CVaR-Assisted Custom Penalty Function for Constrained Optimization
Abstract
Constrained combinatorial optimization problems are frequently reformulated as quadratic unconstrained binary optimization (QUBO) models in order to leverage emerging quantum optimization algorithms such as the Variational Quantum Eigensolver (VQE) and the Quantum Approximate Optimization Algorithm (QAOA). However, standard QUBO formulations enforce inequality constraints through slack variables and quadratic penalties, which can significantly increase the problem size and distort the optimization landscape. In this work, we propose a slack-free penalty formulation for constrained binary optimization that eliminates auxiliary slack variables and preserves the feasibility structure of the original problem. The proposed approach introduces a nonlinear custom penalty function to enforce inequality constraints directly in the objective function. To address the computational challenges associated with evaluating nonlinear penalties in variational quantum algorithms, we employ the finite-sampling method that avoids the exponential complexity required by exact expectation computation. Furthermore, we integrate the Conditional Value-at-Risk (CVaR) objective to improve optimization robustness and guide the search toward high-quality solutions. The proposed framework is evaluated on instances of the multi-dimensional knapsack problem, a classical benchmark in combinatorial optimization. We showcase that the proposed custom-penalty formulation combined with CVaR sampling achieves improved optimality gaps and more consistent performance compared with conventional slack-based QUBO formulations. The results suggest that careful penalty design can play a critical role in enabling quantum and hybrid quantum–classical algorithms for constrained optimization problems that arise in operations research.
Executive summary
Lee & Lau tackle the same pain point that Y2 and Y4 address — that standard QUBO slack-variable encoding of inequality constraints bloats the qubit count and distorts the landscape. Their alternative keeps the constraint violation as a nonlinear (Heaviside-step) penalty on the original variables and computes its expectation via finite sampling rather than Pauli-level exact diagonalisation, eliminating the O(2t) blow-up that had previously made custom penalties impractical. CVaR post-selection on the sampled bitstrings then sharpens the optimisation landscape so that VQE/QAOA converges to feasible, high-quality solutions. The message for Yuan: you can now get Y2-style “hard-constraint-preserving” behaviour from a vanilla HEA + penalty pipeline — without designing a constraint-preserving mixer — and it is benchmarked on up-to-50-qubit multi-dimensional knapsack.
Main contribution
The authors replace the exact-diagonalisation estimator of a non-linear penalty expectation ⟨ξ(Hj)⟩ (their earlier QCE paper, exponential in the number of variables per constraint) with a plain Monte-Carlo estimator Ê(θ) = (1/M) Σm L(x(m)), justified by Hoeffding's inequality (Eq. 9–11 of the paper). This reduces per-iteration cost to a fixed shot budget M ≥ (R2/2ε2) ln(2/δ) where R is the loss range. They then stack CVaR-α on top, which costs a further factor of α in samples while concentrating the loss on low-energy tail states. The combined framework is validated on 12 OR-Library multi-dimensional knapsack instances (10–50 variables, 2–10 constraints) with a single-layer RY–CZ hardware-efficient ansatz and POWELL optimiser.
Key algorithmic ingredients
- Custom penalty loss: Lcustom(x) = f(x) + Σj λj ξ[hj(x)], with ξ chosen as Heaviside step Θ(·) (Eq. 4–5). Separates feasible from infeasible without slack variables.
- Finite-sampling expectation (Eq. 8): Ê(θ) = (1/M)Σ L(x(m)), no dependence on exponential eigenvalue structure.
- Hoeffding shot budget (Eq. 10–11): M ≥ R2/(2ε2) · ln(2/δ); motivates coefficient rescaling to keep R small.
- CVaR estimator (Eq. 12): CVaR(α;θ) = (1/⌈αM⌉) Σm=1⌈αM⌉ L(x(m)), with α=0.1 in experiments.
- Penalty factor upper bound: λ = 2λUB with λUB = Σ vi, ensuring any single constraint violation dominates the objective gain.
- Ansatz: |ψ(θ)⟩ = ⊗i RY(θn+i) · (linear CZ chain) · ⊗i RY(θi); single-layer only, on the argument that deeper HEAs introduce spurious minima.
Detailed walkthrough
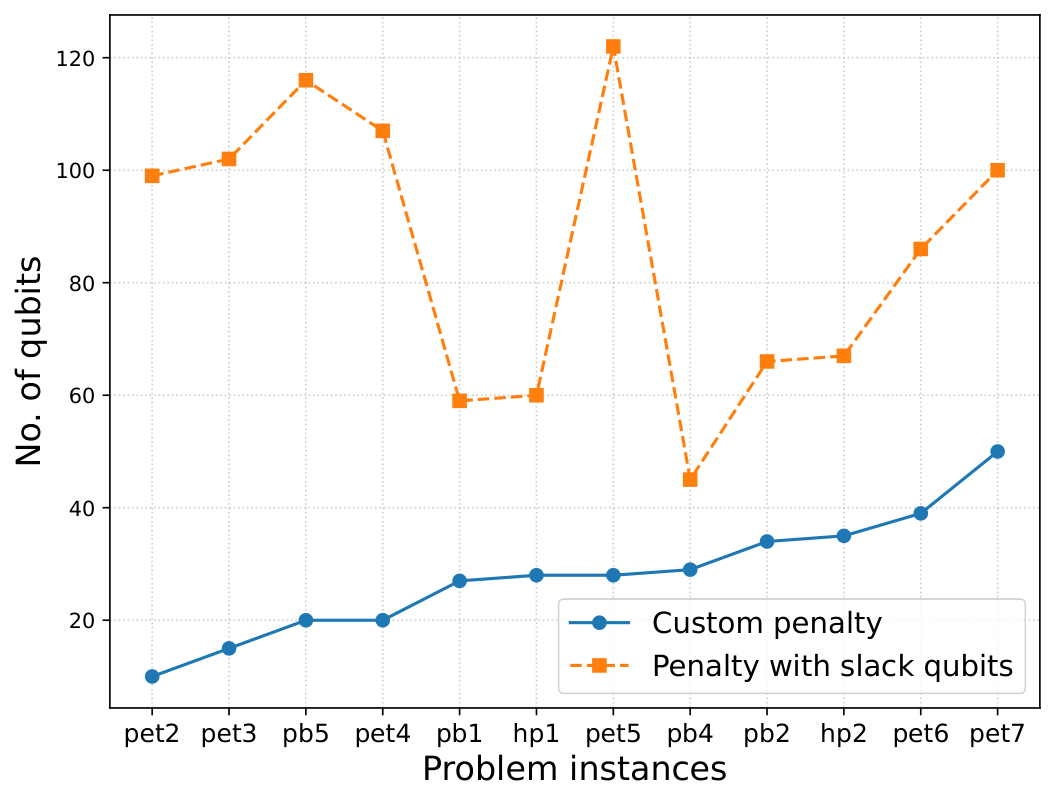
Section II.A formalises the problem: given minx f(x) subject to equality (gi=0) and inequality (hj≤0) constraints on x∈{0,1}n, the slack QUBO is Lslack = f + Σλ0gi2 + Σλ1(hj + Σ 2l yl)2. Two problems are highlighted: (i) feasibility is ambiguous for slack values that happen to zero the penalty even when x is infeasible, and (ii) binary encoding of slack requires ⌈log2 sj⌉ extra qubits per constraint. Figure 1 (num-qubits-comparison) quantifies this — up to ~80 extra qubits on their 50-variable MDKP instance (pet7), which is a significant hit against current 100-qubit devices.
Section II.B is the crux. Given the custom-penalty Hamiltonian H = Hf + Σλj ξ(Hj), linearity lets you decompose ⟨H⟩ = ⟨Hf⟩ + Σλj ⟨ξ(Hj)⟩. ⟨Hf⟩ decomposes into Pauli-Z expectations, but the non-linear ξ(Hj) term does not — the authors' prior work (“step-QCE”) required populating all 2t eigenvalues of the t-variable constraint Hamiltonian. The finite-sampling estimator sidesteps this entirely: sample the state, evaluate the full (nonlinear) loss on each bitstring, average. The price is a statistical error ε governed by Hoeffding's inequality (Eq. 9), with shot budget scaling as R2/ε2. The authors explicitly compute R = Ctrue + 2dΣvi for MDKP and flag coefficient rescaling as an open knob.
Section II.C introduces CVaR-α: after sampling M shots, sort bitstrings by loss and average only the bottom ⌈αM⌉. The authors derive that CVaR needs only α·MFS samples to match the FS estimator — a 10× shot saving at α=0.1 — plus an O(kn log n) sort overhead per evaluation.
Section IV (Analysis on Sampling Cost) works through the Hoeffding bookkeeping. Notably, at α=0.1 and a sufficiently converged state, the probability of sampling the quasi-optimum x* is pα = min(px*/α, 1); so CVaR already “passes” once px* > α. This is precisely the scaling argument Y2 and Y3 engaged with for portfolio QAOA, and it explains why Y3's DGMVP analysis consistently found CVaR more shot-efficient.
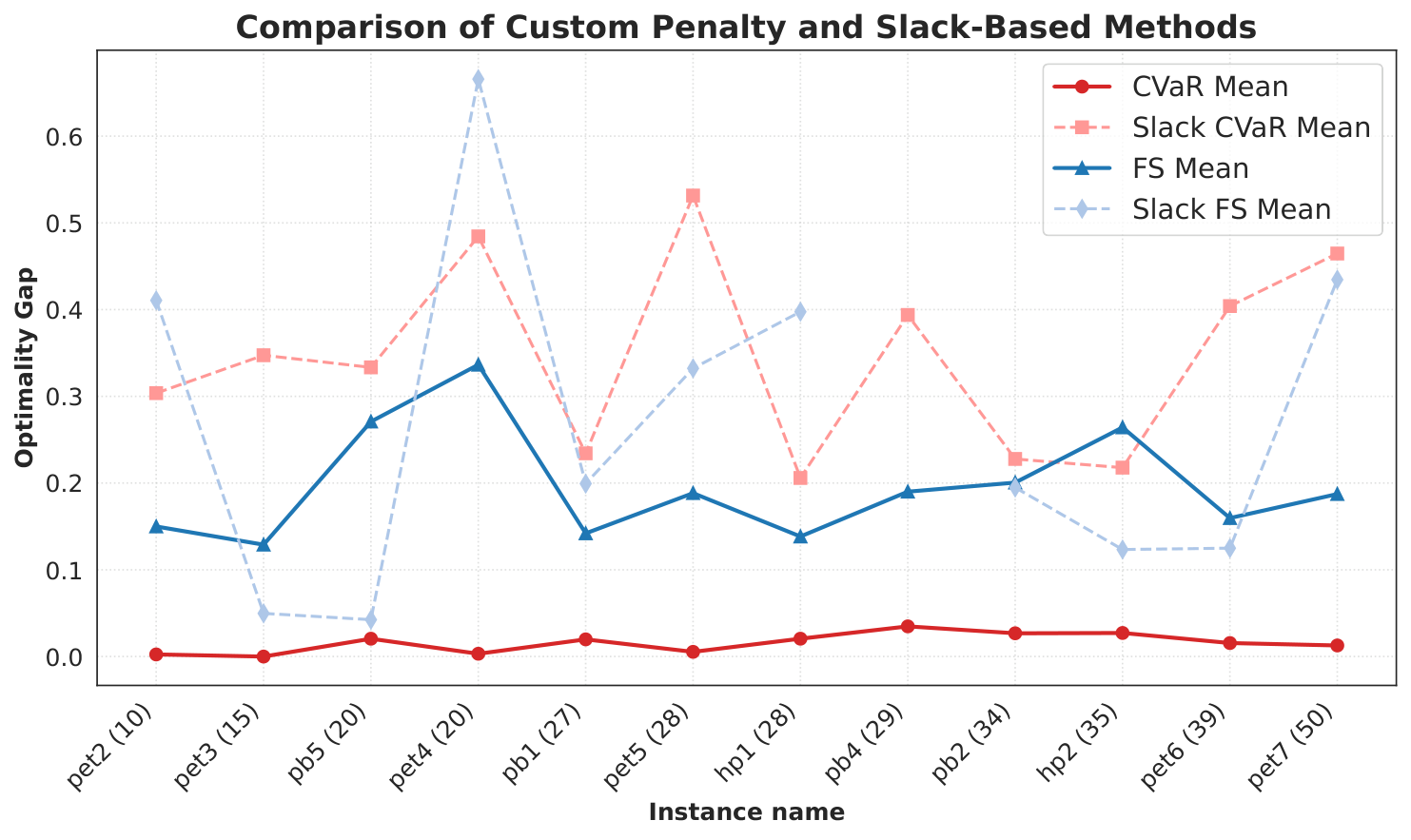
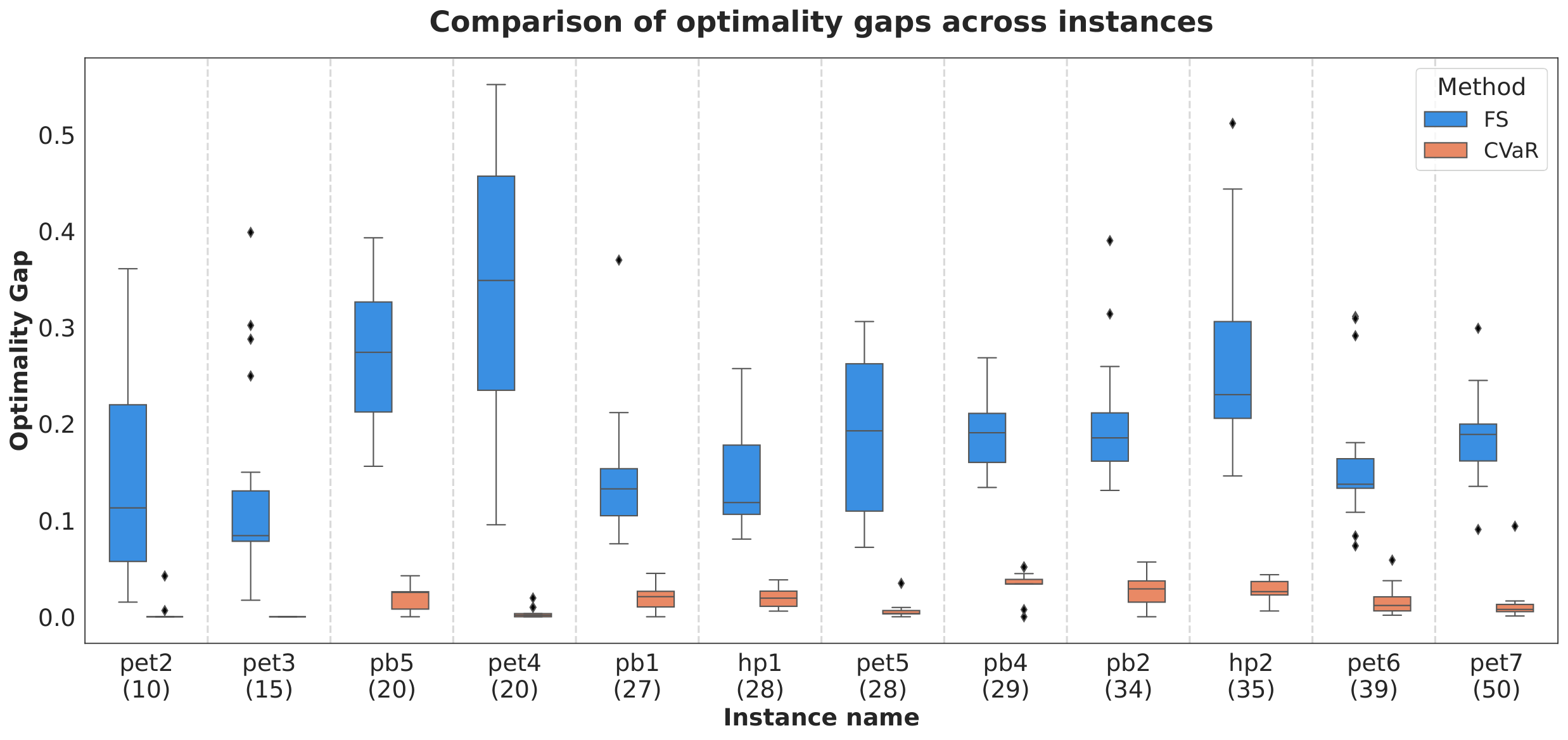
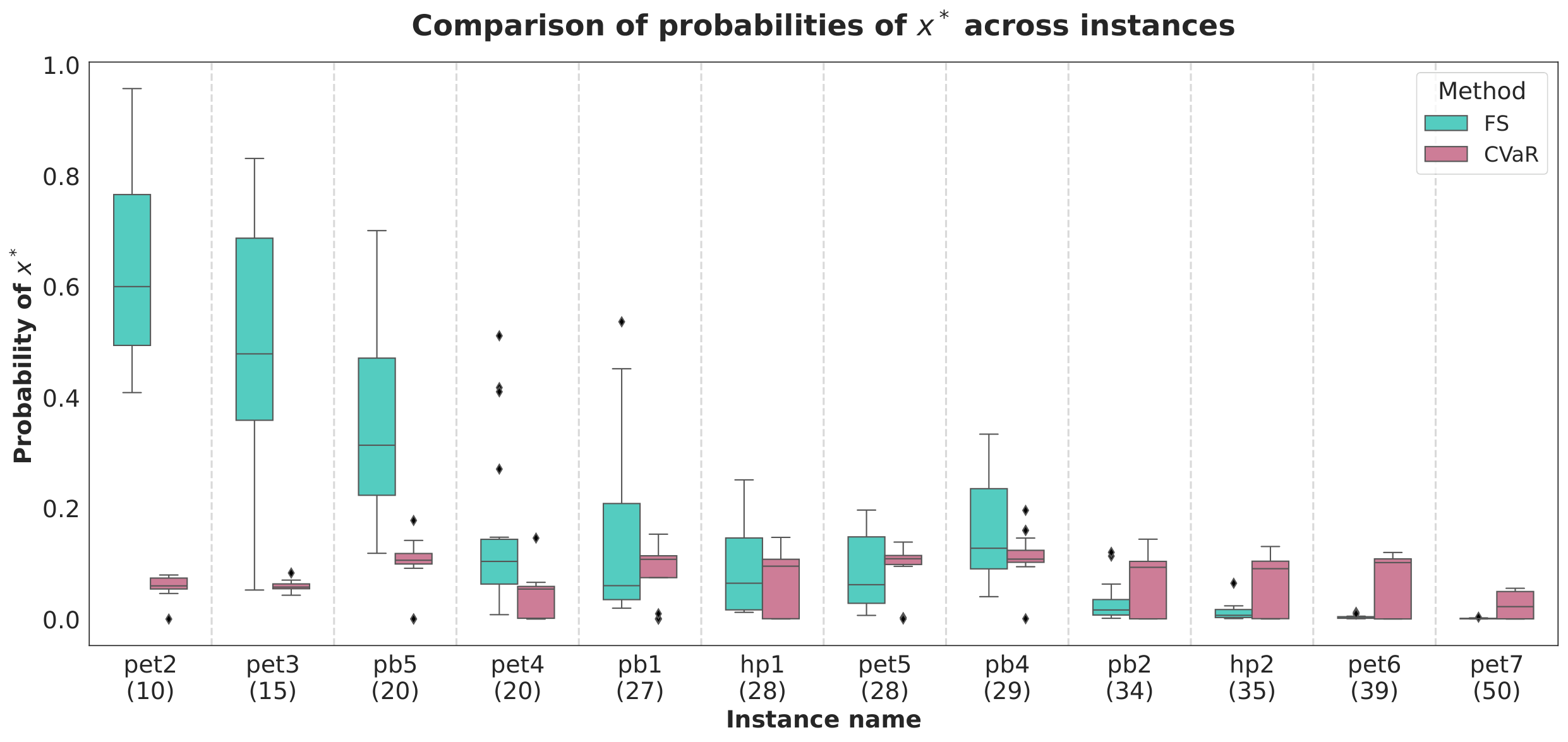
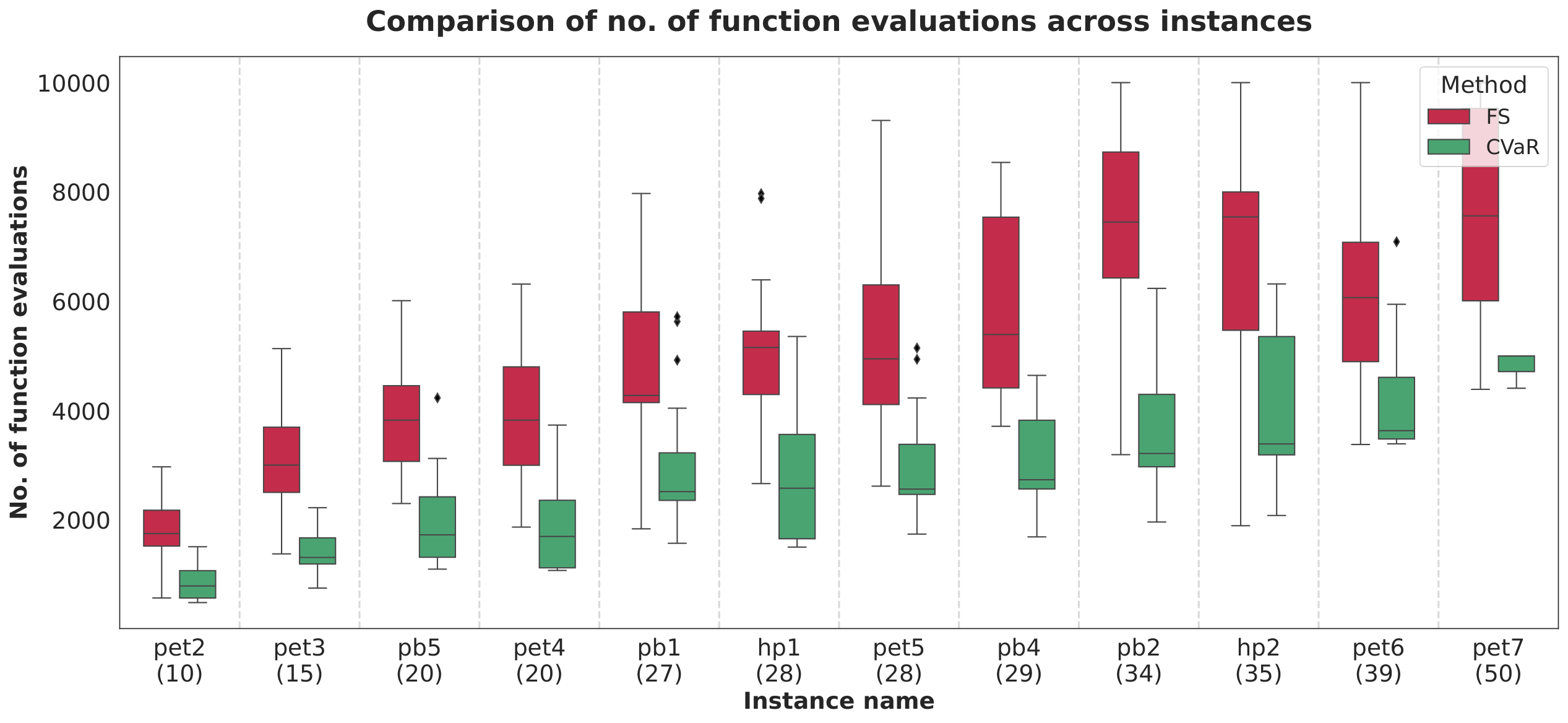
Section V (Results). Figure 2 (slack-vs-noslack) compares mean optimality gap Δ across all 12 instances. With finite sampling alone the custom penalty wins on 7/12 instances; with CVaR it wins on all 12, and every CVaR-custom run reaches feasibility (pb4 fails to find a feasible point at all under the slack formulation). Figure 3 (mdkp-optgap) plots box plots over 20 random initialisations; CVaR medians are consistently <0.1, and for the 50-qubit pet7 instance the median optimality gap reaches 7.6×10−3. Figure 4 (mdkp-opt-prob) makes the “curse of dimensionality” point: FS quasi-optimum probability px* decays with qubit count, but CVaR stabilises at ∼0.1 (exactly α), because once the quasi-optimum occupies α of the distribution CVaR saturates. Figure 5 (mdkp-nfev) shows CVaR needs fewer function evaluations to converge.
Implication: on a size-for-size comparison, a single-layer HEA + custom-penalty + CVaR beats the slack-QUBO + QAOA/VQE baseline established by the Monit benchmark. This is exactly the regime where Y2's quasi-binary encoding + hard mixer excels, but with a different tradeoff — no mixer design is needed, at the cost of amplifying the penalty range R.
Figures
Citations to Yuan's papers
Overlap with Y1–Y6
- Y2 (quasi-binary / hard-mixer / CVaR-QAOA for portfolio) — Strong methodological parallel. Y2 achieves feasibility by encoding + mixer design that traps the state inside the feasible subspace; this paper achieves a comparable effect by using a vanilla HEA plus a nonlinear step penalty evaluated via Monte-Carlo sampling. Both use CVaR for the same reason (noise-resilient, convergence-sharpening). A direct comparison of the two feasibility-enforcement philosophies on the same MDKP instances would be a clean paper.
- Y4 (Grover + ADMM cardinality-constrained BO) — Same problem class (constrained binary optimisation), different algorithmic primitive. Y4's ADMM with ε-approximation guarantees and O(√(C(n,k)/M)) rotations sits at the opposite end — exponential rigour, no variational handholding. This paper's finite-sampling trick does not guarantee convergence to the optimum but makes the variational route competitive on meaningful instance sizes.
- Y3 (QAOA DGMVP portfolio, layerwise + dual annealing) — Both papers emphasise that careful optimisation-landscape design is the main lever for NISQ-era utility. This paper's single-layer HEA + CVaR is in the same design philosophy as Y3's layerwise scheduling: keep the classical optimisation tractable, let sampling structure do the work.
- Y1 (warm-started QAOA) — Only loose overlap. This paper uses random initialisation; warm-starting the HEA parameters from the CVaR-optimised landscape of a smaller MDKP instance would be a natural extension.
Recommended action for Yuan
- Read in detail, then cite in the next portfolio/QAOA draft. This paper is the clearest recent articulation of “why keep slack variables if sampling gives you the penalty for free” and directly adjoins Y2's feasibility-preserving framework.
- Benchmark against Y2: run the authors' MDKP-pet7 instance (50 qubits) through the Y2 quasi-binary + hard-mixer pipeline and compare sample efficiency, penalty-factor sensitivity, and wall-clock on identical hardware. A head-to-head would be a strong section in a follow-up Y2 paper.
- Consider a joint warm-start extension: use Y1's measurement-based iteration to warm-start the single-layer HEA parameters of this method — might close the remaining FS/CVaR gap on the larger instances (pet5, pet7).