EQE-QAOA: An Equivalence-Preserving Qubit Efficient Framework for Combinatorial Optimization
Abstract
The limited number of qubits is a major bottleneck in Quantum Approximate Optimization Algorithm (QAOA) for large-scale combinatorial optimization in the Noisy Intermediate-Scale Quantum (NISQ) era. To make progress, existing techniques rely on qubit reduction at the cost of information loss, hence leading to degraded computational performance. As a remedy, we propose the Equivalence-preserving Qubit Efficient QAOA (EQE-QAOA), which significantly reduces the required number of qubits without degrading the performance of QAOA. By exploiting intrinsic symmetries and conserved quantities, we first demonstrate that the QAOA dynamics are strictly confined to an invariant subspace of the Hilbert space. We subsequently prove that the evolution within this subspace is exactly equivalent to that of the full-scale system, achieving the same optimal solution as the original QAOA. Moreover, to reduce the number of qubits, we propose an isometric mapping that re-encodes the subspace into a space relying on fewer qubits. Furthermore, we derive the applicability conditions of EQE-QAOA and show that it is broadly applicable to large-scale combinatorial optimization problems, excluding only unconstrained problems with completely independent variables. Numerical simulations based on Max-Cut instances validate that EQE-QAOA significantly reduces qubit requirements and computational resources, while preserving exact optimization performance.
Executive summary
EQE-QAOA constructs a qubit-efficient QAOA by identifying the commutant 𝔤′ of the dynamical Lie algebra generated by (iHC, iHM), extracting conserved quantities Q, decomposing the Hilbert space into invariant subspaces, and then constructing an isometric mapping V from a m-qubit register (with m = ⌈log₂ M⌉, M = dim of the active subspace) onto the original invariant subspace. Unlike lossy compact encodings or partition-based methods, the reduction is provably exact: state trajectory, expectation values, and bitstring probabilities all match the full-qubit QAOA. For Max-Cut on complete graphs Kₙ the scheme compresses from n down to mmin = ⌈log₂(n+1)⌉ qubits — an exponential reduction — while constrained Max-Cut with a Hamming-weight constraint Σxᵢ=k uses an XY mixer (a hard-constraint-preserving mixer in the same spirit as Y2's quasi-binary mixer). This is exactly the problem family Yuan has been working on in Y1–Y4, and the isometric-mapping idea is a close methodological cousin to Y2's quasi-binary encoding.
Main contribution
The paper's central object is the pair (𝔤, 𝔤′): the dynamical Lie algebra of the QAOA generators and its commutant. When 𝔤′ is non-trivial (i.e., not just ℂI), the Hamiltonians admit a shared block decomposition 𝓗 = ⊕α 𝓗α, the QAOA dynamics never leave the block containing |ψ₀⟩, and a minimum of m = ⌈log₂ M⌉ qubits suffices to simulate it. The authors package three results — Theorem 1 (state/observable/measurement equivalence between full and effective subspace dynamics), Lemma 2/Theorem 2 (the isometry V satisfies V†V = I and VV† = Πeff and intertwines the exponentials of HC/M with induced Hamiltonians on the reduced register), and Corollary 1 (the reduced QAOA reproduces the full QAOA bit-by-bit) — into a recipe that works whenever the problem is either constrained or admits a non-trivial permutation symmetry. Numerics confirm machine-precision equivalence (fidelity offset 10⁻¹⁵) and show up to 70% qubit reduction for symmetric graphs, with complete graphs showing the logarithmic scaling predicted in closed form.
Key theorems / lemmas / algorithms
- Lemma 1: If Π is an orthogonal projector satisfying [Π, HC] = 0 and [Π, HM] = 0, then [Π, U(γ, β)] = 0 for the full QAOA unitary.
- Theorem 1 (Equivalence): If |ψ₀⟩ ∈ 𝓗eff, the full-space evolved state equals the effective-subspace evolved state; for any observable O commuting with Πeff, expectation values coincide; and bitstring probabilities are identical (with Prfull(x) = 0 for |x⟩ ⊥ 𝓗eff).
- Lemma 2: The isometry V = Σk |φk⟩⟨φ̃k| satisfies V†V = Ieff and VV† = Πeff.
- Theorem 2 (Intertwining): e−iγHCV = V e−iγH̃Ceff and e−iβHMV = V e−iβH̃Meff, so U(γ,β)V = VŨ(γ,β) as a layerwise identity.
- Corollary 1: The reduced m-qubit QAOA reproduces the full QAOA trajectory exactly for compatible initial states.
- Theorem 3: m = ⌈log₂ M⌉ qubits are necessary and sufficient to represent an M-dimensional invariant subspace losslessly.
- Corollary 2: If M < 2ⁿ then m ≤ n — reduction is always possible when the commutant is non-trivial.
- Applicability criterion (Table III): the problem is irreducible iff 𝔤′ = ℂI (unconstrained, independent variables); it is reducible whenever constraints or permutation symmetries ( |𝒮f| > 1 ) yield a Q ∈ 𝔤′ ∖ ℂI.
Detailed walkthrough
The technical core lives in §III. Starting from the QAOA generators 𝔤 = Lie(iHC, iHM), the authors invoke the standard fact that searching the commutant 𝔤′ reduces to finding operators that commute with both generators. They expand Q in the n-qubit Pauli basis Q = ΣP qP P and solve the joint commutator equations to enumerate conserved charges. Each eigenspace of Q is an invariant block, and the projector Πeff onto the block containing |ψ₀⟩ commutes with both Hamiltonians by construction, so it commutes with the full QAOA unitary (Lemma 1). Theorem 1 then chains this into three equivalence statements — states, observables, and probabilities — each proved in Appendix B by straightforward use of [Π, U] = 0 plus the cyclicity of the trace.
§III.C is where the qubit count actually drops. The invariant subspace has some dimension M ≤ 2ⁿ. Any log-table encoding that injects an orthonormal basis {|φ̃k⟩} on m = ⌈log₂ M⌉ qubits into {|φk⟩} ⊂ 𝓗eff gives an isometry V with V†V = I and VV† = Πeff (Lemma 2). The induced Hamiltonians H̃C/Meff = V†HC/MV on the m-qubit register are no longer local Pauli sums in general — they are obtained by rewriting the action of the original Hamiltonian on the selected M basis vectors — but Theorem 2 guarantees the key intertwining identity e−iγHCV = V e−iγH̃Ceff layer-by-layer, so the full P-layer QAOA circuit compiled on m qubits produces the same measurement distribution as the n-qubit original. This is the lossless statement that distinguishes EQE-QAOA from Tan et al.'s minimal encoding and from problem-partitioning/qubit-reuse methods (Table I on p. 2 lists seven qualitative features and the proposed method is the only one that preserves optimization accuracy).
§IV gives applicability criteria. For unconstrained problems with fully independent variables, [A, HC] = [A, HM] = 0 ⇒ A ∈ ℂI; no symmetry, no reduction. For constrained or permutation-symmetric problems, a non-trivial Q exists and reduction is guaranteed. For Kn Max-Cut (full permutation symmetry), M = n+1 so mmin = ⌈log₂(n+1)⌉, yielding an exponential compression ratio η = 2ⁿ/(n+1). Runtime of one classical-simulation layer drops from O(2ⁿ) to O(n).
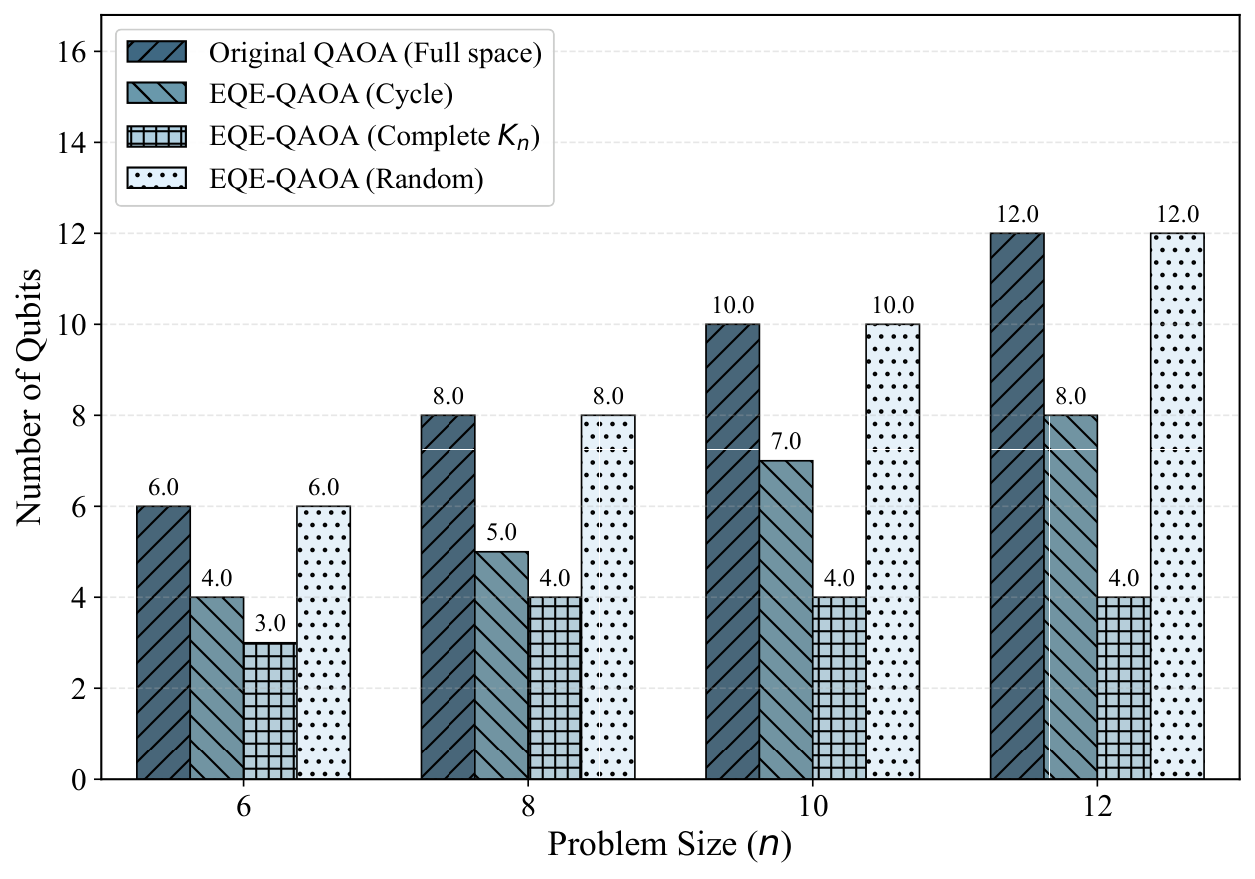
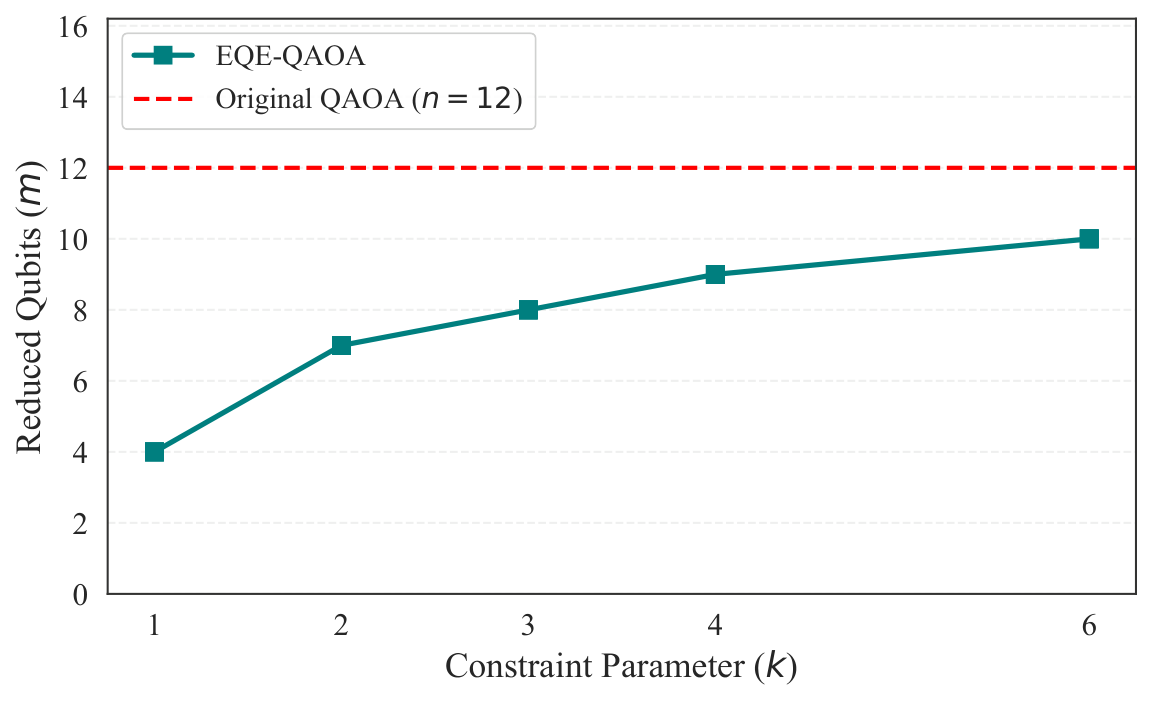
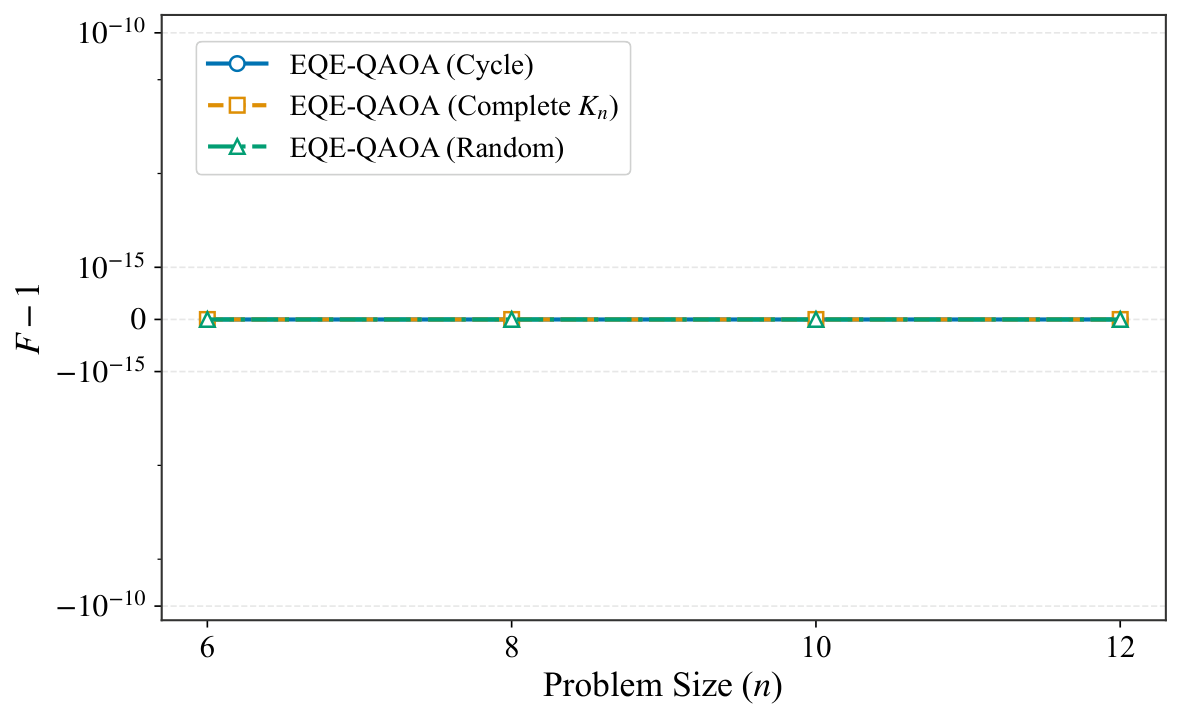
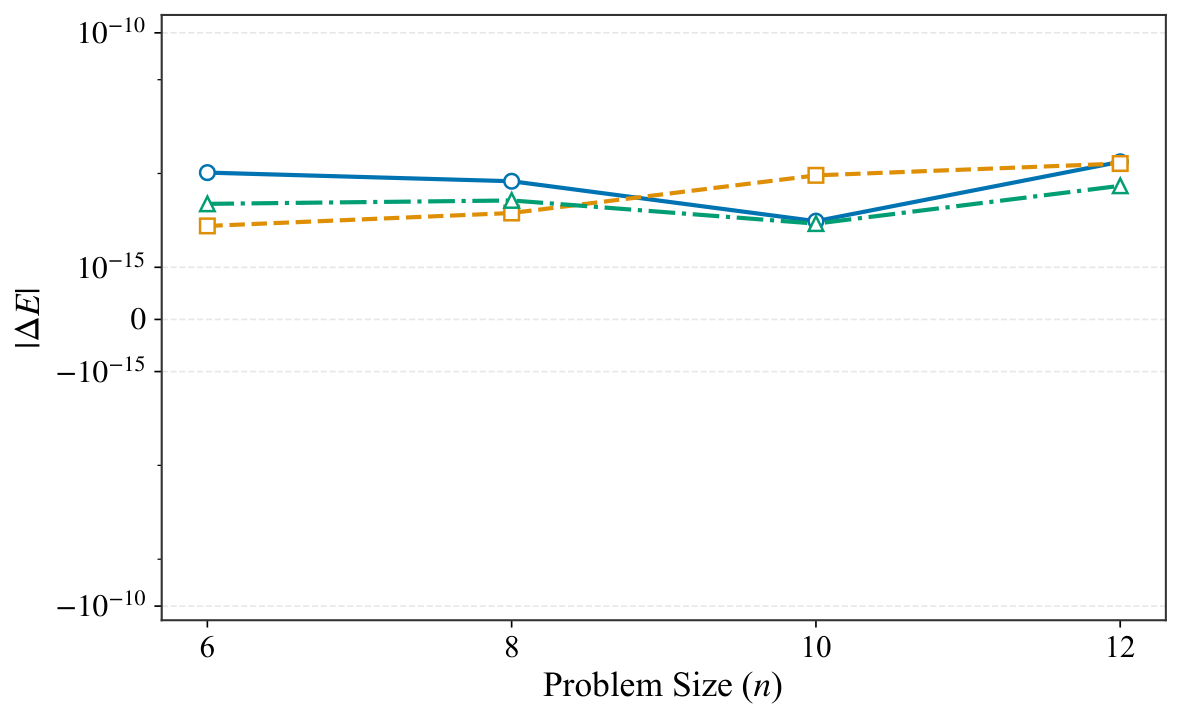
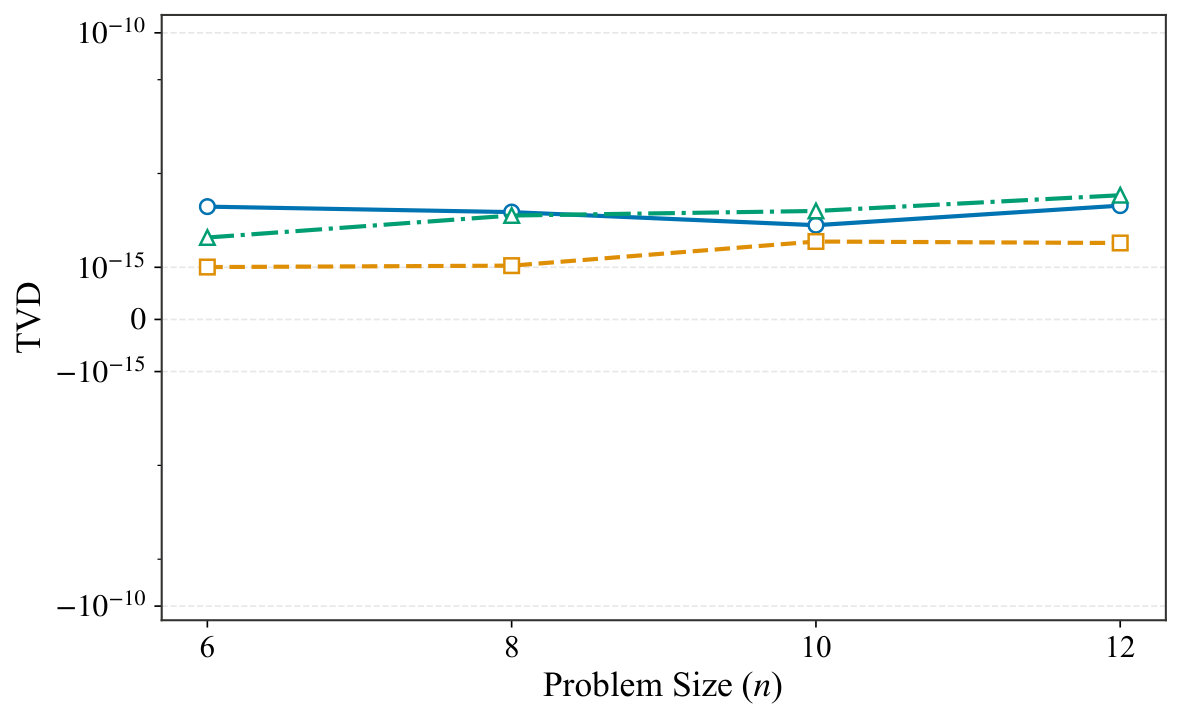
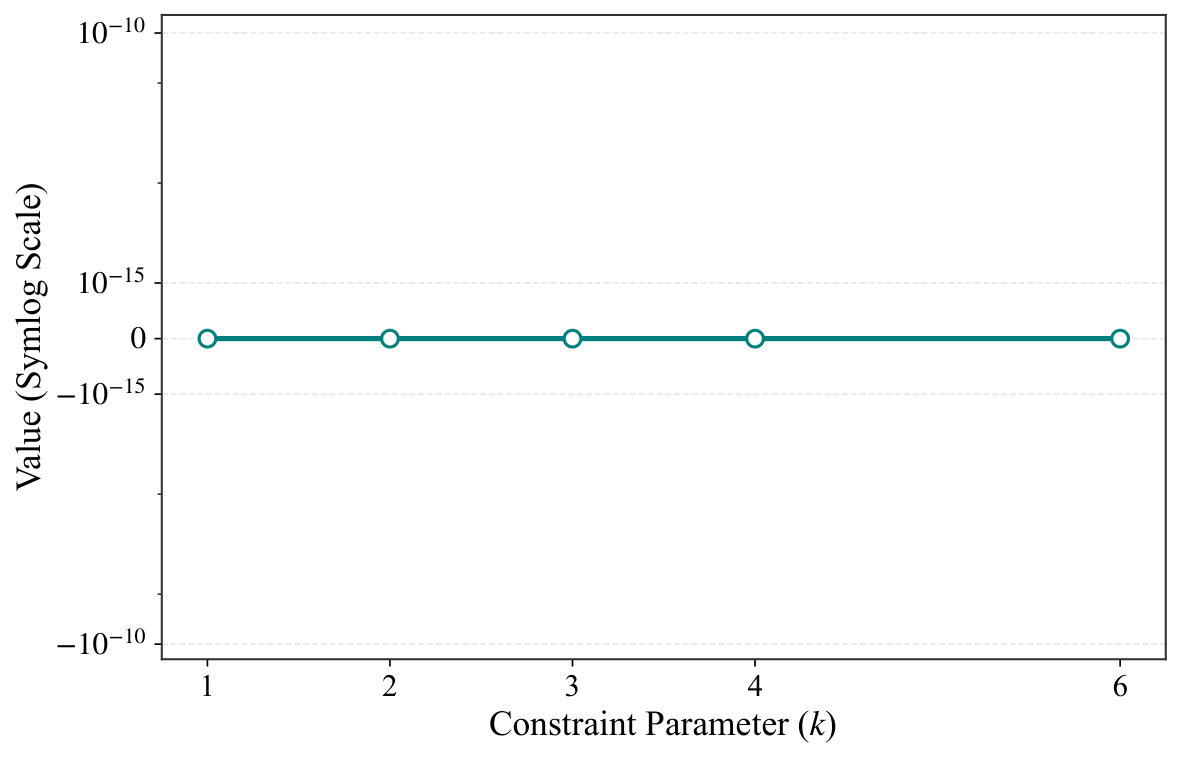
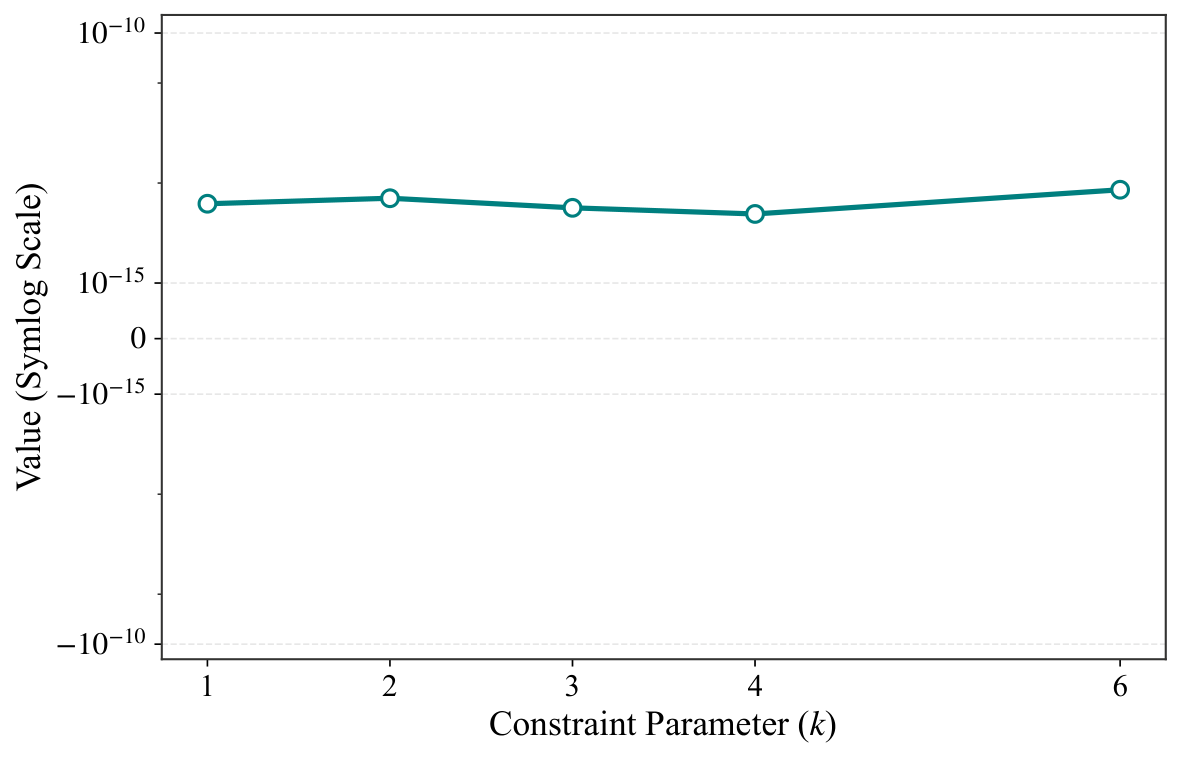
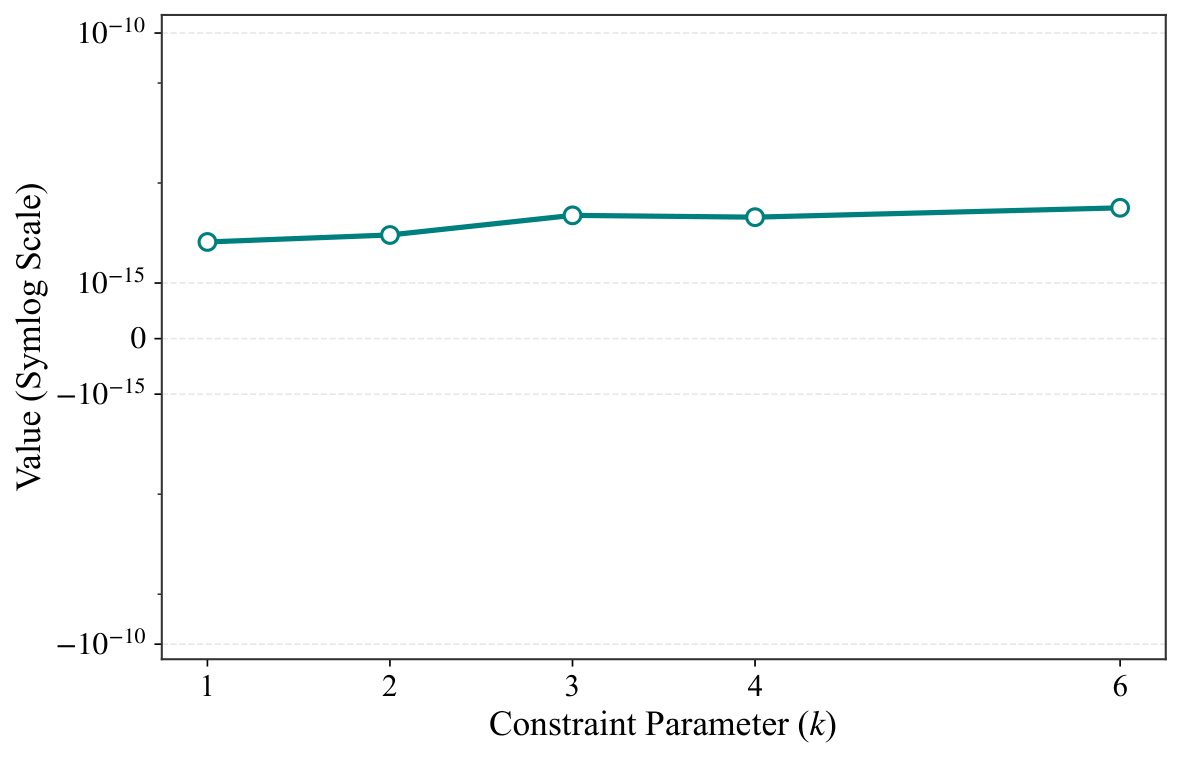
§V is numerics. The experiments use Qiskit Aer statevector simulation on an i7-13700K with 16 GB RAM, P = 2 QAOA layers, and five random parameter seeds per instance. Two families are tested: (a) unconstrained Max-Cut on cycles, complete graphs, and Erdős–Rényi random graphs for n ∈ {6, 8, 10, 12}, with the standard X-mixer; and (b) constrained Max-Cut on Erdős–Rényi graphs with n = 12 and Hamming-weight constraint Σxᵢ = k for k ∈ {1, 2, 3, 4, 6}, using an XY mixer that preserves the Hamming weight — i.e., a hard-constraint-preserving mixer, which is precisely the idea Yuan pushed in Y2. Figures 1–2 show the qubit reduction: complete graphs collapse to essentially 3–4 qubits regardless of n; cycle graphs compress moderately; Erdős–Rényi barely compresses (as the criterion predicts). Figure 3 verifies equivalence to machine precision (F − 1 ≈ 10⁻¹⁵, |ΔE| ≈ 10⁻¹⁴) across all families, and Figure 4 repeats the check under Hamming-weight constraints with identical precision. Figure 5 logs memory footprints — the reduced simulation needs only 2m-dimensional state vectors, letting the authors simulate n = 12 graphs with only 4 qubits of classical memory overhead.
§V.B benchmarks against three prior qubit-efficient methods: minimal encoding (Tan et al.), DC-QAOA (Li et al.), and qubit-reuse compilation (DeCross et al.). Only minimal encoding compresses more aggressively, but its accuracy degrades substantially with problem size; DC-QAOA's accuracy also drops off. EQE-QAOA wins on |ΔE| and approximation ratio across all tested sizes, at a competitive qubit count. The authors frame this as the promised "lossless" frontier: strict equivalence to the original QAOA's best achievable performance, at a qubit count dictated by the problem's symmetry structure.
The limitations are honest. For Erdős–Rényi random graphs at p = 0.5, no structural symmetry exists, so EQE-QAOA offers essentially no compression — this is the right behavior but limits the method to structured problems. The induced Hamiltonians H̃eff are non-local in general, so compiling them into native two-qubit gates is not addressed; the paper computes them as matrices and evolves by matrix exponential. This is adequate for the classical simulation benchmarks presented but leaves open the question of whether the savings survive compilation onto real hardware.
Figures
Citations to Yuan's papers
reference.bib returned only an unrelated "Xiao Yuan" co-authoring the Cerezo et al. variational-quantum-algorithms review, which is not Haomu Yuan.)
Overlap with Y1–Y6
Y2 — Quasi-binary QAOA (arXiv:2304.06915) — STRONG method overlap
Y2 proposed a quasi-binary encoding that uses ≈2⌈log₂(U − L + 1)⌉ qubits per integer variable and a hard-constraint-preserving mixer (no penalty terms). EQE-QAOA's m = ⌈log₂ M⌉ reduction is the generalized version of the same idea — whenever the feasible subspace has dimension M, log M qubits suffice, with the isometry playing the role of Y2's quasi-binary map. Furthermore, EQE-QAOA's constrained-Max-Cut experiments use an XY mixer to enforce a Hamming-weight constraint: structurally identical to Y2's constraint-preserving mixer. Y2 and EQE-QAOA should be read as siblings; EQE-QAOA supplies the Lie-algebraic recipe for picking a feasible encoding, while Y2 gives a concrete encoding tuned for integer-valued decision variables.
Y1 — Iterative warm-started QAOA (arXiv:2502.09704) — Method-adjacent
Same QAOA scaffolding (layerwise unitary, standard X or XY mixer, Max-Cut benchmarks), different axis of improvement. Y1 iteratively tightens a warm-start state to boost the approximation ratio and DGMVP scaling; EQE-QAOA shrinks the register but leaves the approximation ratio untouched (exact equivalence to the original QAOA). The two techniques compose — one could perform Y1's measurement-based warm-start in the reduced m-qubit register rather than the n-qubit one, which is an obvious and probably publishable follow-up.
Y3 — QAOA for DGMVP portfolio (arXiv:2410.16265) — Scope overlap
Y3's portfolio problem carries a cardinality constraint (fixed number of chosen assets) — the same constraint class EQE-QAOA targets in its second experiment. Y3 found that thermal relaxation noise precludes quantum advantage for end-to-end portfolio QAOA; EQE-QAOA's qubit savings would directly reduce the circuit width and total gate count, pushing the thermal-relaxation crossover point. A direct comparison on DGMVP portfolios would strengthen Y3's conclusions about where quantum advantage becomes feasible.
Y4 — Grover + ADMM for cardinality-constrained BO (arXiv:2603.14744) — Scope overlap
Y4 and EQE-QAOA attack the same target problem family (cardinality-constrained binary optimization) through orthogonal means: Y4 via Grover search over the feasible C(n,k) space with O(√(C(n,k)/M)) rotations, EQE-QAOA via QAOA on a log₂ C(n,k)-qubit register. A side-by-side comparison on the same Hamming-weight-constrained instances would clarify when each method wins in the NISQ vs fault-tolerant regime.
Y5, Y6 — No meaningful overlap.
Recommended action for Yuan
- Cite in the next QAOA-encoding paper. EQE-QAOA is almost certainly the most direct methodological peer of Y2 published in 2026 so far; any follow-up to Y2 must discuss it explicitly. The framing point is that Y2 handled integer-valued decision variables with an explicit binary-digit construction, while EQE-QAOA gives a symmetry-based recipe for constructing an isometry whenever the commutant is non-trivial.
- Compose with Y1's warm-start. Perform measurement-based warm-starting inside the reduced m-qubit register. Because the isometry V is an exact intertwiner, Y1's iterative updates pull back to the full space unchanged. This is a clean one-paragraph extension that is likely experimentally tractable on NISQ hardware at n ≈ 20.
- Benchmark against Y3 and Y4. Run EQE-QAOA on the DGMVP-portfolio instances used in Y3 and on the Hamming-weight-constrained Max-Cut instances used in Y4, holding noise models fixed. The quantitative question: does the log₂ M qubit reduction move the thermal-relaxation crossover from Y3 far enough to matter at realistic portfolio sizes (n ≥ 20)?
- Optional: email the authors. Western University + Southampton; Hanzo is a well-known comms theorist new to quant-ph. A short note pointing to Y2 would be appropriate — the lack of a citation suggests they didn't see it, and a reciprocal acknowledgment in their v2 is plausible.