Tensor network surrogate models for variational quantum computation
Abstract
We adopt a two-dimensional tensor-network (TN) ansatz to simulate variational quantum algorithms on two-dimensional qubit architectures, demonstrating its capability to accurately simulate deep circuits through the Quantum Approximate Optimization Algorithm (QAOA) applied to Ising spin-glass problems on heavy-hexagonal and square lattices. For heavy-hexagonal problems with up to three-body interactions, parameters trained on small instances and transferred to systems an order of magnitude larger improve the sampled energy distribution only up to intermediate depths, indicating a fundamental limit of parameter concentration as a transfer strategy. By extending the training itself with TN simulations on larger system sizes, we avoid local minima and obtain lower-energy samples. Analyses of entanglement growth and importance sampling show that the simulation remains classically feasible with moderate bond dimension. We find that parameter concentration also persists on square lattices, albeit at substantially higher computational cost to perform reliable sampling. Overall, our TN framework not only provides an efficient and controlled framework for benchmarking variational quantum algorithms on two-dimensional lattices, but also serves as an effective surrogate model for training variational algorithms.
Executive summary
Watanabe, Sels and Tindall push the classical-simulability frontier of QAOA on IBM-native heavy-hex and square lattices to depths p=100 and 127 qubits — a regime previously inaccessible to both state-vector simulators and real hardware. Their tool is a connectivity-aware 2D tensor-network ansatz with belief-propagation truncations and boundary-MPS sampling. The headline scientific finding is that “parameter concentration” (training on small instances, transferring to larger ones) breaks down at intermediate depth; training directly on n′=35 TN simulations (beyond state-vector) is needed to escape local minima at n=127. This is directly relevant to Yuan's Y1 and Y3: the same parameter-concentration/transfer argument that Yuan relies on for layerwise DGMVP optimisation has a ceiling, and this paper characterises where it hits.
Main contribution
They show that (i) a single-site BP-approximated TN ansatz with bond dimension χ=32 faithfully simulates QAOA on heavy-hex IBM lattices to p=100 (with measurable importance-sampling variance and entanglement well below the χ-imposed ceiling), (ii) parameter transfer from n′=16 saturates at moderate depth and cannot reach the global optimum at n=127, (iii) larger training instances (n′=35, themselves optimised inside the TN simulator) do escape local minima and produce lower-energy samples on the 127-qubit target — demonstrating that TN simulations can serve as a training surrogate, not just a forward-simulation benchmark.
Key algorithmic ingredients
- QAOA ansatz (Eq. 1): U(γ,β) = ∏j exp(−iβjHX) exp(−iγjHC), depth up to p=100.
- Cost Hamiltonian (Eq. 3): Ising spin-glass on heavy-hex with linear, quadratic, and cubic three-body terms (the latter is specific to the IBM 127-qubit benchmark family).
- Interpolation schedule (Eq. 4–5): γj(j/p) = Σc uc fc(j/p) with rescaled Chebyshev polynomials; 10 coefficients optimised by BOBYQA instead of 2p raw angles.
- BP-truncated tensor network: site tensors + converged BP messages used to truncate via local-environment SVD; single-step Bravyi–Gosset-style algorithm extended to arbitrary planar topologies.
- Boundary-MPS importance sampling: sample bitstrings column-by-column with amplitude MPS rank Rm and norm MPS rank RM, using normalised importance weights ω̃ to diagnose sampling faithfulness.
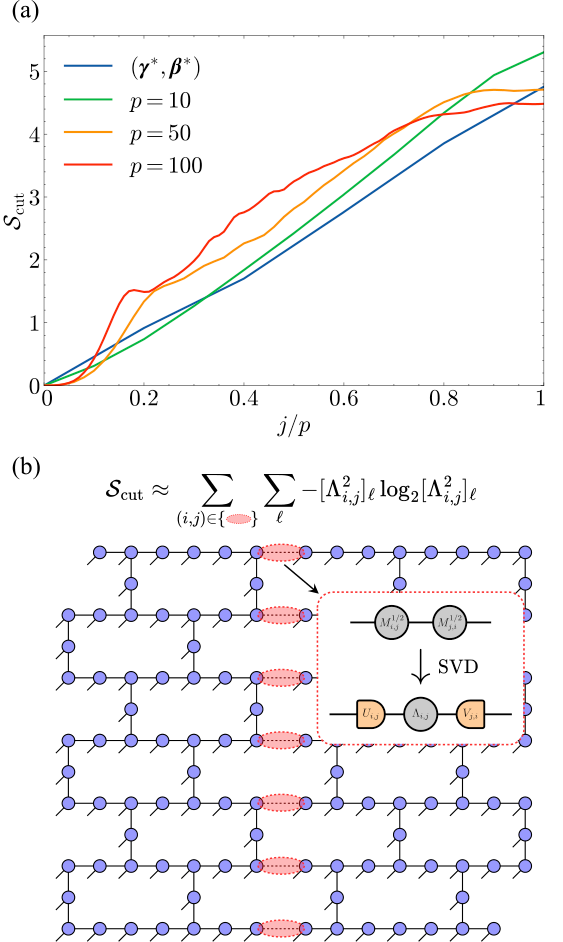
- Entanglement-entropy diagnostic (Eq. 7–8): Scut = Σ Si,j where Si,j is the von-Neumann entropy from SVD of Mi,j1/2 Mj,i1/2.
Detailed walkthrough
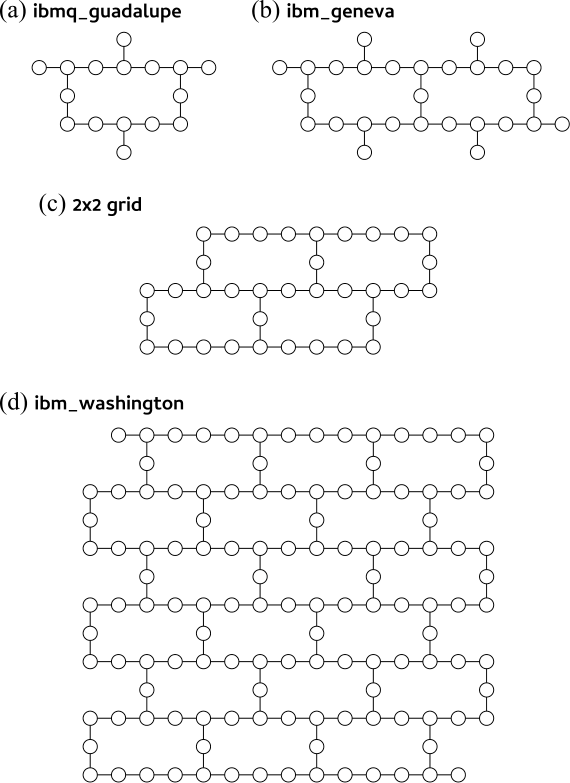
Section II.B fixes the problem class: Ising spin-glasses on (a) heavy-hex lattices with linear/quadratic/cubic couplings uniform on {±1}, and (b) square lattices with only nearest-neighbour quadratic couplings ±1. Both targets are drawn from the IBM benchmark papers (Kim 2023 Nature; Pelofske 2024) specifically to enable head-to-head comparison with hardware runs.
Section III.A describes parameter optimisation. They train on k=100 problem instances at small n′, take the median of the trained angles across instances, and reuse these on the target n. This is parameter concentration with median aggregation; the interpolation ansatz keeps the BOBYQA search in a C=10-dimensional space even at depth 100.
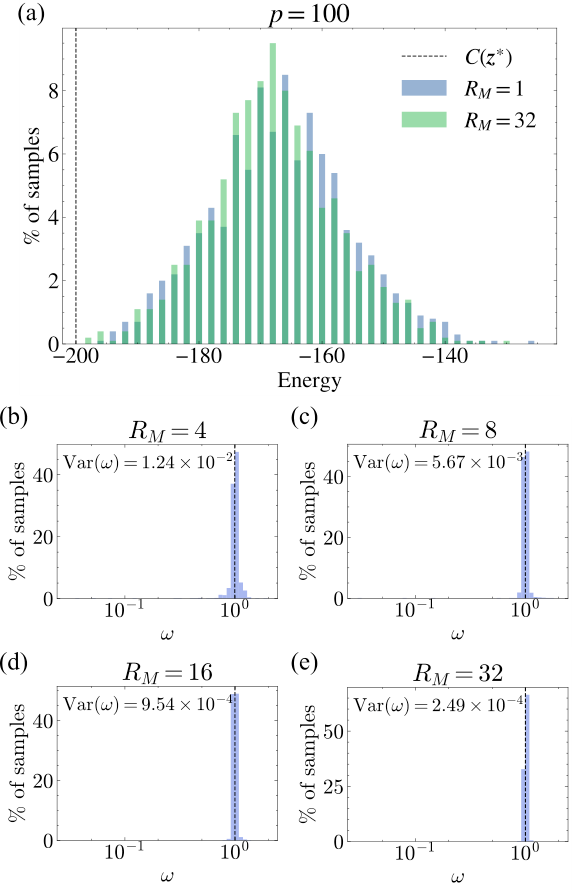
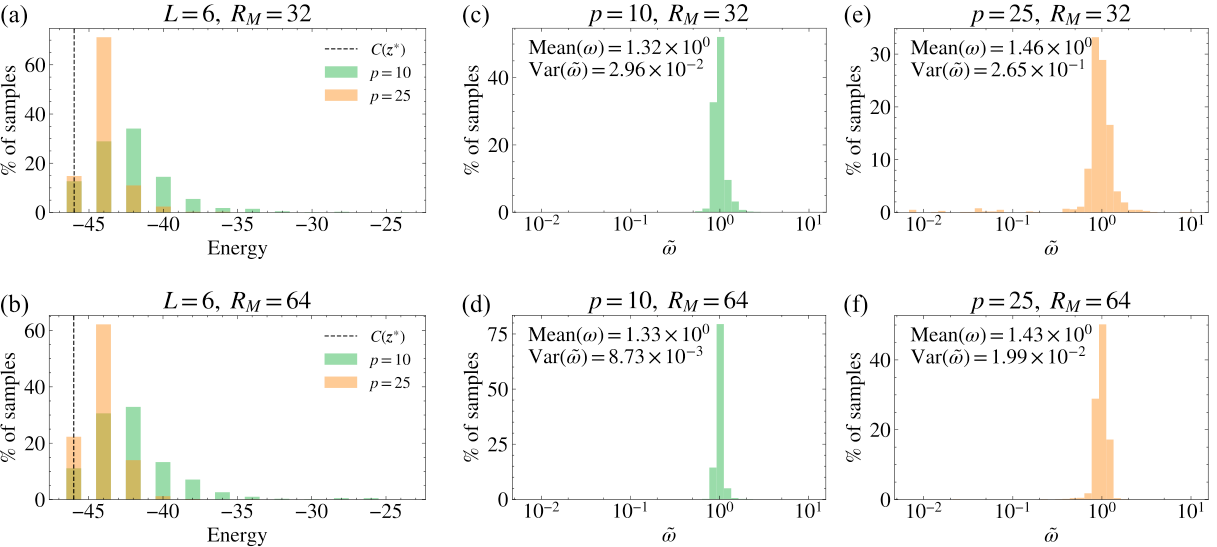
Section III.B is the TN machinery. They use BP to truncate tensors after each gate — converged BP messages furnish a local environment, SVD truncation to bond dimension χ preserves the max-overlap projection within that environment. For the cubic ZZZ rotations in the heavy-hex cost Hamiltonian, they decompose into single-Z + two-qubit CNOTs. Boundary-MPS sampling follows Rudolph's 2025 code; amplitude and norm MPS ranks Rm, RM are independent knobs, and the importance weight ω = P/Q quantifies faithfulness.
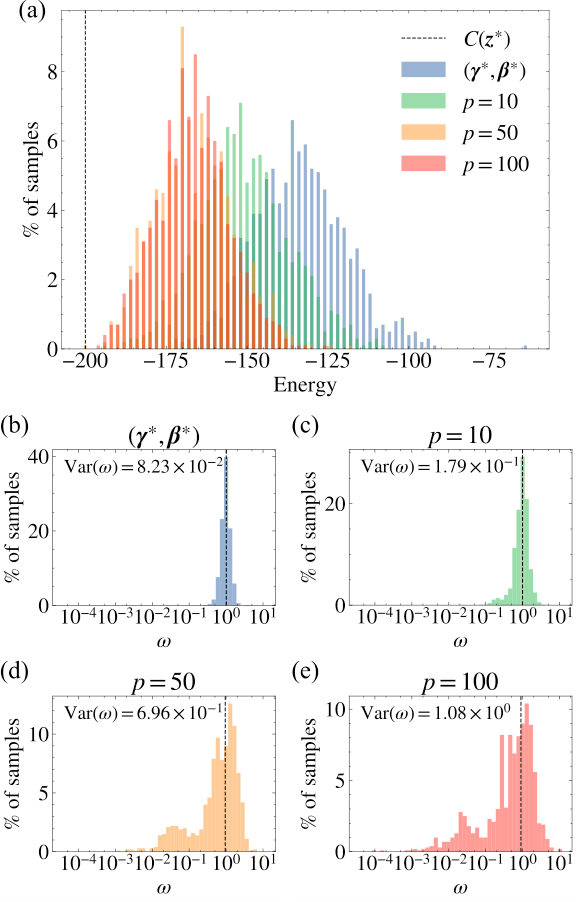
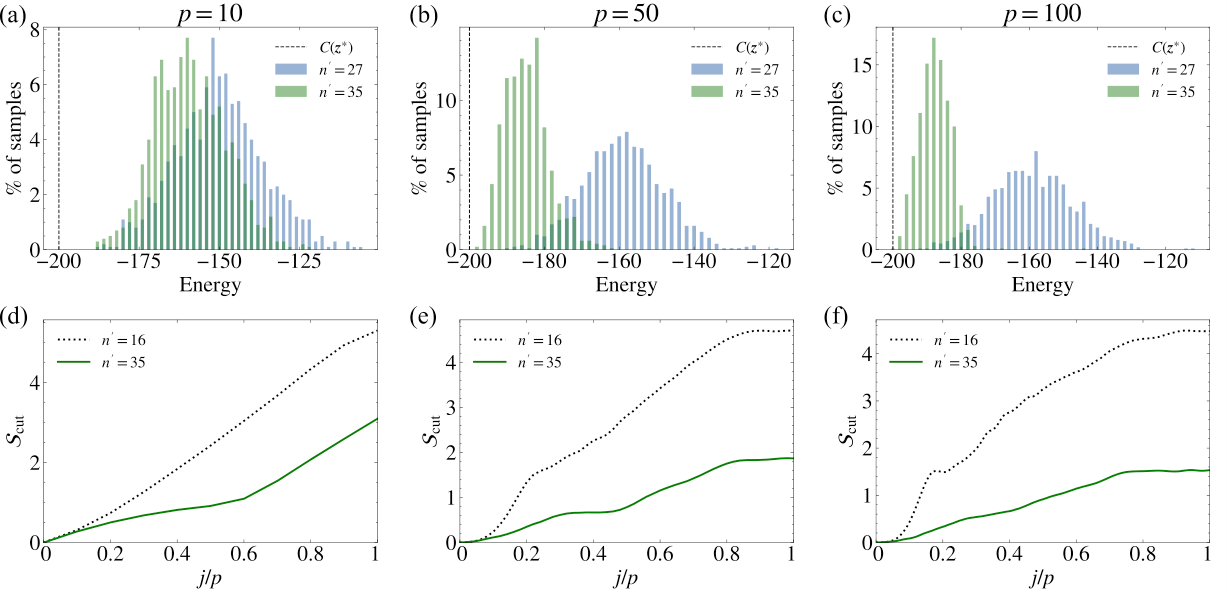
Section IV.A presents the 127-qubit heavy-hex results. Figure 3 (ibm_washington_0) shows the energy histogram at p=10, 50, 100 against the Pelofske p=5 baseline. Deeper schedules clearly drive to lower energies, but no improvement beyond p≥50 — the parameter transfer from n′=16 has saturated. Panels (b)–(e) of the same figure show importance-weight distributions: means near unity, variances small at p=10 but significantly larger at p=50,100 — i.e. the TN state-preserves the norm, but sampling becomes harder at depth.
Section IV.B contains the novel contribution. Since n′=27,35 are beyond state-vector reach, the authors run the BOBYQA loop inside the TN simulator with χ=8. Figure 5 (ibm_washington_0_TN) shows that n′=27-trained parameters look almost identical to n′=16 (because n′=27 already hits optimum and saturates), but n′=35-trained parameters visibly escape the local minimum and produce lower energies at the n=127 target — already at p=10. Critically, the entanglement Scut (panels d–f) is lower for the better-performing n′=35 schedule, which is exactly the self-consistent regime where TN simulation stays cheap.
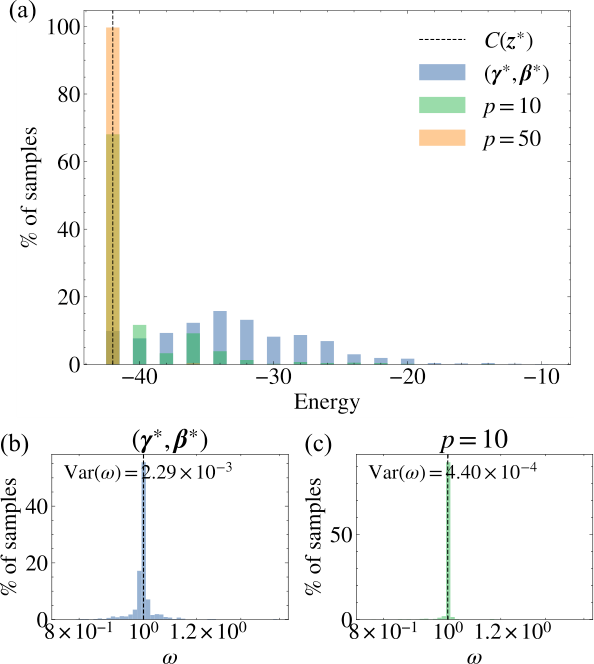
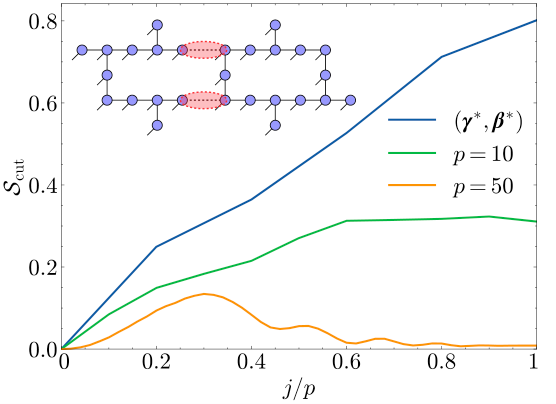
Section IV.C extends to square lattices, where BP fails (short loops) and the norm is not well-preserved. They compensate by normalising ω by its mean and using larger boundary-MPS ranks (RM=64, 98). Parameter concentration still works; accuracy still scales with depth; but the cost per sample balloons, forcing GPU boundary-MPS contractions.
The two cross-cutting messages for Yuan: (1) Parameter concentration is not a free lunch — there is a ceiling, and it scales with the representativeness of the training instance, not just its size. This is directly relevant to Y3's layerwise-optimisation story. (2) Classical TN simulations can now serve as training surrogates for variational quantum algorithms at scales beyond state-vector reach. That changes the calculus of “is this QAOA experiment useful” in the practical-quantum-advantage sense central to Y3.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y1 (warm-started iterative QAOA for 3-regular MaxCut) — Same method family. Y1 warm-starts QAOA parameters via measurement-based iteration; this paper warm-starts them via median-of-trained-instances transfer. Both rely on the empirical parameter-concentration phenomenon. This paper's ceiling result directly informs how far Y1's measurement-based iteration can coast before it needs to re-optimise.
- Y3 (end-to-end QAOA for DGMVP portfolio) — Direct scope and method overlap. Y3 used layerwise optimisation and showed that thermal relaxation precludes quantum advantage while shot-noise-only regimes still scale favourably. This paper's classical-TN surrogate is the natural “shadow hardware” benchmark Y3's story needs: it tells you how much of the observed hardware performance is intrinsic to QAOA and how much is noise.
- Y2 (quasi-binary QAOA) — Weaker overlap. Y2 relies on Grover-like hard mixers to preserve constraint subspaces; this paper uses a vanilla X-mixer. The interpolation/transfer ideas could carry over, though.
- Y4, Y5, Y6 — No direct overlap.
Recommended action for Yuan
- Read and cite in the next QAOA-portfolio paper. This is the cleanest recent TN-surrogate-for-QAOA work; Y3's hardware-vs-simulator story benefits from having an explicit classical surrogate at the 100+ qubit scale to benchmark against.
- Consider a TN-surrogate reproduction of Y3's DGMVP results. The authors' TensorNetworkQuantumSimulator.jl pipeline is public; running Y3's portfolio QAOA through it would directly test whether DGMVP's favourable scaling is preserved at scales beyond the original hardware experiments.
- Apply their training-surrogate trick to Y1's measurement-based iterations. Using TN simulation to optimise warm-start parameters on n′∼30 instances before transferring to larger targets could sharpen Y1's scaling claims.