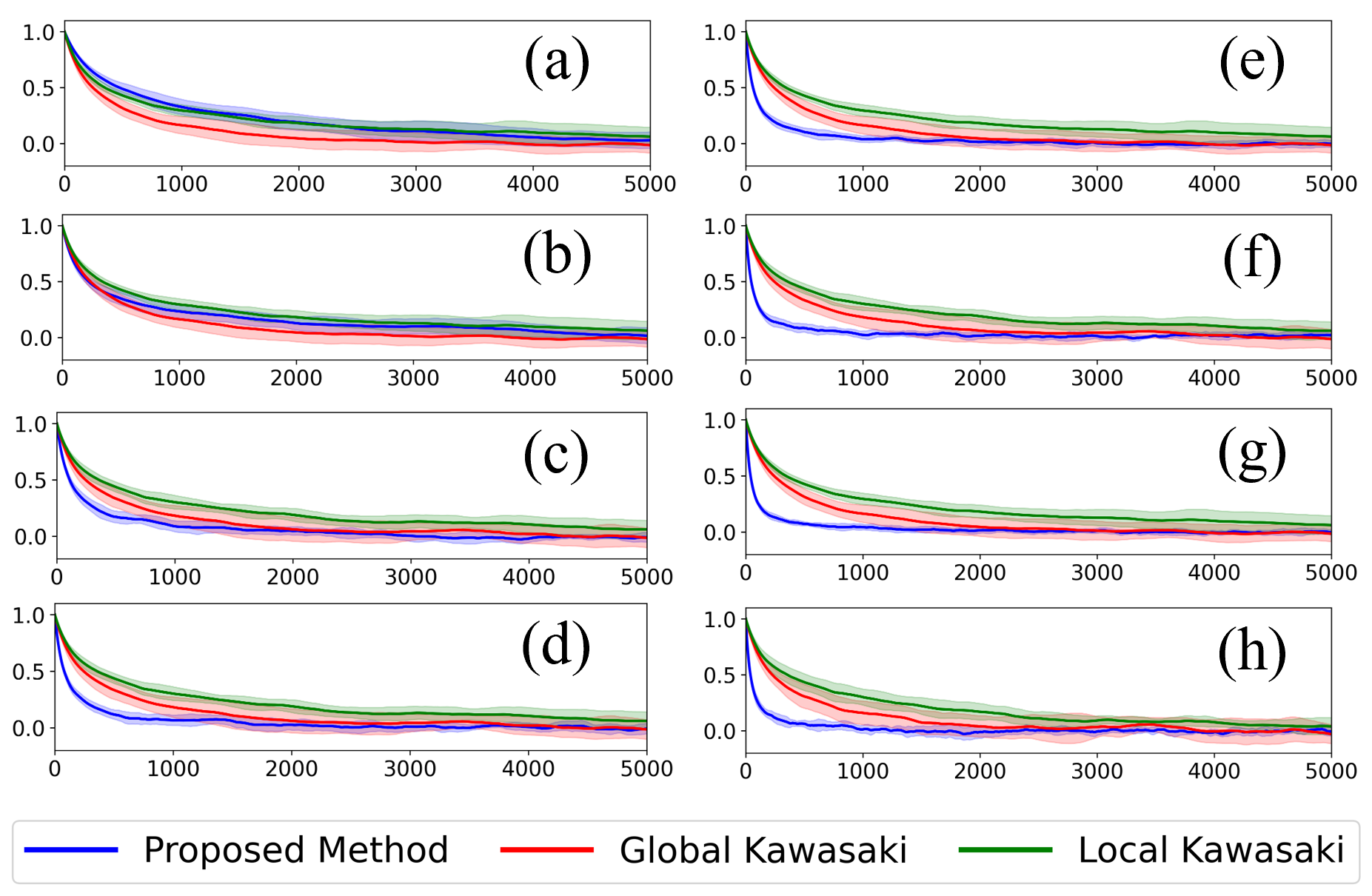
Sec. IV.A is the 3-regular-graph Boltzmann-sampling benchmark. They fix QAOA size |B|=16 and scale system size N=16, 32, 64, 128, 256, 512. Fig. 3 (N128B16_mcmc) shows the autocorrelation decay for N=128, with the fit ρ(l) = A exp(−τl) defining the decay rate. Fig. 4 (3regular_system) plots τ vs N: the proposed method maintains a speedup factor of ~20.3 over nearest-neighbour Kawasaki and ~7.6 over long-range Kawasaki uniformly across N — importantly, the gap does not close with N. This is the scaling argument Yuan cares about: fixed-size QAOA (|B|=16, NISQ-friendly) gives super-constant speedup that persists into the large-N regime classical methods bog down in.
Sec. IV.B fixes N=256 and varies QAOA block size |B|=2…16 (Fig. 5, 3regular_block). Below |B|=6 the proposed method is no better than Kawasaki; at |B|≥6 it surpasses both variants; and performance continues to improve monotonically with |B|. The operational message: the QAOA block size is the knob, and for 3-regular graphs the useful regime starts at |B|∼6 and scales gracefully up to the largest tested |B|=16.
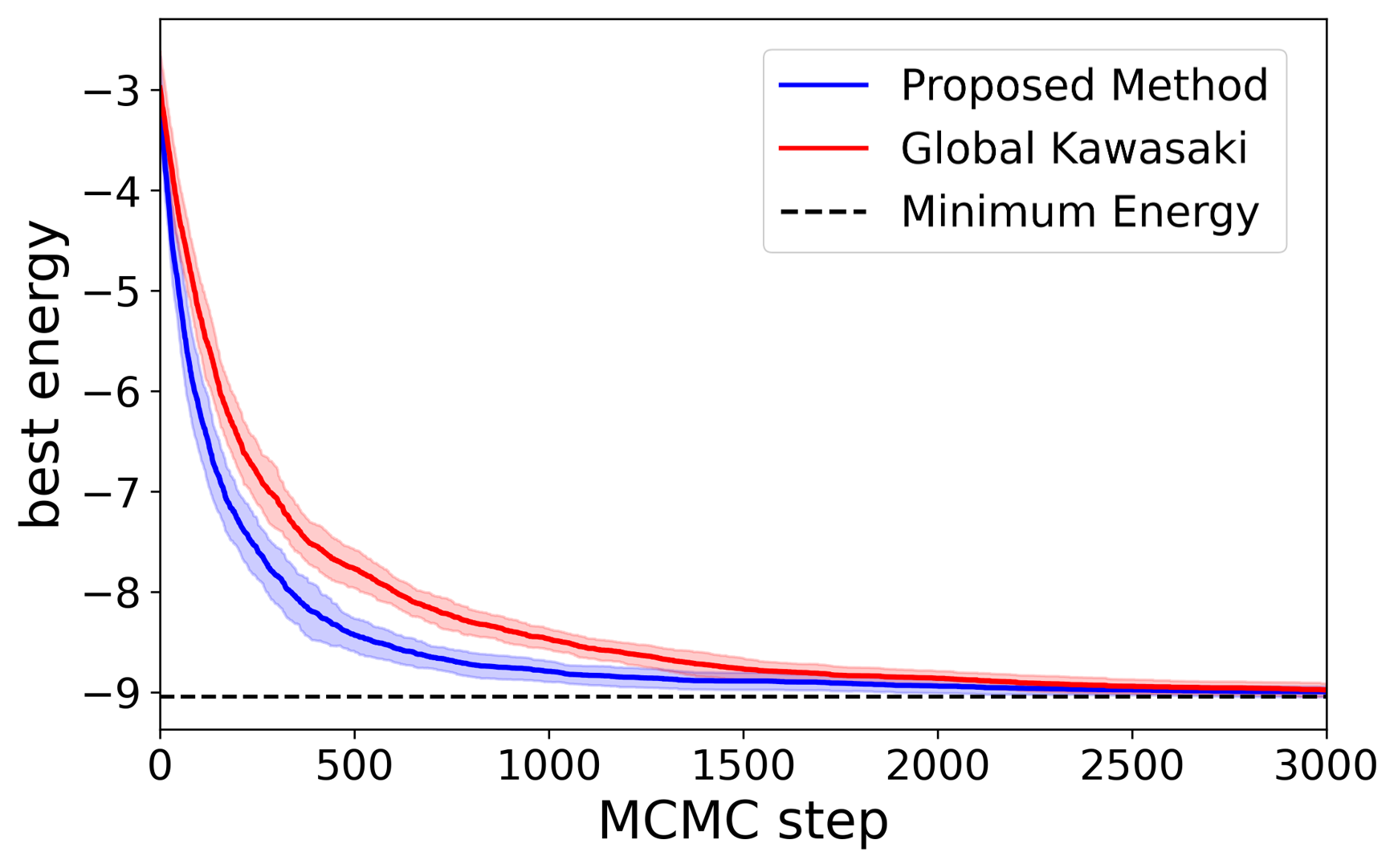
Sec. IV.C is the MNIST application. They pose feature-mask selection as a QUBO with N=784 variables under fixed Hamming weight (cardinality) constraint — this is a bona fide Y4-style problem. Fig. 6 (mnist_energy) shows the proposed method drives the best-so-far energy down faster than global Kawasaki; at MCMC step 50, classification accuracy is 2.03% higher than the Kawasaki baseline. This is a concrete practical datum for “QAOA-on-NISQ helps a real ML preprocessing step” — not a contrived benchmark.
The cardinality constraint + XY mixer + block decomposition combo is the structural signal: this paper essentially builds a hybrid MCMC of the kind Y4's ADMM framework would use as the quantum-inner-loop proposal distribution. The 3-regular graph benchmark is Y1's target problem family. The hard-mixer philosophy is Y2's. It is difficult to find a quant-ph paper from this week more concentrated on Yuan's research axes.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (warm-started iterative QAOA for 3-regular MaxCut) — Strong overlap on benchmark + method. Both Y1 and this paper work on 3-regular graphs using QAOA, and both rely on fixed-size QAOA primitives whose performance needs to generalise to larger graphs. Y1's measurement-based warm-starting could directly feed the block-level QAOA calls here to reduce training-sample cost.
- Y2 (quasi-binary encoding + hard-constraint mixer + CVaR-QAOA) — Very close methodological overlap. Y2 uses a hard-constraint-preserving mixer over a quasi-binary-encoded feasible subspace; this paper uses an XY mixer (the canonical hard mixer for Hamming-weight constraints). The MADE surrogate idea could in principle be applied to Y2's portfolio setting to amortise QAOA runs across rebalancing iterations.
- Y4 (Grover + ADMM cardinality-constrained BO) — Same problem structure: cardinality/Hamming-weight constraint as a first-class citizen. Y4's ADMM decomposition is a classical-quantum hybrid; this paper is also a classical-quantum hybrid, but with MCMC rather than ADMM driving the outer loop. A comparison of the two hybridisation strategies on identical cardinality-constrained benchmarks would be publishable.
- Y3 (QAOA DGMVP portfolio) — Indirect overlap. Portfolio rebalancing with turnover constraint is structurally a Hamming-weight-constrained optimisation; the MADE surrogate pipeline could be adapted to Y3's setting to reduce hardware calls per rebalancing step.
- Y5, Y6 — No direct overlap.
Recommended action for Yuan
- Read carefully and cite in the next draft. This paper sits at the exact triple-intersection of Y1/Y2/Y4 and is very likely to become a standard reference for NISQ-practical constrained QAOA sampling. It deserves a prominent slot in Yuan's related-work section.
- Consider reaching out to Fujii's group at Osaka/Kyoto/RIKEN. The XY-mixer + divide-and-conquer pipeline is a natural counterpart to Y2's quasi-binary encoding. A joint note comparing hard-mixer-via-encoding (Y2) vs hard-mixer-via-XY (this paper) on portfolio or cardinality-constrained benchmarks would be a high-value collaboration.
- Implement for internal comparison. Adapt the MADE conditional-surrogate idea to Y2/Y4's cardinality-constrained benchmarks — particularly the small ORLib MDKP instances — to directly measure how much the MADE surrogate saves over running QAOA live.
- Potentially cite in a follow-up Y1 paper: their observation that |B|≥6 is the threshold for speedup provides a concrete benchmark against which Y1's warm-started QAOA parameter-transfer claims could be tested.